 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEATrack: Simple, Efficient, and Adaptive Multimodal Tracker
Apr 14, 2026Parameter-efficient fine-tuning (PEFT) in multimodal tracking reveals a concerning trend where recent performance gains are often achieved at the cost of inflated parameter budgets, which fundamentally erodes PEFT's efficiency promise. In this work, we introduce SEATrack, a Simple, Efficient, and Adaptive two-stream multimodal tracker that tackles this performance-efficiency dilemma from two complementary perspectives. We first prioritize cross-modal alignment of matching responses, an underexplored yet pivotal factor that we argue is essential for breaking the trade-off. Specifically, we observe that modality-specific biases in existing two-stream methods generate conflicting matching attention maps, thereby hindering effective joint representation learning. To mitigate this, we propose AMG-LoRA, which seamlessly integrates Low-Rank Adaptation (LoRA) for domain adaptation with Adaptive Mutual Guidance (AMG) to dynamically refine and align attention maps across modalities. We then depart from conventional local fusion approaches by introducing a Hierarchical Mixture of Experts (HMoE) that enables efficient global relation modeling, effectively balancing expressiveness and computational efficiency in cross-modal fusion. Equipped with these innovations, SEATrack advances notable progress over state-of-the-art methods in balancing performance with efficiency across RGB-T, RGB-D, and RGB-E tracking tasks. \href{https://github.com/AutoLab-SAI-SJTU/SEATrack}{\textcolor{cyan}{Code is available}}.
EMDFNet: Efficient Multi-scale and Diverse Feature Network for Traffic Sign Detection
Aug 26, 2024



The detection of small objects, particularly traffic signs, is a critical subtask within object detection and autonomous driving. Despite the notable achievements in previous research, two primary challenges persist. Firstly, the main issue is the singleness of feature extraction. Secondly, the detection process fails to effectively integrate with objects of varying sizes or scales. These issues are also prevalent in generic object detection. Motivated by these challenges, in this paper, we propose a novel object detection network named Efficient Multi-scale and Diverse Feature Network (EMDFNet) for traffic sign detection that integrates an Augmented Shortcut Module and an Efficient Hybrid Encoder to address the aforementioned issues simultaneously. Specifically, the Augmented Shortcut Module utilizes multiple branches to integrate various spatial semantic information and channel semantic information, thereby enhancing feature diversity. The Efficient Hybrid Encoder utilizes global feature fusion and local feature interaction based on various features to generate distinctive classification features by integrating feature information in an adaptable manner. Extensive experiments on the Tsinghua-Tencent 100K (TT100K) benchmark and the German Traffic Sign Detection Benchmark (GTSDB) demonstrate that our EMDFNet outperforms other state-of-the-art detectors in performance while retaining the real-time processing capabilities of single-stage models. This substantiates the effectiveness of EMDFNet in detecting small traffic signs.
A hierarchical residual network with compact triplet-center loss for sketch recognition
Sep 28, 2021
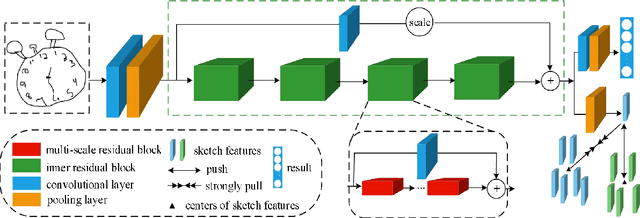
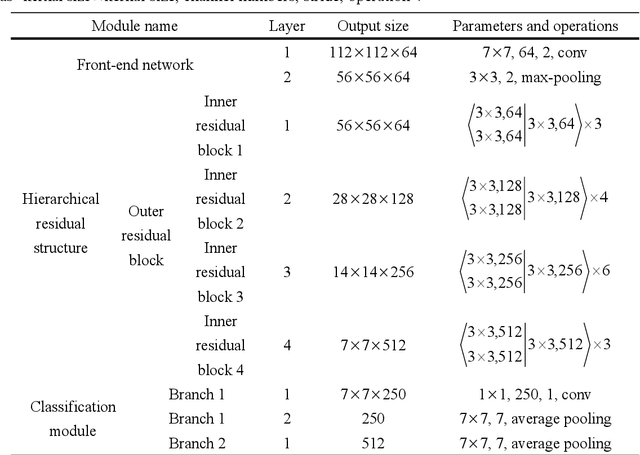
With the widespread use of touch-screen devices, it is more and more convenient for people to draw sketches on screen. This results in the demand for automatically understanding the sketches. Thus, the sketch recognition task becomes more significant than before. To accomplish this task, it is necessary to solve the critical issue of improving the distinction of the sketch features. To this end, we have made efforts in three aspects. First, a novel multi-scale residual block is designed. Compared with the conventional basic residual block, it can better perceive multi-scale information and reduce the number of parameters during training. Second, a hierarchical residual structure is built by stacking multi-scale residual blocks in a specific way. In contrast with the single-level residual structure, the learned features from this structure are more sufficient. Last but not least, the compact triplet-center loss is proposed specifically for the sketch recognition task. It can solve the problem that the triplet-center loss does not fully consider too large intra-class space and too small inter-class space in sketch field. By studying the above modules, a hierarchical residual network as a whole is proposed for sketch recognition and evaluated on Tu-Berlin benchmark thoroughly. The experimental results show that the proposed network outperforms most of baseline methods and it is excellent among non-sequential models at present.