 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRequirements for Aligned, Dynamic Resolution of Conflicts in Operational Constraints
Nov 18, 2025Deployed, autonomous AI systems must often evaluate multiple plausible courses of action (extended sequences of behavior) in novel or under-specified contexts. Despite extensive training, these systems will inevitably encounter scenarios where no available course of action fully satisfies all operational constraints (e.g., operating procedures, rules, laws, norms, and goals). To achieve goals in accordance with human expectations and values, agents must go beyond their trained policies and instead construct, evaluate, and justify candidate courses of action. These processes require contextual "knowledge" that may lie outside prior (policy) training. This paper characterizes requirements for agent decision making in these contexts. It also identifies the types of knowledge agents require to make decisions robust to agent goals and aligned with human expectations. Drawing on both analysis and empirical case studies, we examine how agents need to integrate normative, pragmatic, and situational understanding to select and then to pursue more aligned courses of action in complex, real-world environments.
Mapping Neural Theories of Consciousness onto the Common Model of Cognition
Jun 13, 2025
A beginning is made at mapping four neural theories of consciousness onto the Common Model of Cognition. This highlights how the four jointly depend on recurrent local modules plus a cognitive cycle operating on a global working memory with complex states, and reveals how an existing integrative view of consciousness from a neural perspective aligns with the Com-mon Model.
Architectural Precedents for General Agents using Large Language Models
May 11, 2025One goal of AI (and AGI) is to identify and understand specific mechanisms and representations sufficient for general intelligence. Often, this work manifests in research focused on architectures and many cognitive architectures have been explored in AI/AGI. However, different research groups and even different research traditions have somewhat independently identified similar/common patterns of processes and representations or cognitive design patterns that are manifest in existing architectures. Today, AI systems exploiting large language models (LLMs) offer a relatively new combination of mechanism and representation available for exploring the possibilities of general intelligence. In this paper, we summarize a few recurring cognitive design patterns that have appeared in various pre-transformer AI architectures. We then explore how these patterns are evident in systems using LLMs, especially for reasoning and interactive ("agentic") use cases. By examining and applying these recurring patterns, we can also predict gaps or deficiencies in today's Agentic LLM Systems and identify likely subjects of future research towards general intelligence using LLMs and other generative foundation models.
Heuristic Recognition and Rapid Response to Unfamiliar Events Outside of Agent Design Scope
Apr 16, 2025



Regardless of past learning, an agent in an open world will face unfamiliar situations and events outside of prior experience, existing models, or policies. Further, the agent will sometimes lack relevant knowledge and/or sufficient time to assess the situation, generate and evaluate options, and pursue a robustly considered course of action. How can an agent respond reasonably to situations that are outside of its original design scope? How can it recognize such situations sufficiently quickly and reliably to determine reasonable, adaptive courses of action? We identify key characteristics needed for solutions, evaluate the state-of-the-art by these requirements, and outline a proposed, novel approach that combines domain-general meta-knowledge (in the form of appraisals inspired by human cognition) and metareasoning. It has the potential to provide fast, adaptive responses to unfamiliar situations, more fully meeting the performance characteristics required for open-world, general agents.
Acquiring Grounded Representations of Words with Situated Interactive Instruction
Feb 28, 2025We present an approach for acquiring grounded representations of words from mixed-initiative, situated interactions with a human instructor. The work focuses on the acquisition of diverse types of knowledge including perceptual, semantic, and procedural knowledge along with learning grounded meanings. Interactive learning allows the agent to control its learning by requesting instructions about unknown concepts, making learning efficient. Our approach has been instantiated in Soar and has been evaluated on a table-top robotic arm capable of manipulating small objects.
A Proposal for Extending the Common Model of Cognition to Emotion
Dec 19, 2024Cognition and emotion must be partnered in any complete model of a humanlike mind. This article proposes an extension to the Common Model of Cognition -- a developing consensus concerning what is required in such a mind -- for emotion that includes a linked pair of modules for emotion and metacognitive assessment, plus pervasive connections between these two new modules and the Common Model's existing modules and links.
