 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Object Detection with Fully Cross-Transformer
Mar 28, 2022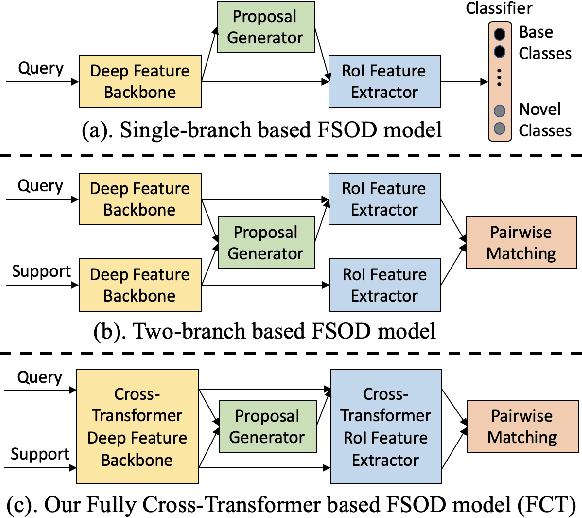
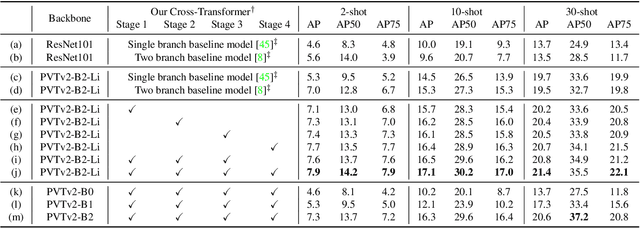
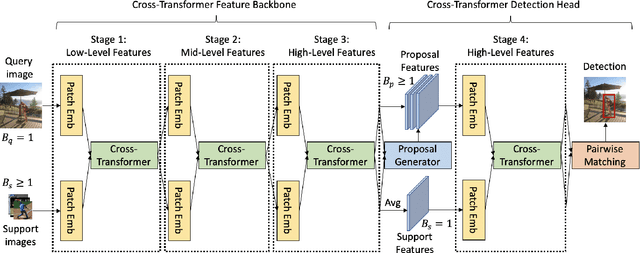
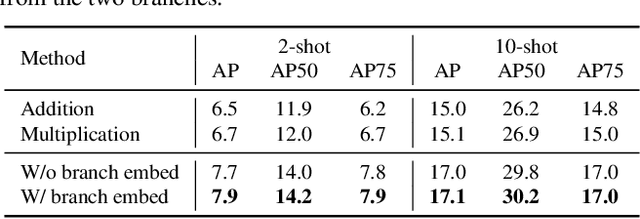
Few-shot object detection (FSOD), with the aim to detect novel objects using very few training examples, has recently attracted great research interest in the community. Metric-learning based methods have been demonstrated to be effective for this task using a two-branch based siamese network, and calculate the similarity between image regions and few-shot examples for detection. However, in previous works, the interaction between the two branches is only restricted in the detection head, while leaving the remaining hundreds of layers for separate feature extraction. Inspired by the recent work on vision transformers and vision-language transformers, we propose a novel Fully Cross-Transformer based model (FCT) for FSOD by incorporating cross-transformer into both the feature backbone and detection head. The asymmetric-batched cross-attention is proposed to aggregate the key information from the two branches with different batch sizes. Our model can improve the few-shot similarity learning between the two branches by introducing the multi-level interactions. Comprehensive experiments on both PASCAL VOC and MSCOCO FSOD benchmarks demonstrate the effectiveness of our model.
