 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
May 25, 2020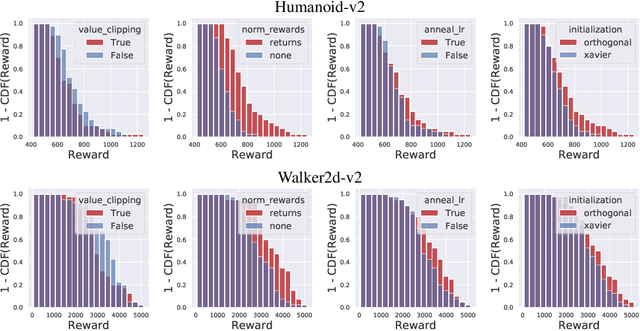

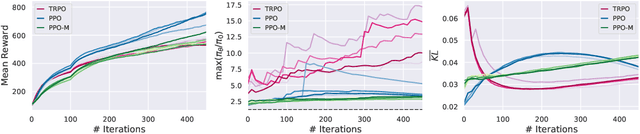
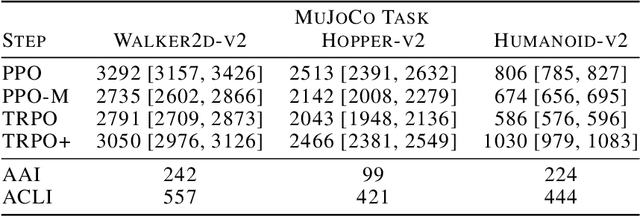
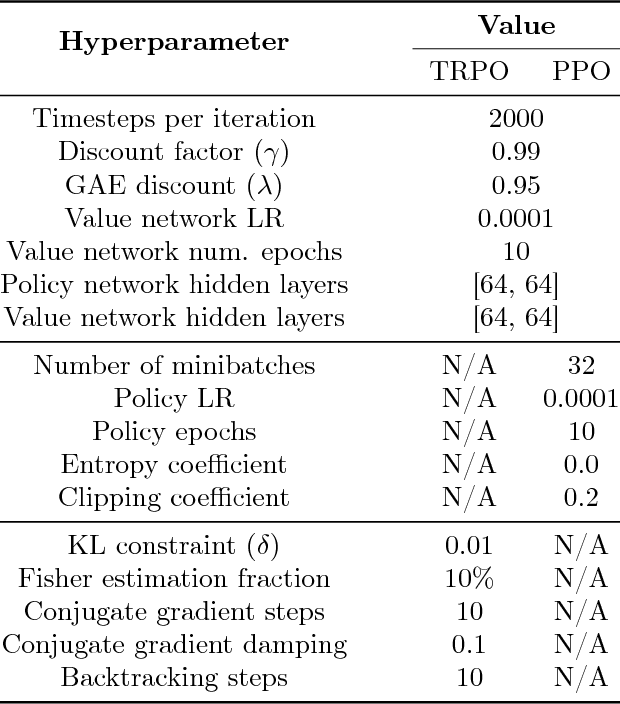
We study the roots of algorithmic progress in deep policy gradient algorithms through a case study on two popular algorithms: Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO). Specifically, we investigate the consequences of "code-level optimizations:" algorithm augmentations found only in implementations or described as auxiliary details to the core algorithm. Seemingly of secondary importance, such optimizations turn out to have a major impact on agent behavior. Our results show that they (a) are responsible for most of PPO's gain in cumulative reward over TRPO, and (b) fundamentally change how RL methods function. These insights show the difficulty and importance of attributing performance gains in deep reinforcement learning. Code for reproducing our results is available at https://github.com/MadryLab/implementation-matters .
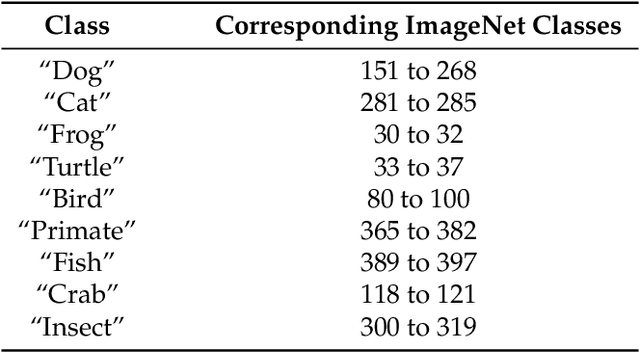
From ImageNet to Image Classification: Contextualizing Progress on Benchmarks
May 22, 2020
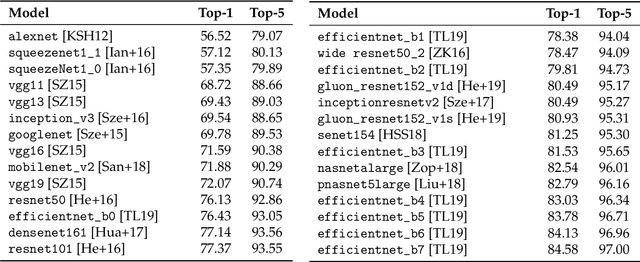
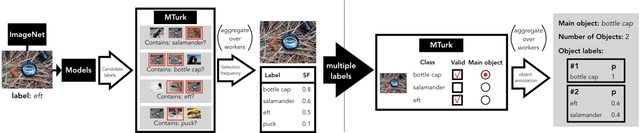
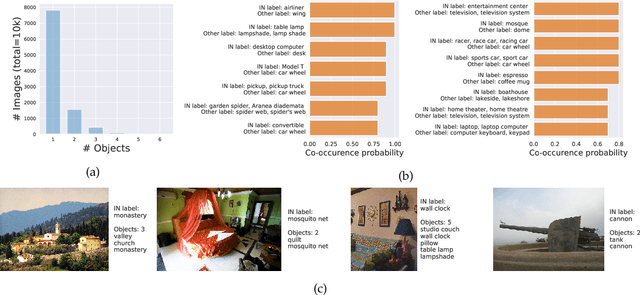
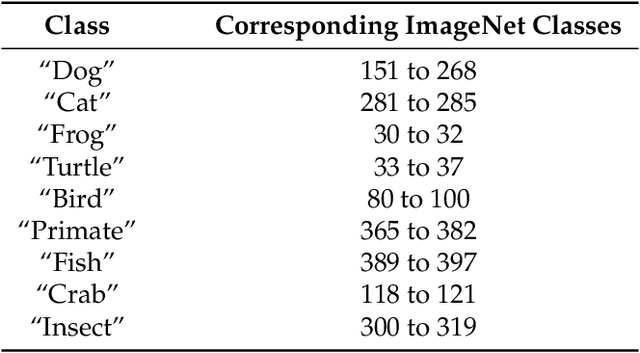
Building rich machine learning datasets in a scalable manner often necessitates a crowd-sourced data collection pipeline. In this work, we use human studies to investigate the consequences of employing such a pipeline, focusing on the popular ImageNet dataset. We study how specific design choices in the ImageNet creation process impact the fidelity of the resulting dataset---including the introduction of biases that state-of-the-art models exploit. Our analysis pinpoints how a noisy data collection pipeline can lead to a systematic misalignment between the resulting benchmark and the real-world task it serves as a proxy for. Finally, our findings emphasize the need to augment our current model training and evaluation toolkit to take such misalignments into account. To facilitate further research, we release our refined ImageNet annotations at https://github.com/MadryLab/ImageNetMultiLabel.
Identifying Statistical Bias in Dataset Replication
May 19, 2020

