 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning an AI Health Coach and Studying its Utility in Promoting Regular Aerobic Exercise
Oct 10, 2019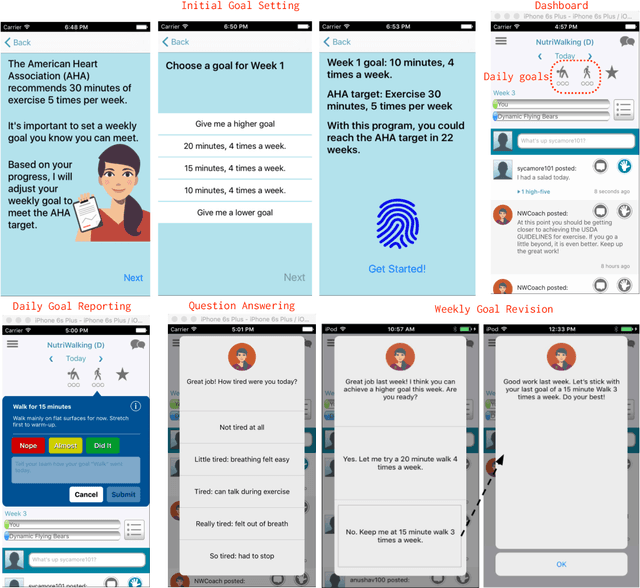
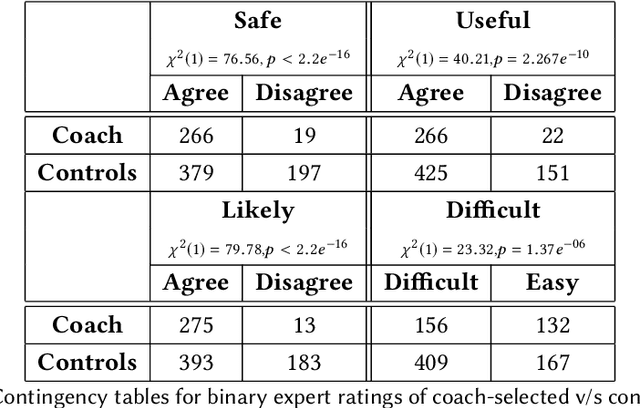
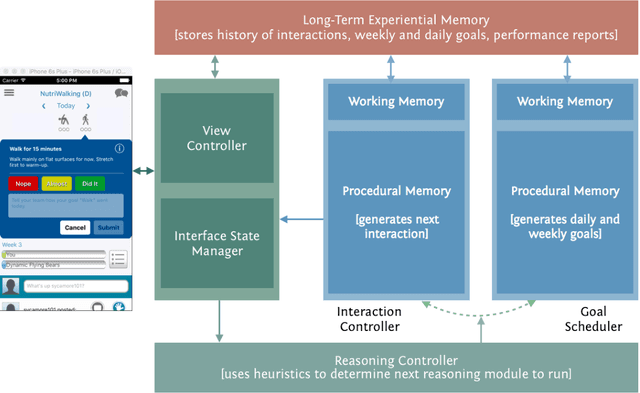
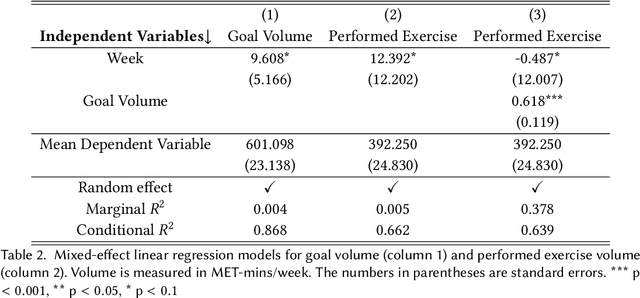
Our research aims to develop interactive, social agents that can coach people to learn new tasks, skills, and habits. In this paper, we focus on coaching sedentary, overweight individuals (i.e., trainees) to exercise regularly. We employ adaptive goal setting in which the intelligent health coach generates, tracks, and revises personalized exercise goals for a trainee. The goals become incrementally more difficult as the trainee progresses through the training program. Our approach is model-based - the coach maintains a parameterized model of the trainee's aerobic capability that drives its expectation of the trainee's performance. The model is continually revised based on trainee-coach interactions. The coach is embodied in a smartphone application, NutriWalking, which serves as a medium for coach-trainee interaction. We adopt a task-centric evaluation approach for studying the utility of the proposed algorithm in promoting regular aerobic exercise. We show that our approach can adapt the trainee program not only to several trainees with different capabilities, but also to how a trainee's capability improves as they begin to exercise more. Experts rate the goals selected by the coach better than other plausible goals, demonstrating that our approach is consistent with clinical recommendations. Further, in a 6-week observational study with sedentary participants, we show that the proposed approach helps increase exercise volume performed each week.