Query Adaptive Few-Shot Object Detection with Heterogeneous Graph Convolutional Networks
Dec 17, 2021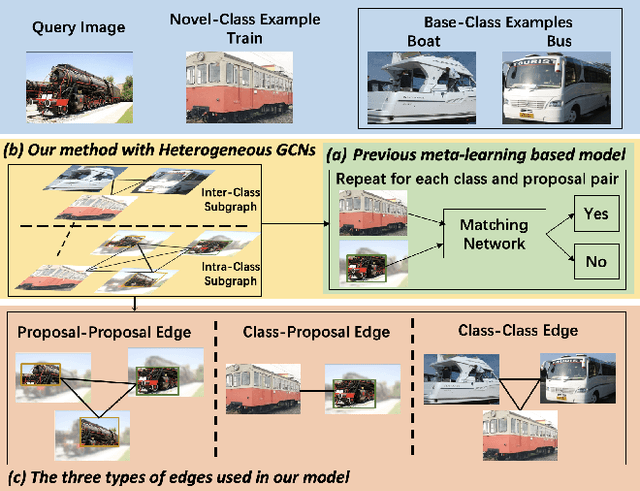
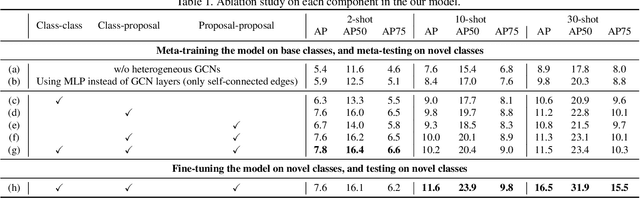
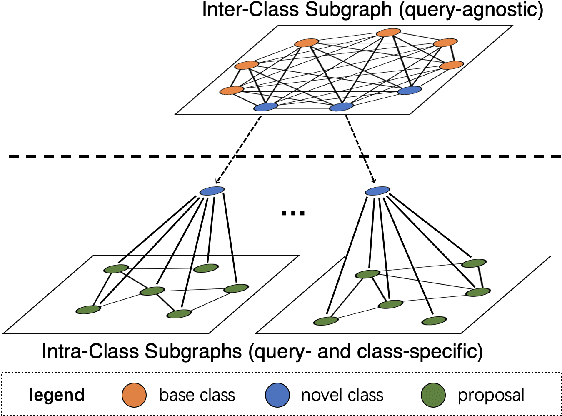
Few-shot object detection (FSOD) aims to detect never-seen objects using few examples. This field sees recent improvement owing to the meta-learning techniques by learning how to match between the query image and few-shot class examples, such that the learned model can generalize to few-shot novel classes. However, currently, most of the meta-learning-based methods perform pairwise matching between query image regions (usually proposals) and novel classes separately, therefore failing to take into account multiple relationships among them. In this paper, we propose a novel FSOD model using heterogeneous graph convolutional networks. Through efficient message passing among all the proposal and class nodes with three different types of edges, we could obtain context-aware proposal features and query-adaptive, multiclass-enhanced prototype representations for each class, which could help promote the pairwise matching and improve final FSOD accuracy. Extensive experimental results show that our proposed model, denoted as QA-FewDet, outperforms the current state-of-the-art approaches on the PASCAL VOC and MSCOCO FSOD benchmarks under different shots and evaluation metrics.