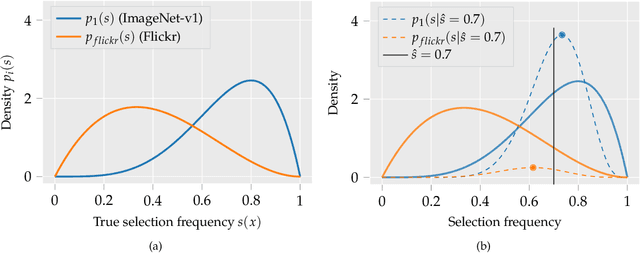

Dataset replication is a useful tool for assessing whether improvements in test accuracy on a specific benchmark correspond to improvements in models' ability to generalize reliably. In this work, we present unintuitive yet significant ways in which standard approaches to dataset replication introduce statistical bias, skewing the resulting observations. We study ImageNet-v2, a replication of the ImageNet dataset on which models exhibit a significant (11-14%) drop in accuracy, even after controlling for a standard human-in-the-loop measure of data quality. We show that after correcting for the identified statistical bias, only an estimated $3.6\% \pm 1.5\%$ of the original $11.7\% \pm 1.0\%$ accuracy drop remains unaccounted for. We conclude with concrete recommendations for recognizing and avoiding bias in dataset replication. Code for our study is publicly available at http://github.com/MadryLab/dataset-replication-analysis .
Computer Vision with a Single (Robust) Classifier
Jun 06, 2019



We show that the basic classification framework alone can be used to tackle some of the most challenging computer vision tasks. In contrast to other state-of-the-art approaches, the toolkit we develop is rather minimal: it uses a single, off-the-shelf classifier for all these tasks. The crux of our approach is that we train this classifier to be adversarially robust. It turns out that adversarial robustness is precisely what we need to directly manipulate salient features of the input. Overall, our findings demonstrate the utility of robustness in the broader machine learning context. Code and models for our experiments can be found at https://git.io/robust-apps.
Learning Perceptually-Aligned Representations via Adversarial Robustness
Jun 03, 2019
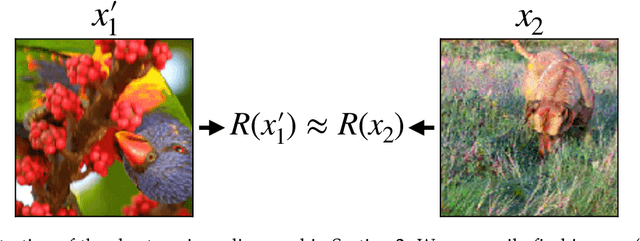

