 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Linear Bandits: Overcoming Catastrophic Forgetting through Likelihood Matching
Jan 24, 2019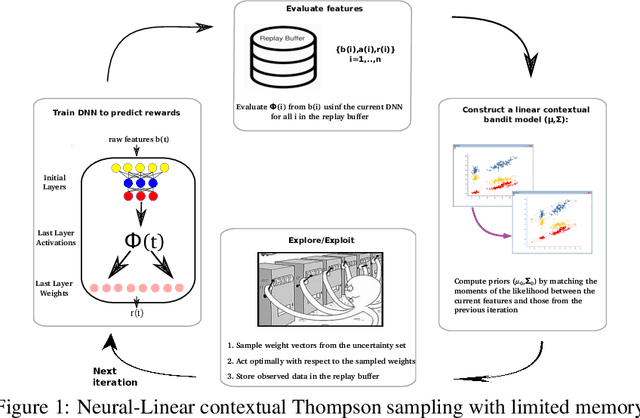
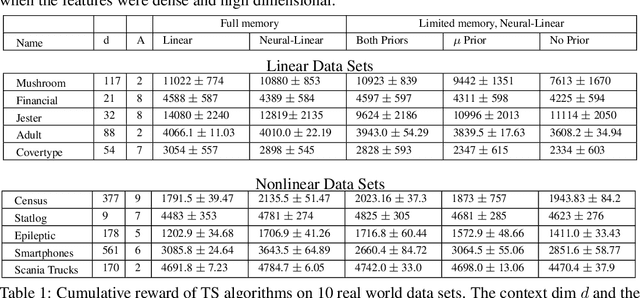


We study the neural-linear bandit model for solving sequential decision-making problems with high dimensional side information. Neural-linear bandits leverage the representation power of deep neural networks and combine it with efficient exploration mechanisms, designed for linear contextual bandits, on top of the last hidden layer. Since the representation is being optimized during learning, information regarding exploration with "old" features is lost. Here, we propose the first limited memory neural-linear bandit that is resilient to this phenomenon, which we term catastrophic forgetting. We evaluate our method on a variety of real-world data sets, including regression, classification, and sentiment analysis, and observe that our algorithm is resilient to catastrophic forgetting and achieves superior performance.
Trust Region Value Optimization using Kalman Filtering
Jan 23, 2019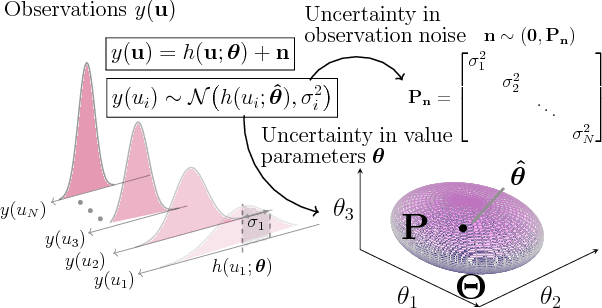


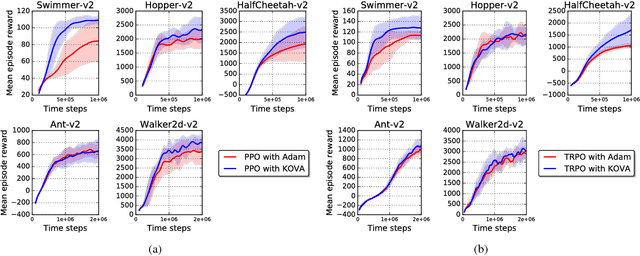
Policy evaluation is a key process in reinforcement learning. It assesses a given policy using estimation of the corresponding value function. When using a parameterized function to approximate the value, it is common to optimize the set of parameters by minimizing the sum of squared Bellman Temporal Differences errors. However, this approach ignores certain distributional properties of both the errors and value parameters. Taking these distributions into account in the optimization process can provide useful information on the amount of confidence in value estimation. In this work we propose to optimize the value by minimizing a regularized objective function which forms a trust region over its parameters. We present a novel optimization method, the Kalman Optimization for Value Approximation (KOVA), based on the Extended Kalman Filter. KOVA minimizes the regularized objective function by adopting a Bayesian perspective over both the value parameters and noisy observed returns. This distributional property provides information on parameter uncertainty in addition to value estimates. We provide theoretical results of our approach and analyze the performance of our proposed optimizer on domains with large state and action spaces.