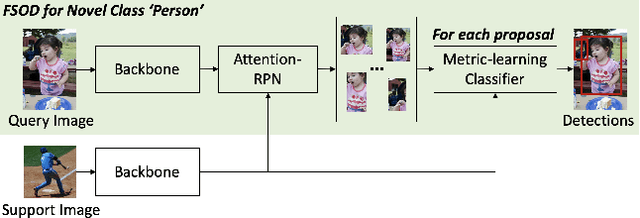
Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment
Apr 15, 2021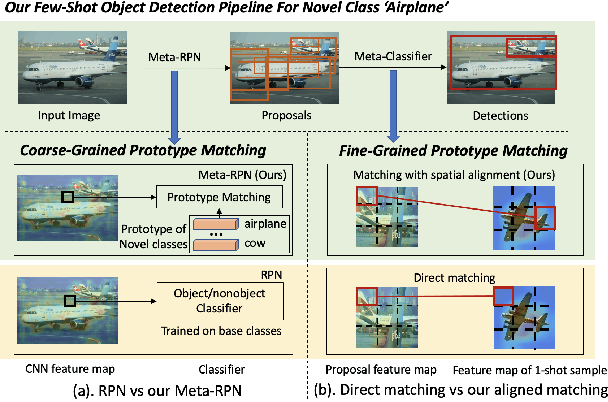
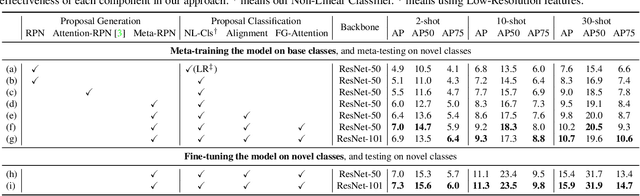
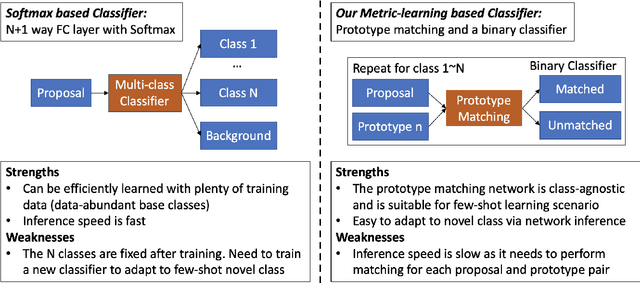
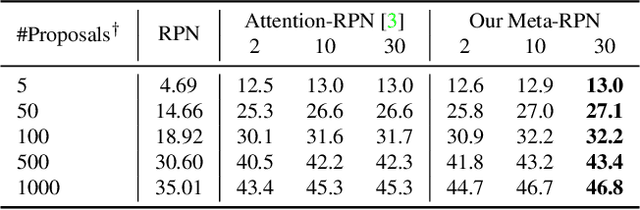
Few-shot object detection (FSOD) aims to detect objects using only few examples. It's critically needed for many practical applications but so far remains challenging. We propose a meta-learning based few-shot object detection method by transferring meta-knowledge learned from data-abundant base classes to data-scarce novel classes. Our method incorporates a coarse-to-fine approach into the proposal based object detection framework and integrates prototype based classifiers into both the proposal generation and classification stages. To improve proposal generation for few-shot novel classes, we propose to learn a lightweight matching network to measure the similarity between each spatial position in the query image feature map and spatially-pooled class features, instead of the traditional object/nonobject classifier, thus generating category-specific proposals and improving proposal recall for novel classes. To address the spatial misalignment between generated proposals and few-shot class examples, we propose a novel attentive feature alignment method, thus improving the performance of few-shot object detection. Meanwhile we jointly learn a Faster R-CNN detection head for base classes. Extensive experiments conducted on multiple FSOD benchmarks show our proposed approach achieves state of the art results under (incremental) few-shot learning settings.
