 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on RNA Subcellular Localization Prediction
Apr 24, 2025



The subcellular localization of RNAs, including long non-coding RNAs (lncRNAs), messenger RNAs (mRNAs), microRNAs (miRNAs) and other smaller RNAs, plays a critical role in determining their biological functions. For instance, lncRNAs are predominantly associated with chromatin and act as regulators of gene transcription and chromatin structure, while mRNAs are distributed across the nucleus and cytoplasm, facilitating the transport of genetic information for protein synthesis. Understanding RNA localization sheds light on processes like gene expression regulation with spatial and temporal precision. However, traditional wet lab methods for determining RNA localization, such as in situ hybridization, are often time-consuming, resource-demanding, and costly. To overcome these challenges, computational methods leveraging artificial intelligence (AI) and machine learning (ML) have emerged as powerful alternatives, enabling large-scale prediction of RNA subcellular localization. This paper provides a comprehensive review of the latest advancements in AI-based approaches for RNA subcellular localization prediction, covering various RNA types and focusing on sequence-based, image-based, and hybrid methodologies that combine both data types. We highlight the potential of these methods to accelerate RNA research, uncover molecular pathways, and guide targeted disease treatments. Furthermore, we critically discuss the challenges in AI/ML approaches for RNA subcellular localization, such as data scarcity and lack of benchmarks, and opportunities to address them. This review aims to serve as a valuable resource for researchers seeking to develop innovative solutions in the field of RNA subcellular localization and beyond.
Protecting Genomic Privacy by a Sequence-Similarity Based Obfuscation Method
Aug 08, 2017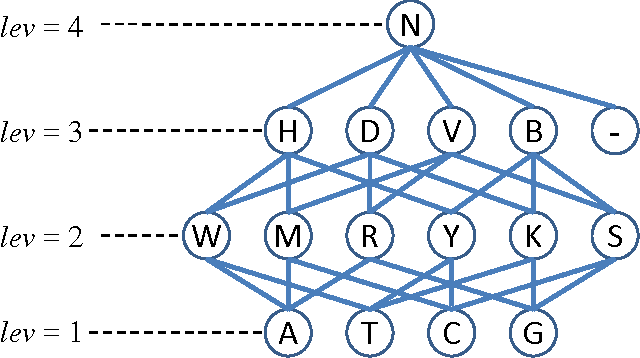
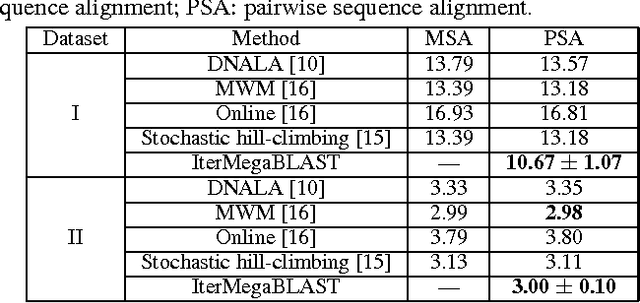
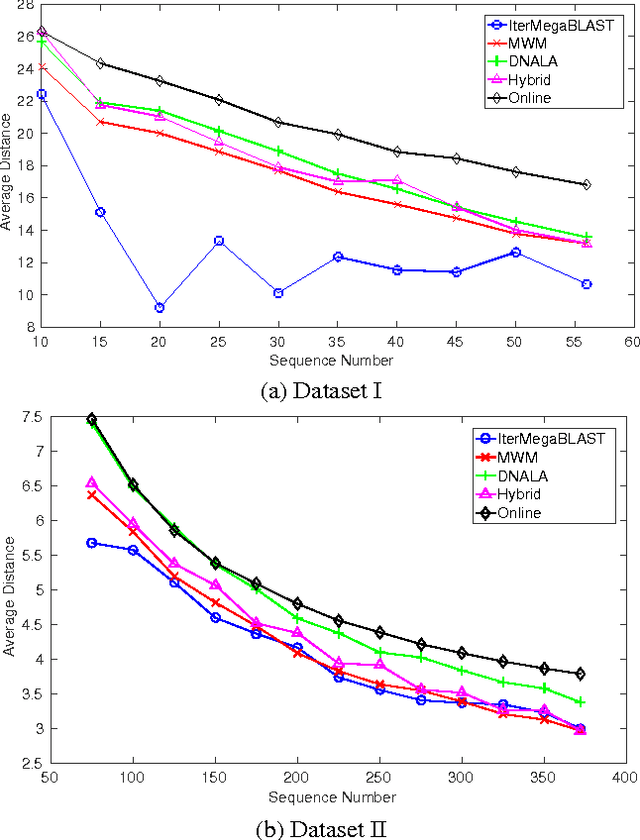

In the post-genomic era, large-scale personal DNA sequences are produced and collected for genetic medical diagnoses and new drug discovery, which, however, simultaneously poses serious challenges to the protection of personal genomic privacy. Existing genomic privacy-protection methods are either time-consuming or with low accuracy. To tackle these problems, this paper proposes a sequence similarity-based obfuscation method, namely IterMegaBLAST, for fast and reliable protection of personal genomic privacy. Specifically, given a randomly selected sequence from a dataset of DNA sequences, we first use MegaBLAST to find its most similar sequence from the dataset. These two aligned sequences form a cluster, for which an obfuscated sequence was generated via a DNA generalization lattice scheme. These procedures are iteratively performed until all of the sequences in the dataset are clustered and their obfuscated sequences are generated. Experimental results on two benchmark datasets demonstrate that under the same degree of anonymity, IterMegaBLAST significantly outperforms existing state-of-the-art approaches in terms of both utility accuracy and time complexity.