Multi Instance Learning For Unbalanced Data
Dec 17, 2018
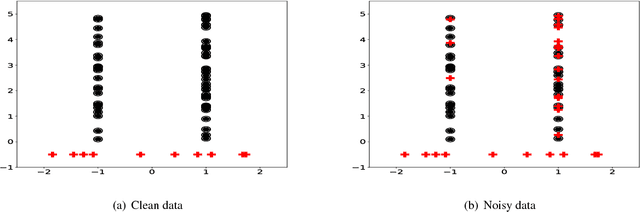
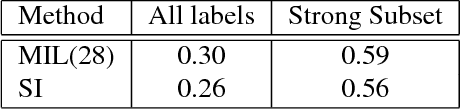
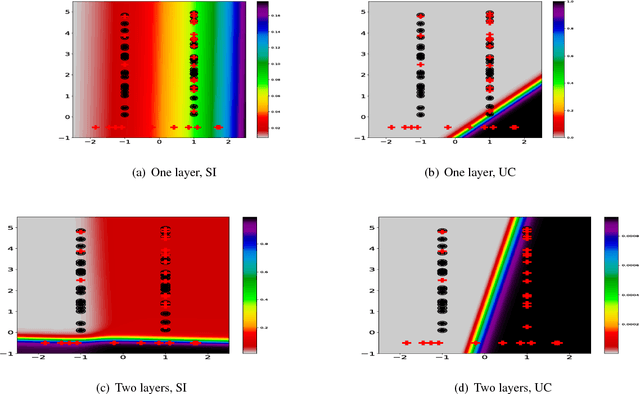
In the context of Multi Instance Learning, we analyze the Single Instance (SI) learning objective. We show that when the data is unbalanced and the family of classifiers is sufficiently rich, the SI method is a useful learning algorithm. In particular, we show that larger data imbalance, a quality that is typically perceived as negative, in fact implies a better resilience of the algorithm to the statistical dependencies of the objects in bags. In addition, our results shed new light on some known issues with the SI method in the setting of linear classifiers, and we show that these issues are significantly less likely to occur in the setting of neural networks. We demonstrate our results on a synthetic dataset, and on the COCO dataset for the problem of patch classification with weak image level labels derived from captions.
Revisiting Exploration-Conscious Reinforcement Learning
Dec 13, 2018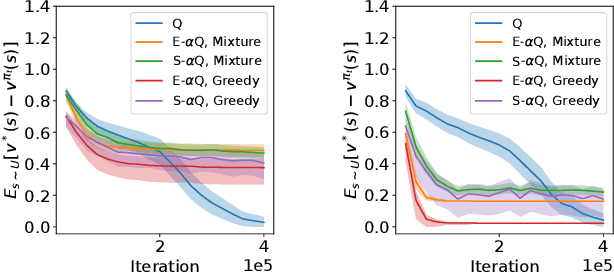