Acceptable Planning: Influencing Individual Behavior to Reduce Transportation Energy Expenditure of a City
Sep 23, 2019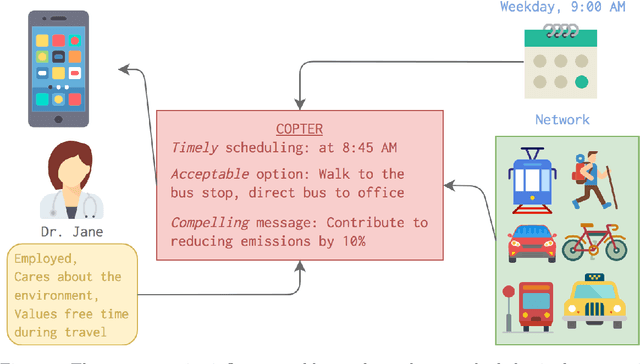
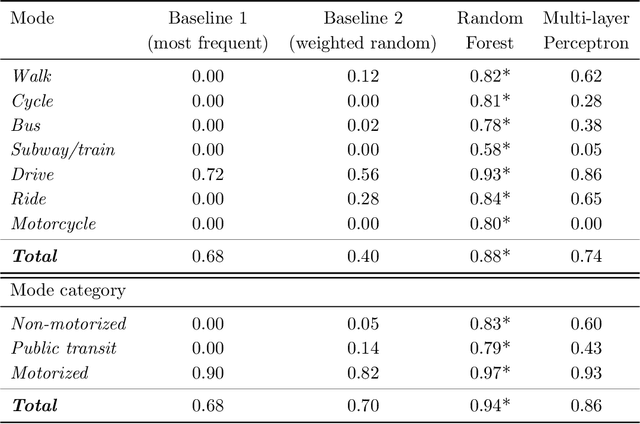
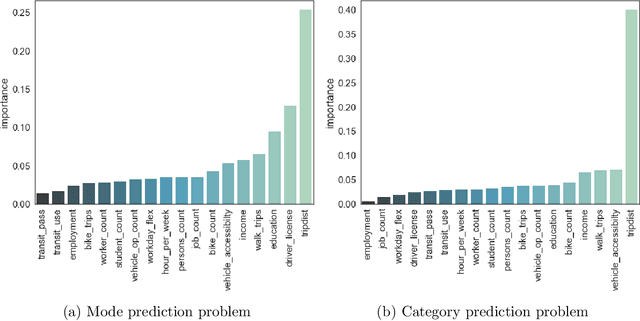
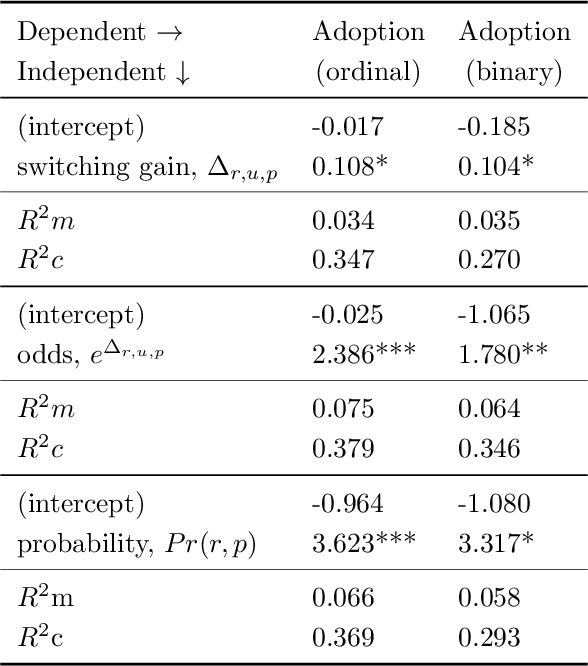
Our research aims at developing intelligent systems to reduce the transportation-related energy expenditure of a large city by influencing individual behavior. We introduce COPTER - an intelligent travel assistant that evaluates multi-modal travel alternatives to find a plan that is acceptable to a person given their context and preferences. We propose a formulation for acceptable planning that brings together ideas from AI, machine learning, and economics. This formulation has been incorporated in COPTER that produces acceptable plans in real-time. We adopt a novel empirical evaluation framework that combines human decision data with a high fidelity multi-modal transportation simulation to demonstrate a 4\% energy reduction and 20\% delay reduction in a realistic deployment scenario in Los Angeles, California, USA.
