 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnDeFog: Online Decision Transformer under Frame Dropping
Jun 18, 2026In challenging real-world reinforcement learning applications, communication delays or sensor failures often cause frame dropping, in which the agent cannot receive the dropped states and associated rewards. To address the performance degradation caused by frame dropping, the Decision Transformer under Random Frame Dropping (DeFog) was developed by incorporating additional mechanisms into the decision transformer to tackle frame dropping. Although DeFog can mitigate performance degradation in frame-dropping environments, since DeFog is an offline learning method, it struggles to effectively generalize to novel states not adequately represented in the training dataset. In this study, we propose OnDeFog, which integrates the mechanisms in DeFog with the online decision transformer (ODT), an online reinforcement learning method that learns policies through direct environmental interaction. Comprehensive experimental evaluation demonstrates that our proposed OnDeFog achieves superior performance compared to ODT in environments characterized by high dropping frame rate and outperforms DeFog on datasets containing a large amount of low-reward data.
Neural Architecture Search for Improving Latency-Accuracy Trade-off in Split Computing
Aug 30, 2022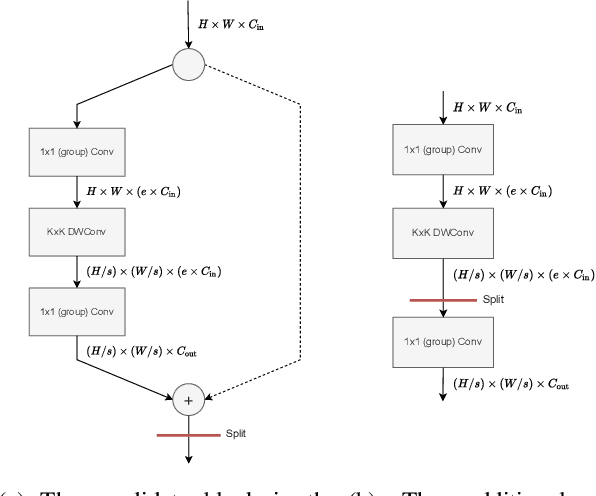
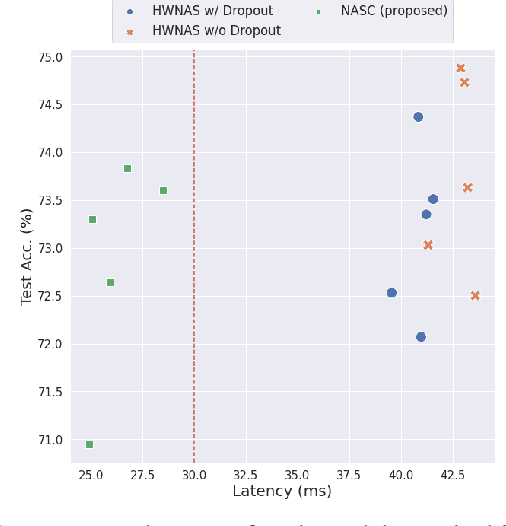
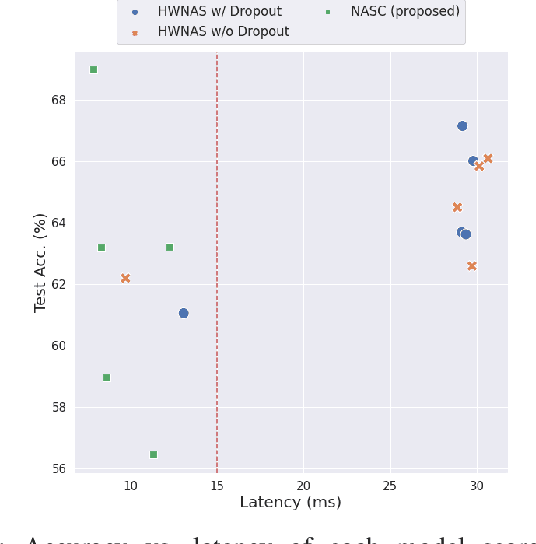
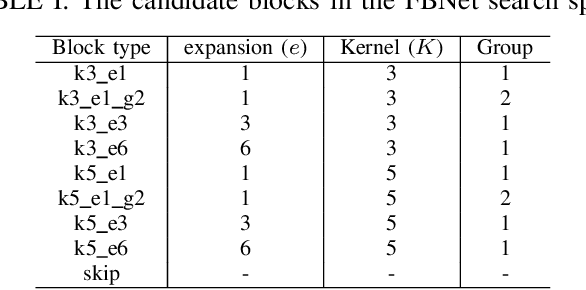
This paper proposes a neural architecture search (NAS) method for split computing. Split computing is an emerging machine-learning inference technique that addresses the privacy and latency challenges of deploying deep learning in IoT systems. In split computing, neural network models are separated and cooperatively processed using edge servers and IoT devices via networks. Thus, the architecture of the neural network model significantly impacts the communication payload size, model accuracy, and computational load. In this paper, we address the challenge of optimizing neural network architecture for split computing. To this end, we proposed NASC, which jointly explores optimal model architecture and a split point to achieve higher accuracy while meeting latency requirements (i.e., smaller total latency of computation and communication than a certain threshold). NASC employs a one-shot NAS that does not require repeating model training for a computationally efficient architecture search. Our performance evaluation using hardware (HW)-NAS-Bench of benchmark data demonstrates that the proposed NASC can improve the ``communication latency and model accuracy" trade-off, i.e., reduce the latency by approximately 40-60% from the baseline, with slight accuracy degradation.