Ratio Utility and Cost Analysis for Privacy Preserving Subspace Projection
Feb 26, 2017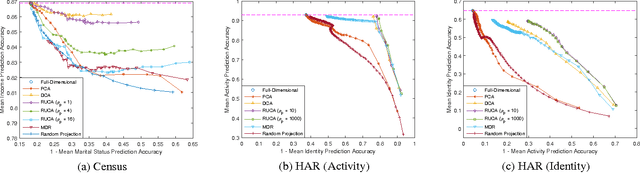
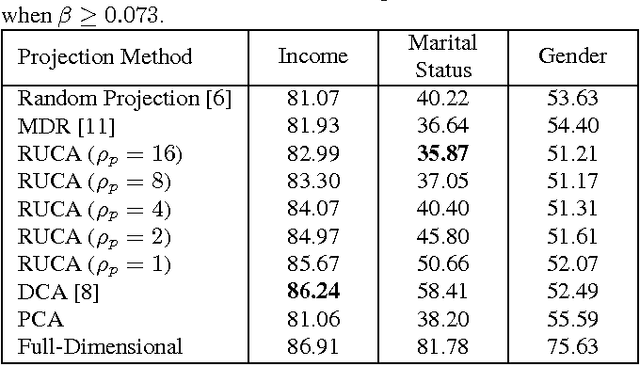
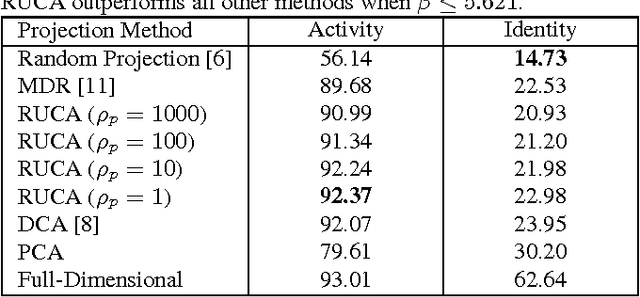
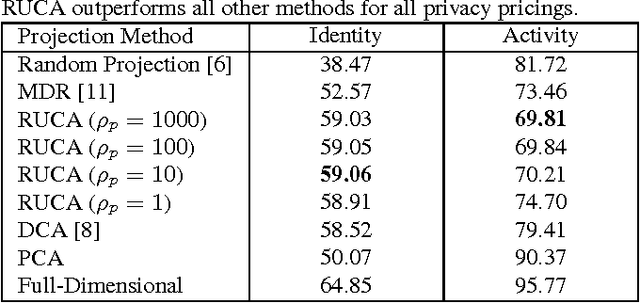
With a rapidly increasing number of devices connected to the internet, big data has been applied to various domains of human life. Nevertheless, it has also opened new venues for breaching users' privacy. Hence it is highly required to develop techniques that enable data owners to privatize their data while keeping it useful for intended applications. Existing methods, however, do not offer enough flexibility for controlling the utility-privacy trade-off and may incur unfavorable results when privacy requirements are high. To tackle these drawbacks, we propose a compressive-privacy based method, namely RUCA (Ratio Utility and Cost Analysis), which can not only maximize performance for a privacy-insensitive classification task but also minimize the ability of any classifier to infer private information from the data. Experimental results on Census and Human Activity Recognition data sets demonstrate that RUCA significantly outperforms existing privacy preserving data projection techniques for a wide range of privacy pricings.