 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudents Rather Than Experts: A New AI For Education Pipeline To Model More Human-Like And Personalised Early Adolescences
Oct 21, 2024



The capabilities of large language models (LLMs) have been applied in expert systems across various domains, providing new opportunities for AI in Education. Educational interactions involve a cyclical exchange between teachers and students. Current research predominantly focuses on using LLMs to simulate teachers, leveraging their expertise to enhance student learning outcomes. However, the simulation of students, which could improve teachers' instructional skills, has received insufficient attention due to the challenges of modeling and evaluating virtual students. This research asks: Can LLMs be utilized to develop virtual student agents that mimic human-like behavior and individual variability? Unlike expert systems focusing on knowledge delivery, virtual students must replicate learning difficulties, emotional responses, and linguistic uncertainties. These traits present significant challenges in both modeling and evaluation. To address these issues, this study focuses on language learning as a context for modeling virtual student agents. We propose a novel AI4Education framework, called SOE (Scene-Object-Evaluation), to systematically construct LVSA (LLM-based Virtual Student Agents). By curating a dataset of personalized teacher-student interactions with various personality traits, question types, and learning stages, and fine-tuning LLMs using LoRA, we conduct multi-dimensional evaluation experiments. Specifically, we: (1) develop a theoretical framework for generating LVSA; (2) integrate human subjective evaluation metrics into GPT-4 assessments, demonstrating a strong correlation between human evaluators and GPT-4 in judging LVSA authenticity; and (3) validate that LLMs can generate human-like, personalized virtual student agents in educational contexts, laying a foundation for future applications in pre-service teacher training and multi-agent simulation environments.
A Unified Framework for Combinatorial Optimization Based on Graph Neural Networks
Jun 19, 2024



Graph neural networks (GNNs) have emerged as a powerful tool for solving combinatorial optimization problems (COPs), exhibiting state-of-the-art performance in both graph-structured and non-graph-structured domains. However, existing approaches lack a unified framework capable of addressing a wide range of COPs. After presenting a summary of representative COPs and a brief review of recent advancements in GNNs for solving COPs, this paper proposes a unified framework for solving COPs based on GNNs, including graph representation of COPs, equivalent conversion of non-graph structured COPs to graph-structured COPs, graph decomposition, and graph simplification. The proposed framework leverages the ability of GNNs to effectively capture the relational information and extract features from the graph representation of COPs, offering a generic solution to COPs that can address the limitations of state-of-the-art in solving non-graph-structured and highly complex graph-structured COPs.
Deeper and Wider Networks for Performance Metrics Prediction in Communication Networks
Dec 31, 2023In today's era, users have increasingly high expectations regarding the performance and efficiency of communication networks. Network operators aspire to achieve efficient network planning, operation, and optimization through Digital Twin Networks (DTN). The effectiveness of DTN heavily relies on the network model, with graph neural networks (GNN) playing a crucial role in network modeling. However, existing network modeling methods still lack a comprehensive understanding of communication networks. In this paper, we propose DWNet (Deeper and Wider Networks), a heterogeneous graph neural network modeling method based on data-driven approaches that aims to address end-to-end latency and jitter prediction in network models. This method stands out due to two distinctive features: firstly, it introduces deeper levels of state participation in the message passing process; secondly, it extensively integrates relevant features during the feature fusion process. Through experimental validation and evaluation, our model achieves higher prediction accuracy compared to previous research achievements, particularly when dealing with unseen network topologies during model training. Our model not only provides more accurate predictions but also demonstrates stronger generalization capabilities across diverse topological structures.
An Edge-Aware Graph Autoencoder Trained on Scale-Imbalanced Data for Travelling Salesman Problems
Oct 10, 2023Recent years have witnessed a surge in research on machine learning for combinatorial optimization since learning-based approaches can outperform traditional heuristics and approximate exact solvers at a lower computation cost. However, most existing work on supervised neural combinatorial optimization focuses on TSP instances with a fixed number of cities and requires large amounts of training samples to achieve a good performance, making them less practical to be applied to realistic optimization scenarios. This work aims to develop a data-driven graph representation learning method for solving travelling salesman problems (TSPs) with various numbers of cities. To this end, we propose an edge-aware graph autoencoder (EdgeGAE) model that can learn to solve TSPs after being trained on solution data of various sizes with an imbalanced distribution. We formulate the TSP as a link prediction task on sparse connected graphs. A residual gated encoder is trained to learn latent edge embeddings, followed by an edge-centered decoder to output link predictions in an end-to-end manner. To improve the model's generalization capability of solving large-scale problems, we introduce an active sampling strategy into the training process. In addition, we generate a benchmark dataset containing 50,000 TSP instances with a size from 50 to 500 cities, following an extremely scale-imbalanced distribution, making it ideal for investigating the model's performance for practical applications. We conduct experiments using different amounts of training data with various scales, and the experimental results demonstrate that the proposed data-driven approach achieves a highly competitive performance among state-of-the-art learning-based methods for solving TSPs.