Task-Adaptive Negative Class Envision for Few-Shot Open-Set Recognition
Dec 24, 2020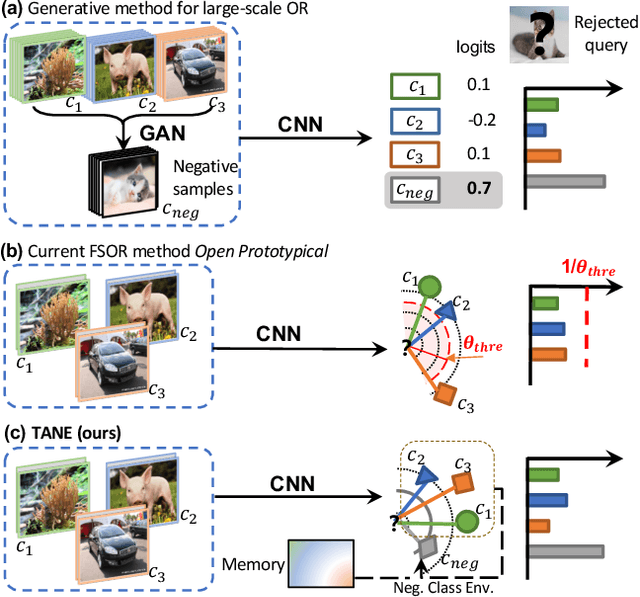
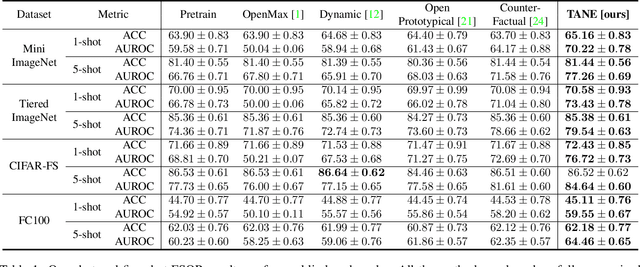
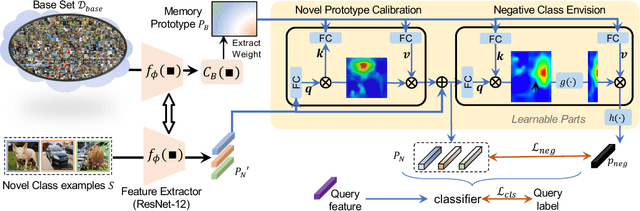
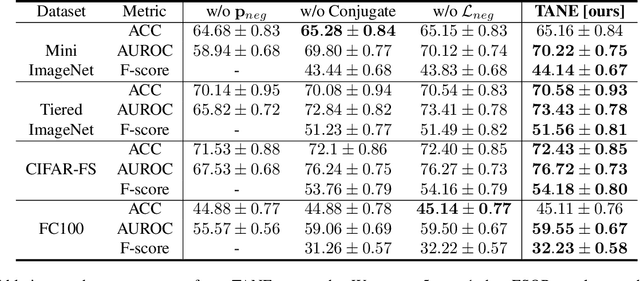
Recent works seek to endow recognition systems with the ability to handle the open world. Few shot learning aims for fast learning of new classes from limited examples, while open-set recognition considers unknown negative class from the open world. In this paper, we study the problem of few-shot open-set recognition (FSOR), which learns a recognition system robust to queries from new sources with few examples and from unknown open sources. To achieve that, we mimic human capability of envisioning new concepts from prior knowledge, and propose a novel task-adaptive negative class envision method (TANE) to model the open world. Essentially we use an external memory to estimate a negative class representation. Moreover, we introduce a novel conjugate episode training strategy that strengthens the learning process. Extensive experiments on four public benchmarks show that our approach significantly improves the state-of-the-art performance on few-shot open-set recognition. Besides, we extend our method to generalized few-shot open-set recognition (GFSOR), where we also achieve performance gains on MiniImageNet.