Eliciting Problem Specifications via Large Language Models
May 20, 2024



Cognitive systems generally require a human to translate a problem definition into some specification that the cognitive system can use to attempt to solve the problem or perform the task. In this paper, we illustrate that large language models (LLMs) can be utilized to map a problem class, defined in natural language, into a semi-formal specification that can then be utilized by an existing reasoning and learning system to solve instances from the problem class. We present the design of LLM-enabled cognitive task analyst agent(s). Implemented with LLM agents, this system produces a definition of problem spaces for tasks specified in natural language. LLM prompts are derived from the definition of problem spaces in the AI literature and general problem-solving strategies (Polya's How to Solve It). A cognitive system can then use the problem-space specification, applying domain-general problem solving strategies ("weak methods" such as search), to solve multiple instances of problems from the problem class. This result, while preliminary, suggests the potential for speeding cognitive systems research via disintermediation of problem formulation while also retaining core capabilities of cognitive systems, such as robust inference and online learning.
Improving Language Model Prompting in Support of Semi-autonomous Task Learning
Sep 13, 2022
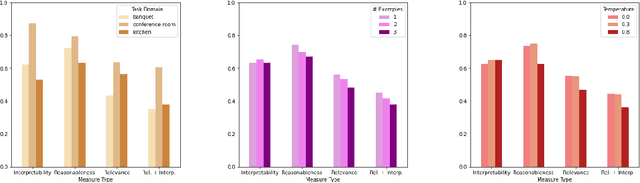

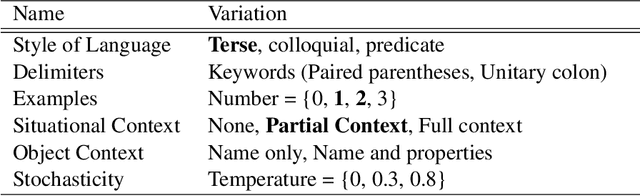
Language models (LLMs) offer potential as a source of knowledge for agents that need to acquire new task competencies within a performance environment. We describe efforts toward a novel agent capability that can construct cues (or "prompts") that result in useful LLM responses for an agent learning a new task. Importantly, responses must not only be "reasonable" (a measure used commonly in research on knowledge extraction from LLMs) but also specific to the agent's task context and in a form that the agent can interpret given its native language capacities. We summarize a series of empirical investigations of prompting strategies and evaluate responses against the goals of targeted and actionable responses for task learning. Our results demonstrate that actionable task knowledge can be obtained from LLMs in support of online agent task learning.
Evaluating Diverse Knowledge Sources for Online One-shot Learning of Novel Tasks
Aug 19, 2022
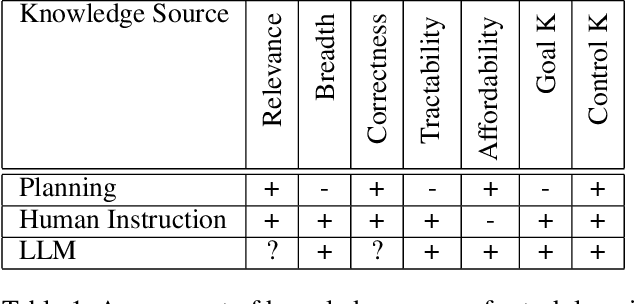

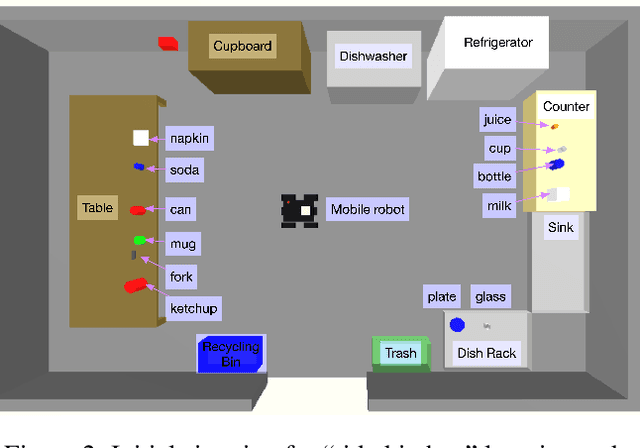
Online autonomous agents are able to draw on a wide variety of potential sources of task knowledge; however current approaches invariably focus on only one or two. Here we investigate the challenges and impact of exploiting diverse knowledge sources to learn, in one-shot, new tasks for a simulated household mobile robot. The resulting agent, developed in the Soar cognitive architecture, uses the following sources of domain and task knowledge: interaction with the environment, task execution and planning knowledge, human natural language instruction, and responses retrieved from a large language model (GPT-3). We explore the distinct contributions of these knowledge sources and evaluate the performance of different combinations in terms of learning correct task knowledge, human workload, and computational costs. The results from combining all sources demonstrate that integration improves one-shot task learning overall in terms of computational costs and human workload.