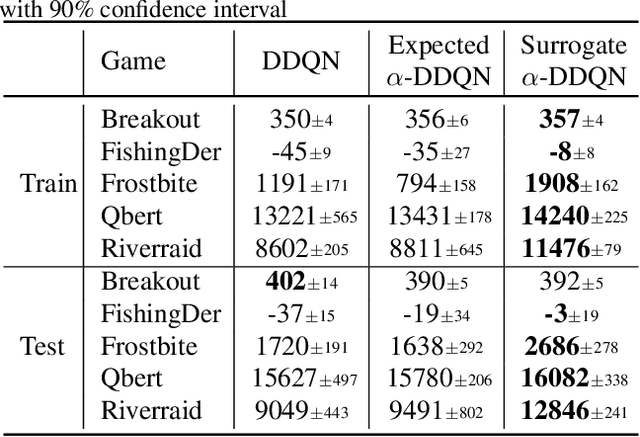
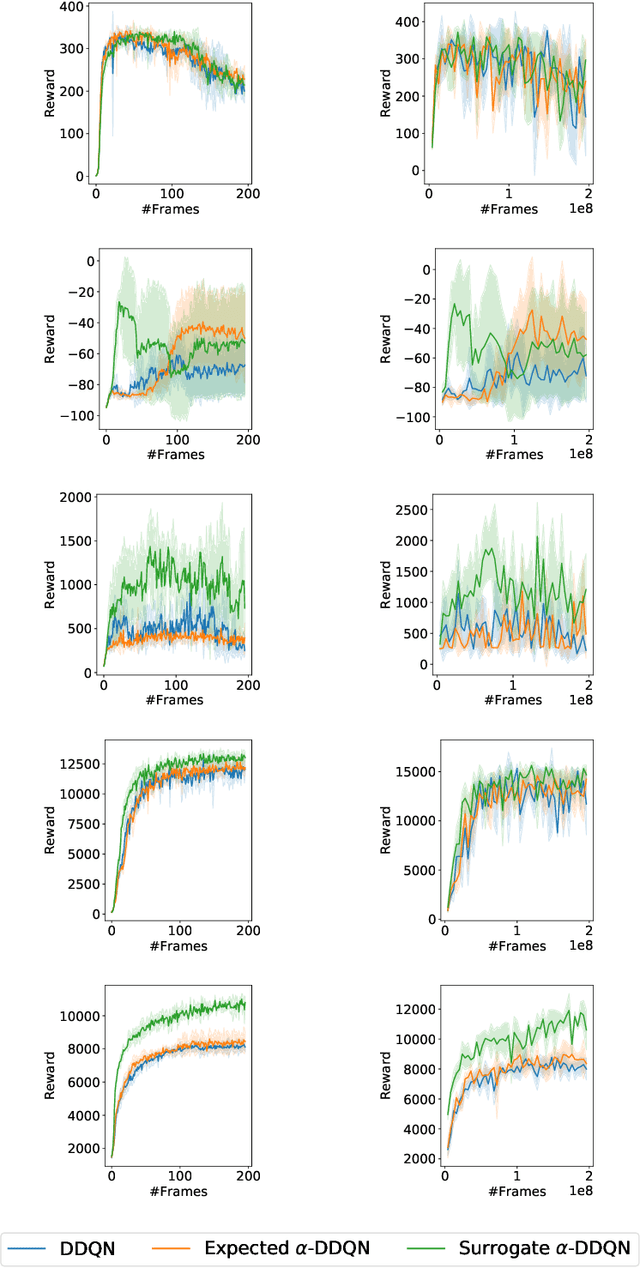
The objective of Reinforcement Learning is to learn an optimal policy by performing actions and observing their long term consequences. Unfortunately, acquiring such a policy can be a hard task. More severely, since one cannot tell if a policy is optimal, there is a constant need for exploration. This is known as the Exploration-Exploitation trade-off. In practice, this trade-off is resolved by using some inherent exploration mechanism, such as the $\epsilon$-greedy exploration, while still trying to learn the optimal policy. In this work, we take a different approach. We define a surrogate optimality objective: an optimal policy with respect to the exploration scheme. As we show throughout the paper, although solving this criterion does not necessarily lead to an optimal policy, the problem becomes easier to solve. We continue by analyzing this notion of optimality, devise algorithms derived from this approach, which reveal connections to existing work, and test them empirically on tabular and deep Reinforcement Learning domains.