End-to-End Pareto Set Prediction with Graph Neural Networks for Multi-objective Facility Location
Oct 27, 2022



The facility location problems (FLPs) are a typical class of NP-hard combinatorial optimization problems, which are widely seen in the supply chain and logistics. Many mathematical and heuristic algorithms have been developed for optimizing the FLP. In addition to the transportation cost, there are usually multiple conflicting objectives in realistic applications. It is therefore desirable to design algorithms that find a set of Pareto solutions efficiently without enormous search cost. In this paper, we consider the multi-objective facility location problem (MO-FLP) that simultaneously minimizes the overall cost and maximizes the system reliability. We develop a learning-based approach to predicting the distribution probability of the entire Pareto set for a given problem. To this end, the MO-FLP is modeled as a bipartite graph optimization problem and two graph neural networks are constructed to learn the implicit graph representation on nodes and edges. The network outputs are then converted into the probability distribution of the Pareto set, from which a set of non-dominated solutions can be sampled non-autoregressively. Experimental results on MO-FLP instances of different scales show that the proposed approach achieves a comparable performance to a widely used multi-objective evolutionary algorithm in terms of the solution quality while significantly reducing the computational cost for search.
A Survey on Surrogate-assisted Efficient Neural Architecture Search
Jun 03, 2022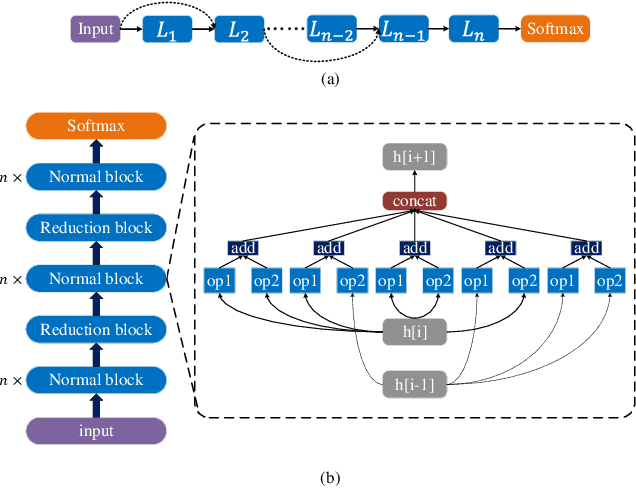
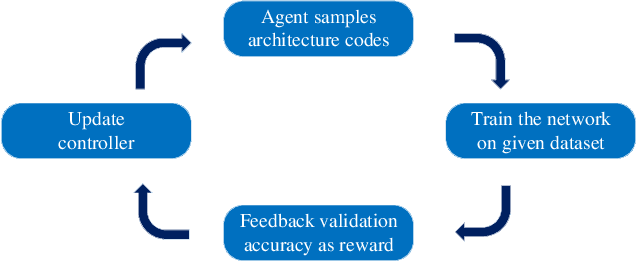
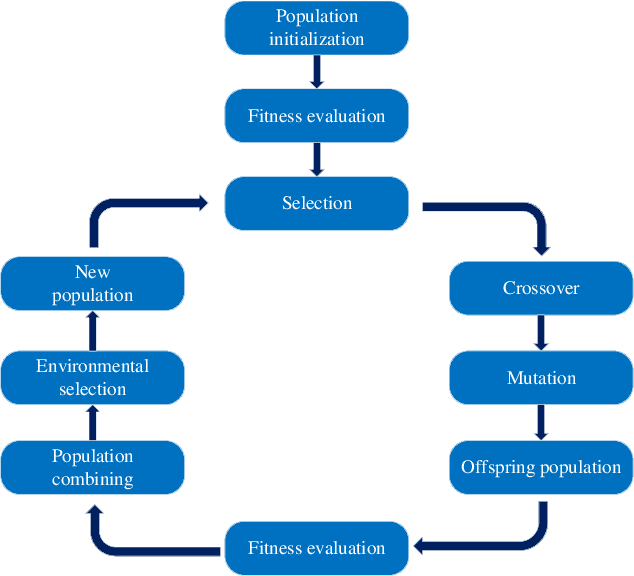
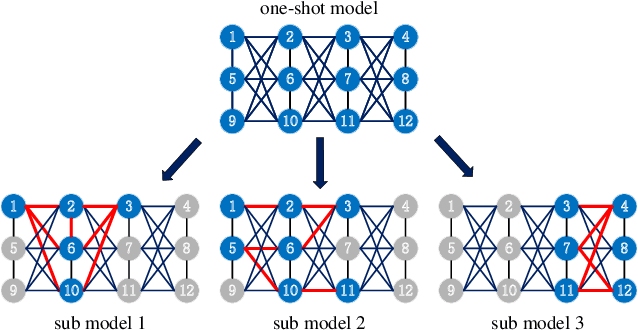