Flow-Distilled IP Two-Stream Networks for Compressed Video Action Recognition
Dec 12, 2019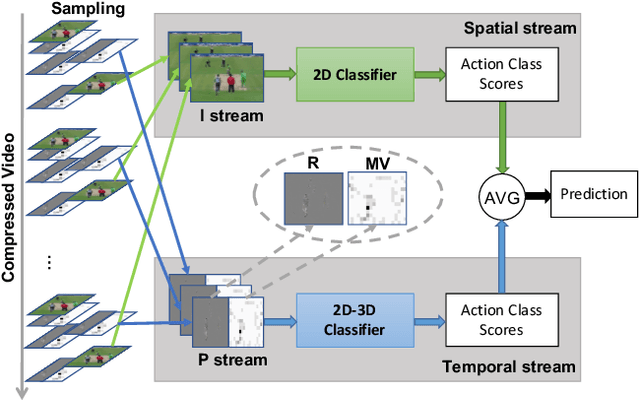
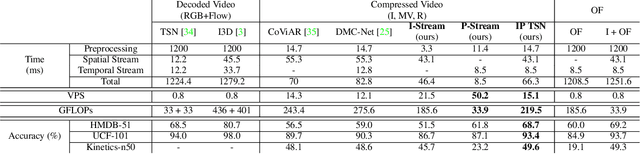
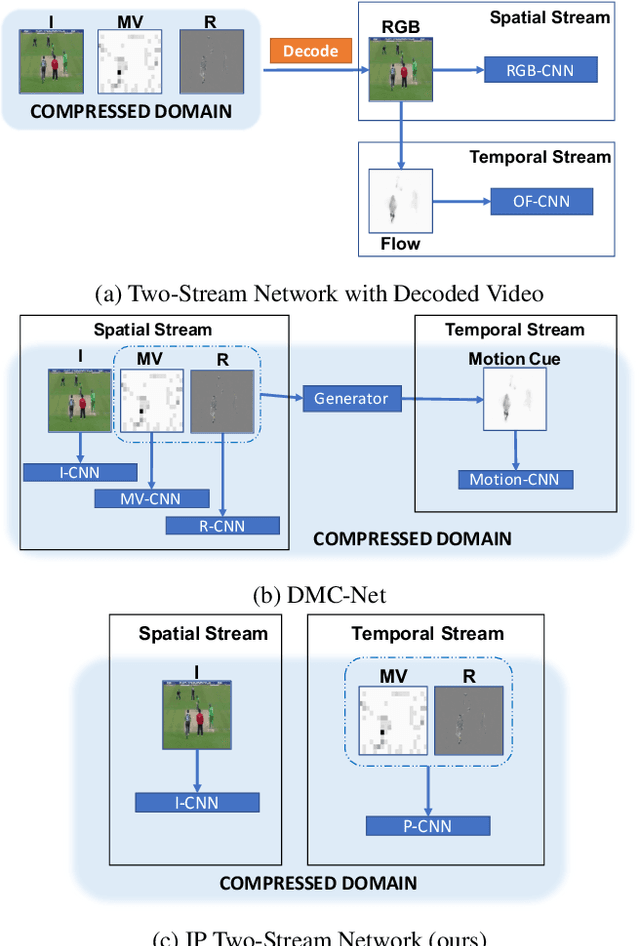
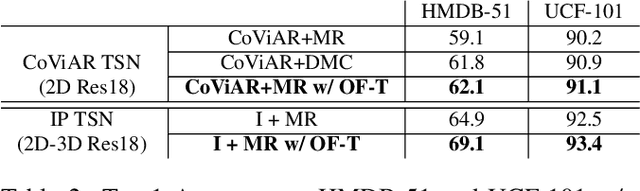
Two-stream networks have achieved great success in video recognition. A two-stream network combines a spatial stream of RGB frames and a temporal stream of Optical Flow to make predictions. However, the temporal redundancy of RGB frames as well as the high-cost of optical flow computation creates challenges for both the performance and efficiency. Recent works instead use modern compressed video modalities as an alternative to the RGB spatial stream and improve the inference speed by orders of magnitudes. Previous works create one stream for each modality which are combined with an additional temporal stream through late fusion. This is redundant since some modalities like motion vectors already contain temporal information. Based on this observation, we propose a compressed domain two-stream network IP TSN for compressed video recognition, where the two streams are represented by the two types of frames (I and P frames) in compressed videos, without needing a separate temporal stream. With this goal, we propose to fully exploit the motion information of P-stream through generalized distillation from optical flow, which largely improves the efficiency and accuracy. Our P-stream runs 60 times faster than using optical flow while achieving higher accuracy. Our full IP TSN, evaluated over public action recognition benchmarks (UCF101, HMDB51 and a subset of Kinetics), outperforms other compressed domain methods by large margins while improving the total inference speed by 20%.