Soft-Robust Actor-Critic Policy-Gradient
Oct 24, 2018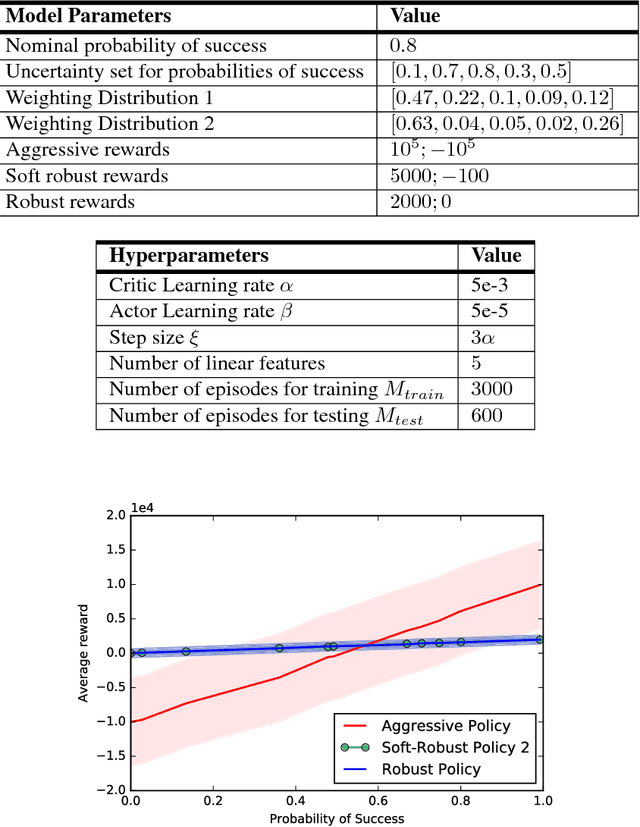
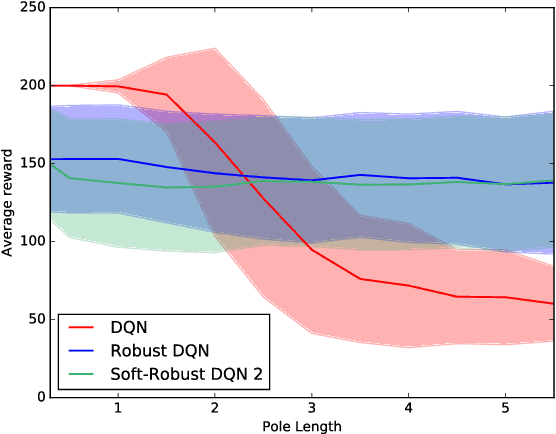
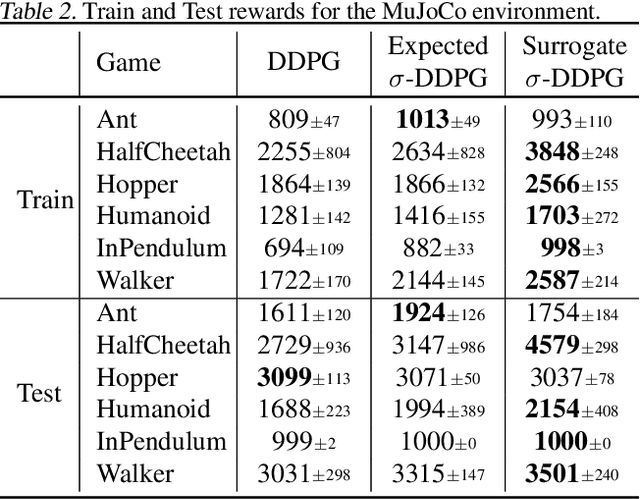
Robust Reinforcement Learning aims to derive optimal behavior that accounts for model uncertainty in dynamical systems. However, previous studies have shown that by considering the worst case scenario, robust policies can be overly conservative. Our soft-robust framework is an attempt to overcome this issue. In this paper, we present a novel Soft-Robust Actor-Critic algorithm (SR-AC). It learns an optimal policy with respect to a distribution over an uncertainty set and stays robust to model uncertainty but avoids the conservativeness of robust strategies. We show the convergence of SR-AC and test the efficiency of our approach on different domains by comparing it against regular learning methods and their robust formulations.
Multiple-Step Greedy Policies in Online and Approximate Reinforcement Learning
Sep 20, 2018
Multiple-step lookahead policies have demonstrated high empirical competence in Reinforcement Learning, via the use of Monte Carlo Tree Search or Model Predictive Control. In a recent work \cite{efroni2018beyond}, multiple-step greedy policies and their use in vanilla Policy Iteration algorithms were proposed and analyzed. In this work, we study multiple-step greedy algorithms in more practical setups. We begin by highlighting a counter-intuitive difficulty, arising with soft-policy updates: even in the absence of approximations, and contrary to the 1-step-greedy case, monotonic policy improvement is not guaranteed unless the update stepsize is sufficiently large. Taking particular care about this difficulty, we formulate and analyze online and approximate algorithms that use such a multi-step greedy operator.