Introduction to Soar
May 08, 2022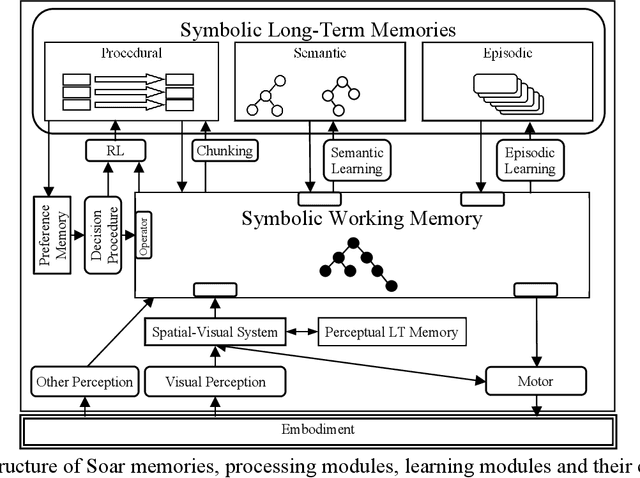
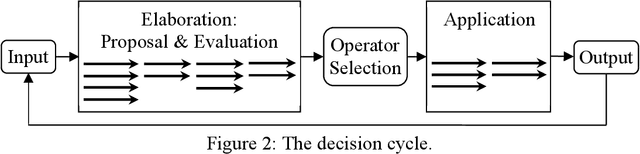
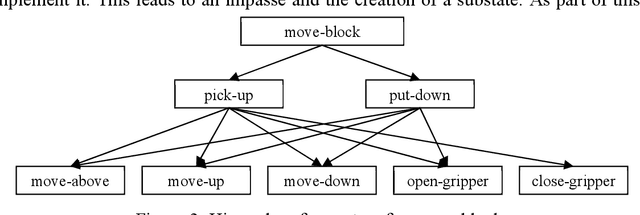
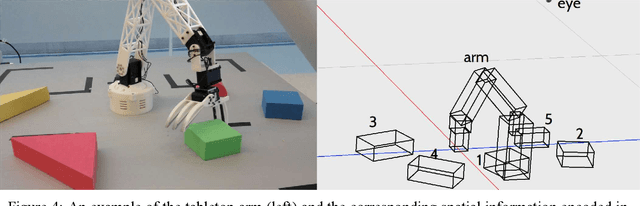
This paper is the recommended initial reading for a functional overview of Soar, version 9.6. It includes an abstract overview of the architectural structure of Soar including its processing, memories, learning modules, their interfaces, and the representations of knowledge used by those modules. From there it describes the processing supported by those modules, including decision making, impasses and substates, procedure learning via chunking, reinforcement learning, semantic memory, episodic memory, and spatial-visual reasoning. It then reviews the levels of decision making and variety of learning in Soar, and analysis of Soar as an architecture supporting general human-level AI. Following the references is an appendix that contains short descriptions of recent Soar agents and a glossary of the terminology we use in describing Soar.