A Computational Model for Situated Task Learning with Interactive Instruction
Apr 23, 2016
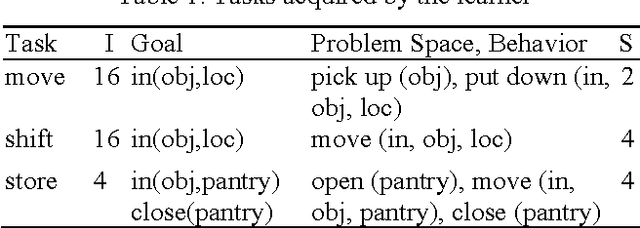
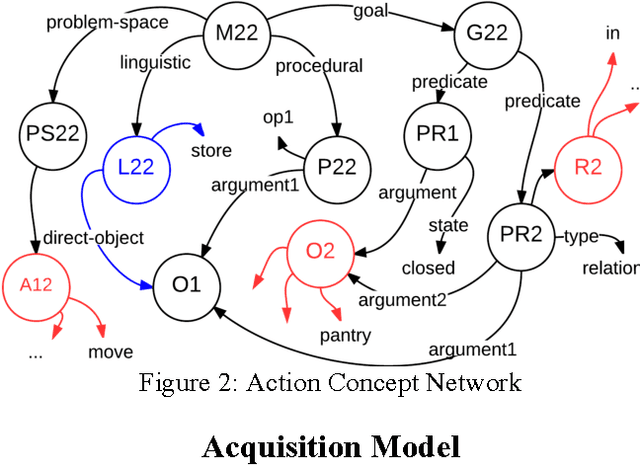
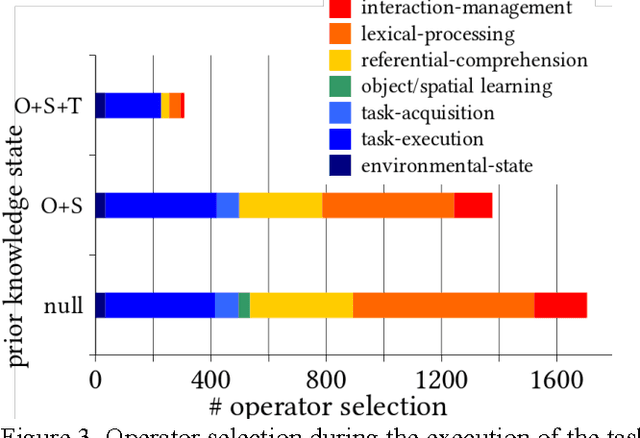
Learning novel tasks is a complex cognitive activity requiring the learner to acquire diverse declarative and procedural knowledge. Prior ACT-R models of acquiring task knowledge from instruction focused on learning procedural knowledge from declarative instructions encoded in semantic memory. In this paper, we identify the requirements for designing compu- tational models that learn task knowledge from situated task- oriented interactions with an expert and then describe and evaluate a model of learning from situated interactive instruc- tion that is implemented in the Soar cognitive architecture.
Towards an Indexical Model of Situated Language Comprehension for Cognitive Agents in Physical Worlds
Apr 09, 2016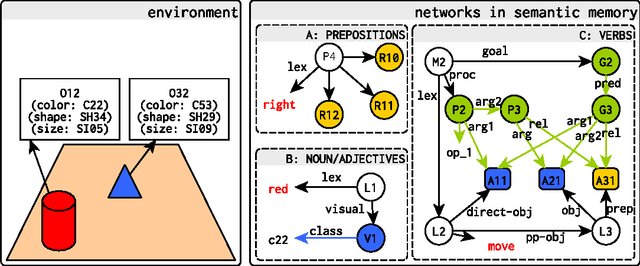

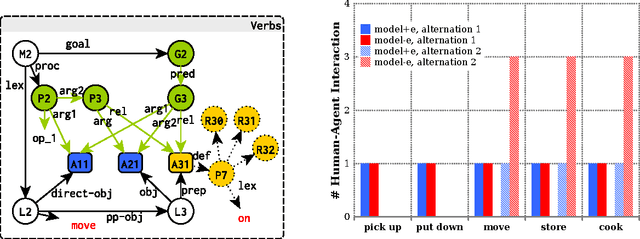
We propose a computational model of situated language comprehension based on the Indexical Hypothesis that generates meaning representations by translating amodal linguistic symbols to modal representations of beliefs, knowledge, and experience external to the linguistic system. This Indexical Model incorporates multiple information sources, including perceptions, domain knowledge, and short-term and long-term experiences during comprehension. We show that exploiting diverse information sources can alleviate ambiguities that arise from contextual use of underspecific referring expressions and unexpressed argument alternations of verbs. The model is being used to support linguistic interactions in Rosie, an agent implemented in Soar that learns from instruction.
Relational Reinforcement Learning in Infinite Mario
Feb 28, 2012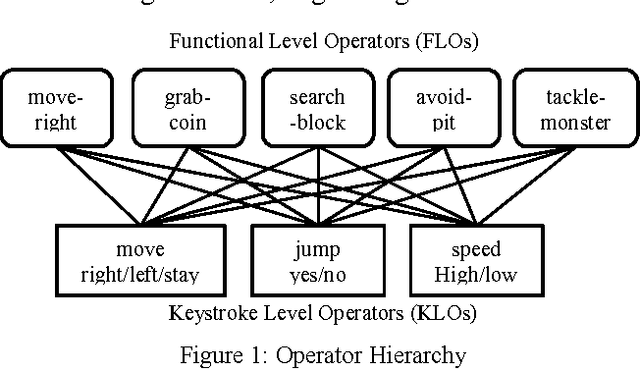

Relational representations in reinforcement learning allow for the use of structural information like the presence of objects and relationships between them in the description of value functions. Through this paper, we show that such representations allow for the inclusion of background knowledge that qualitatively describes a state and can be used to design agents that demonstrate learning behavior in domains with large state and actions spaces such as computer games.