Inspiration Learning through Preferences
Sep 16, 2018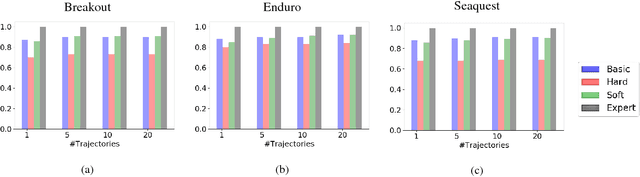
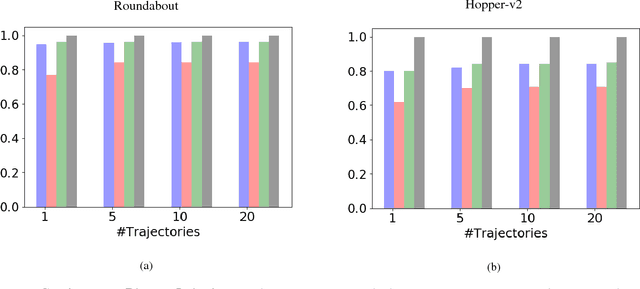
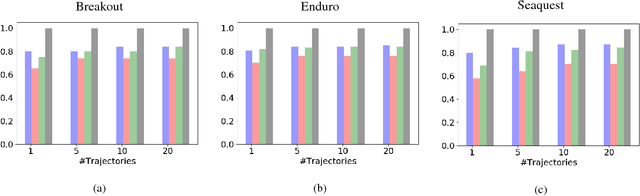
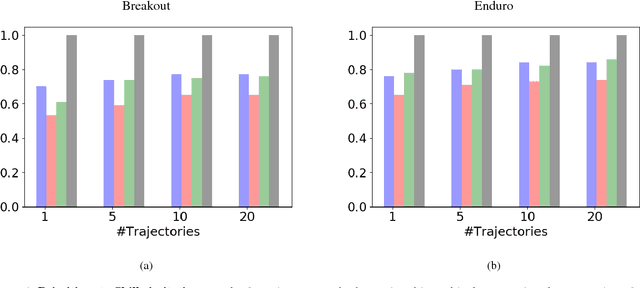
Current imitation learning techniques are too restrictive because they require the agent and expert to share the same action space. However, oftentimes agents that act differently from the expert can solve the task just as good. For example, a person lifting a box can be imitated by a ceiling mounted robot or a desktop-based robotic-arm. In both cases, the end goal of lifting the box is achieved, perhaps using different strategies. We denote this setup as \textit{Inspiration Learning} - knowledge transfer between agents that operate in different action spaces. Since state-action expert demonstrations can no longer be used, Inspiration learning requires novel methods to guide the agent towards the end goal. In this work, we rely on ideas of Preferential based Reinforcement Learning (PbRL) to design Advantage Actor-Critic algorithms for solving inspiration learning tasks. Unlike classic actor-critic architectures, the critic we use consists of two parts: a) a state-value estimation as in common actor-critic algorithms and b) a single step reward function derived from an expert/agent classifier. We show that our method is capable of extending the current imitation framework to new horizons. This includes continuous-to-discrete action imitation, as well as primitive-to-macro action imitation.