Neural architecture search (NAS) has become increasingly popular in the deep learning community recently, mainly because it can provide an opportunity to allow interested users without rich expertise to benefit from the success of deep neural networks (DNNs). However, NAS is still laborious and time-consuming because a large number of performance estimations are required during the search process of NAS, and training DNNs is computationally intensive. To solve the major limitation of NAS, improving the efficiency of NAS is essential in the design of NAS. This paper begins with a brief introduction to the general framework of NAS. Then, the methods for evaluating network candidates under the proxy metrics are systematically discussed. This is followed by a description of surrogate-assisted NAS, which is divided into three different categories, namely Bayesian optimization for NAS, surrogate-assisted evolutionary algorithms for NAS, and MOP for NAS. Finally, remaining challenges and open research questions are discussed, and promising research topics are suggested in this emerging field.
Federated Learning on Non-IID Data: A Survey
Jun 12, 2021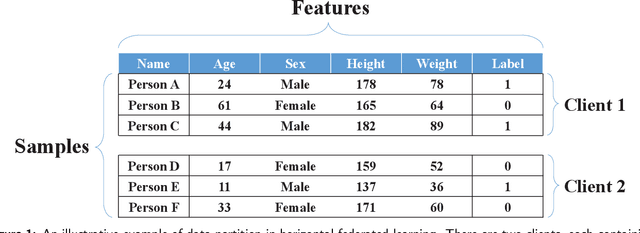
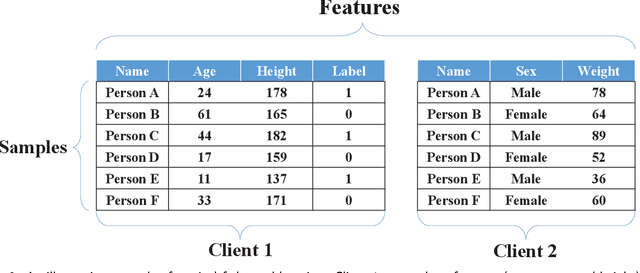

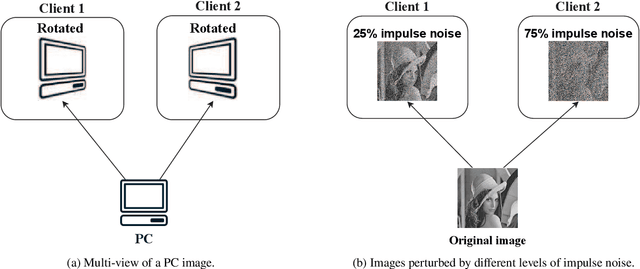
Federated learning is an emerging distributed machine learning framework for privacy preservation. However, models trained in federated learning usually have worse performance than those trained in the standard centralized learning mode, especially when the training data are not independent and identically distributed (Non-IID) on the local devices. In this survey, we pro-vide a detailed analysis of the influence of Non-IID data on both parametric and non-parametric machine learning models in both horizontal and vertical federated learning. In addition, cur-rent research work on handling challenges of Non-IID data in federated learning are reviewed, and both advantages and disadvantages of these approaches are discussed. Finally, we suggest several future research directions before concluding the paper.