 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlausible but Wrong: A case study on Agentic Failures in Astrophysical Workflows
Apr 28, 2026Agentic AI systems are increasingly being integrated into scientific workflows, yet their behavior under realistic conditions remains insufficiently understood. We evaluate CMBAgent across two workflow paradigms and eighteen astrophysical tasks. In the One-Shot setting, access to domain-specific context yields an approximately ~6x performance improvement (0.85 vs. ~0 without context), with the primary failure mode being silent incorrect computation - syntactically valid code that produces plausible but inaccurate results. In the Deep Research setting, the system frequently exhibits silent failures across stress tests, producing physically inconsistent posteriors without self-diagnosis. Overall, performance is strong on well-specified tasks but degrades on problems designed to probe reasoning limits, often without visible error signals. These findings highlight that the most concerning failure mode in agentic scientific workflows is not overt failure, but confident generation of incorrect results. We release our evaluation framework to facilitate systematic reliability analysis of scientific AI agents.
Reasoning Primitives in Hybrid and Non-Hybrid LLMs
Apr 23, 2026Reasoning in large language models is often treated as a monolithic capability, but its observed gains may arise from more basic operations. We study reasoning through two such primitives, recall and state-tracking, and ask whether hybrid architectures that combine attention-based retrieval with recurrent state updates are better suited than attention-only models for tasks that jointly require both. Using matched Olmo3 transformer and hybrid models in instruction-tuned and reasoning-augmented variants, we evaluate these models on a set of controlled tasks involving a mixture of state-tracking and recall primitives, state-based recall. Across tasks, we notice that reasoning augmentation provides the largest overall improvement, substantially extending the range of difficulty over which models remain effective. We also notice that in certain tasks, the hybrid reasoning model remains substantially more robust as sequential dependence increases. In contrast, the transformer reasoning model degrades sharply in performance as task difficulty increases beyond a given threshold. These results suggest that reasoning tokens and architectural inductive biases contribute at different levels of the computational process: explicit reasoning can expand a model's effective operating range, but its benefit depends on how well the underlying architecture supports persistent state propagation. Given the small size of our case study, which involves a limited set of models and tasks, we present these findings as suggestive rather than conclusive and leave broader validation across model families, scales, and task variations to future work.
Encoder Fine-tuning with Stochastic Sampling Outperforms Open-weight GPT in Astronomy Knowledge Extraction
Nov 11, 2025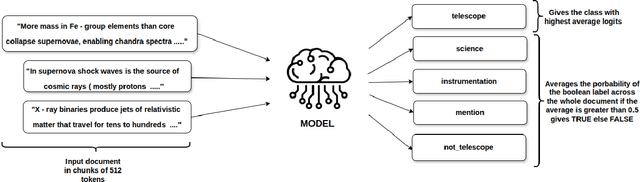

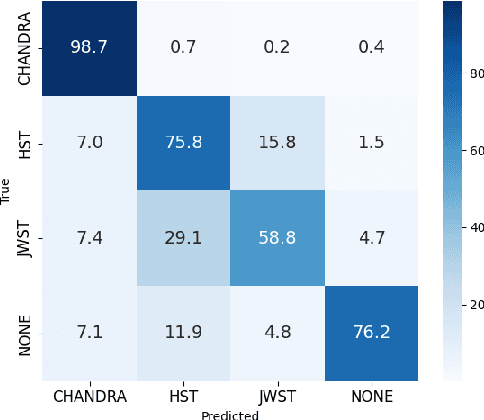
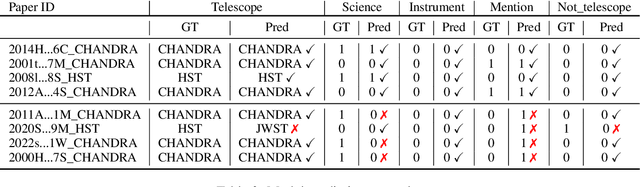
Scientific literature in astronomy is rapidly expanding, making it increasingly important to automate the extraction of key entities and contextual information from research papers. In this paper, we present an encoder-based system for extracting knowledge from astronomy articles. Our objective is to develop models capable of classifying telescope references, detecting auxiliary semantic attributes, and recognizing instrument mentions from textual content. To this end, we implement a multi-task transformer-based system built upon the SciBERT model and fine-tuned for astronomy corpora classification. To carry out the fine-tuning, we stochastically sample segments from the training data and use majority voting over the test segments at inference time. Our system, despite its simplicity and low-cost implementation, significantly outperforms the open-weight GPT baseline.