On-Line Learning of Linear Dynamical Systems: Exponential Forgetting in Kalman Filters
Sep 16, 2018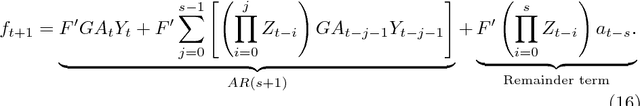
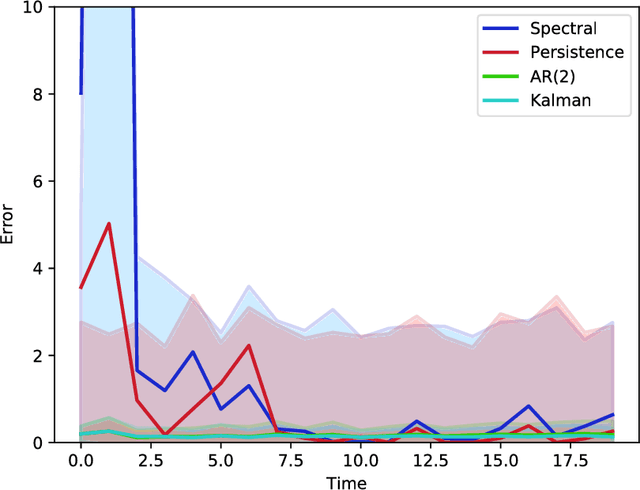
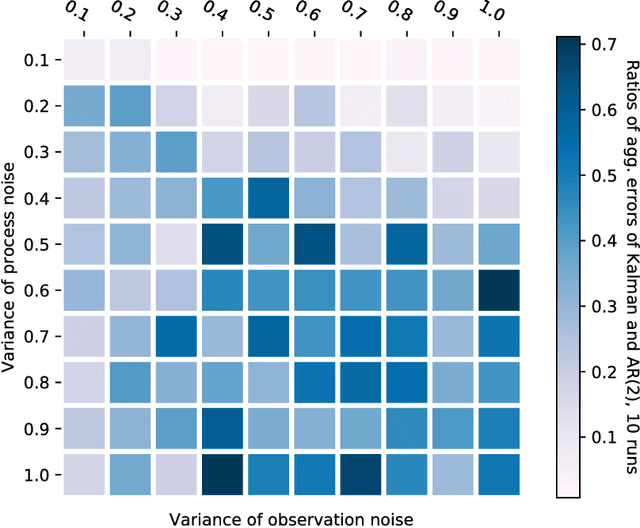
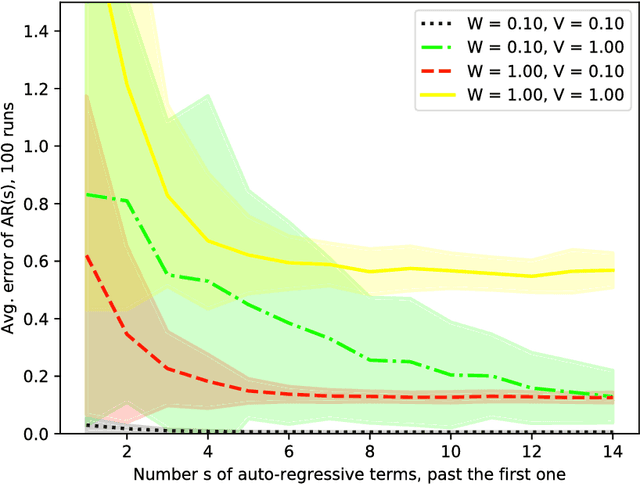
Kalman filter is a key tool for time-series forecasting and analysis. We show that the dependence of a prediction of Kalman filter on the past is decaying exponentially, whenever the process noise is non-degenerate. Therefore, Kalman filter may be approximated by regression on a few recent observations. Surprisingly, we also show that having some process noise is essential for the exponential decay. With no process noise, it may happen that the forecast depends on all of the past uniformly, which makes forecasting more difficult. Based on this insight, we devise an on-line algorithm for improper learning of a linear dynamical system (LDS), which considers only a few most recent observations. We use our decay results to provide the first regret bounds w.r.t. to Kalman filters within learning an LDS. That is, we compare the results of our algorithm to the best, in hindsight, Kalman filter for a given signal. Also, the algorithm is practical: its per-update run-time is linear in the regression depth.
Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning
Sep 06, 2018
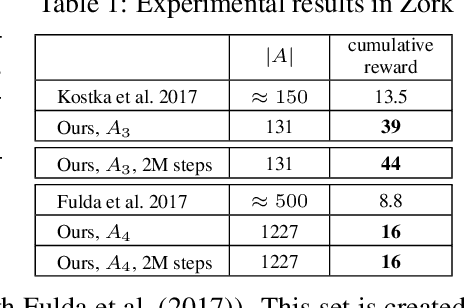
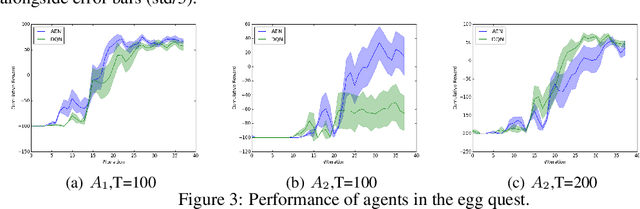
Learning how to act when there are many available actions in each state is a challenging task for Reinforcement Learning (RL) agents, especially when many of the actions are redundant or irrelevant. In such cases, it is sometimes easier to learn which actions not to take. In this work, we propose the Action-Elimination Deep Q-Network (AE-DQN) architecture that combines a Deep RL algorithm with an Action Elimination Network (AEN) that eliminates sub-optimal actions. The AEN is trained to predict invalid actions, supervised by an external elimination signal provided by the environment. Simulations demonstrate a considerable speedup and added robustness over vanilla DQN in text-based games with over a thousand discrete actions.
How to Combine Tree-Search Methods in Reinforcement Learning
Sep 06, 2018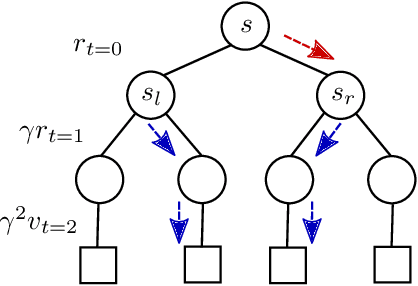
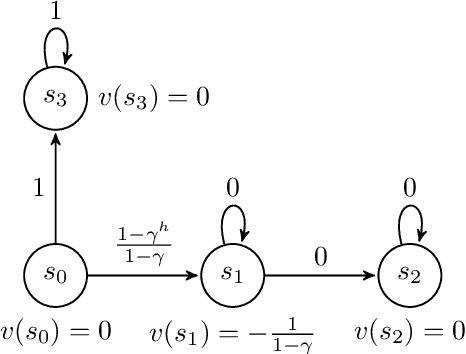
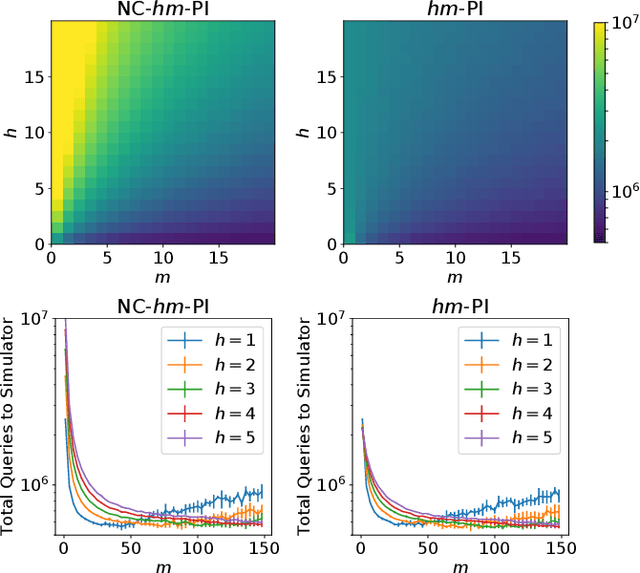
Finite-horizon lookahead policies are abundantly used in Reinforcement Learning and demonstrate impressive empirical success. Usually, the lookahead policies are implemented with specific planning methods such as Monte Carlo Tree Search (e.g. in AlphaZero). Referring to the planning problem as tree search, a reasonable practice in these implementations is to back up the value only at the leaves while the information obtained at the root is not leveraged other than for updating the policy. Here, we question the potency of this approach.Namely, the latter procedure is non-contractive in general, and its convergence is not guaranteed. Our proposed enhancement is straightforward and simple: use the return from the optimal tree path to back up the values at the descendants of the root. This leads to a \gamma^h-contracting procedure, where \gamma is the discount factor and $h$ is the tree depth. To establish our results, we first introduce a notion called multiple-step greedy consistency. We then provide convergence rates for two algorithmic instantiations of the above enhancement in the presence of noise injected to both the tree search stage and value estimation stage.