Many applications of machine learning require models that are human-aligned, i.e., that make decisions based on human-meaningful information about the input. We identify the pervasive brittleness of deep networks' learned representations as a fundamental barrier to attaining this goal. We then re-cast robust optimization as a tool for enforcing human priors on the features learned by deep neural networks. The resulting robust feature representations turn out to be significantly more aligned with human perception. We leverage these representations to perform input interpolation, feature manipulation, and sensitivity mapping, without any post-processing or human intervention after model training. Our code and models for reproducing these results is available at https://git.io/robust-reps.
Adversarial Examples Are Not Bugs, They Are Features
May 07, 2019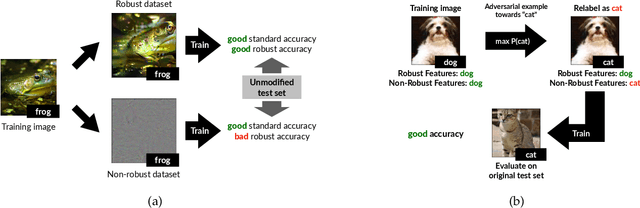
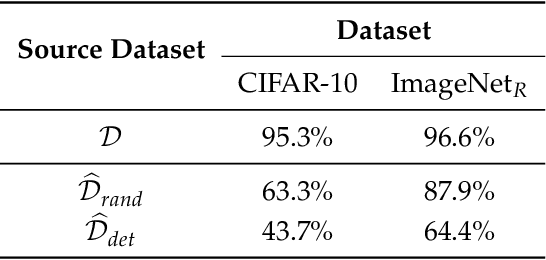
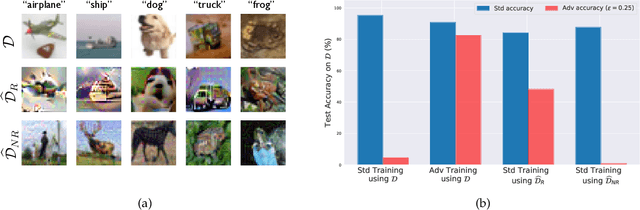
Adversarial examples have attracted significant attention in machine learning, but the reasons for their existence and pervasiveness remain unclear. We demonstrate that adversarial examples can be directly attributed to the presence of non-robust features: features derived from patterns in the data distribution that are highly predictive, yet brittle and incomprehensible to humans. After capturing these features within a theoretical framework, we establish their widespread existence in standard datasets. Finally, we present a simple setting where we can rigorously tie the phenomena we observe in practice to a misalignment between the (human-specified) notion of robustness and the inherent geometry of the data.
Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms?
Dec 02, 2018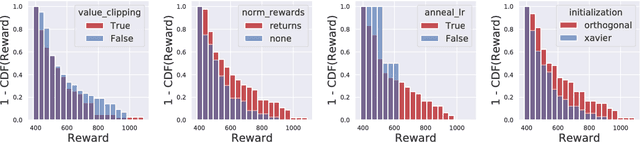
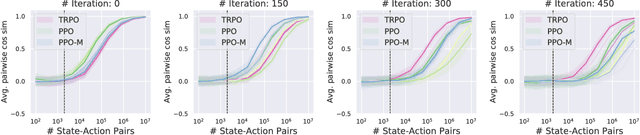
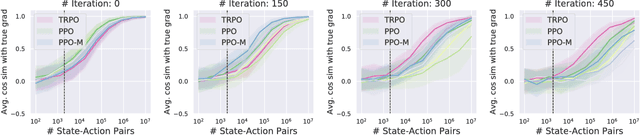
We study how the behavior of deep policy gradient algorithms reflects the conceptual framework motivating their development. We propose a fine-grained analysis of state-of-the-art methods based on key aspects of this framework: gradient estimation, value prediction, optimization landscapes, and trust region enforcement. We find that from this perspective, the behavior of deep policy gradient algorithms often deviates from what their motivating framework would predict. Our analysis suggests first steps towards solidifying the foundations of these algorithms, and in particular indicates that we may need to move beyond the current benchmark-centric evaluation methodology.
How Does Batch Normalization Help Optimization?
Oct 27, 2018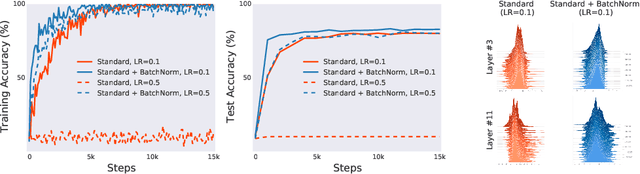
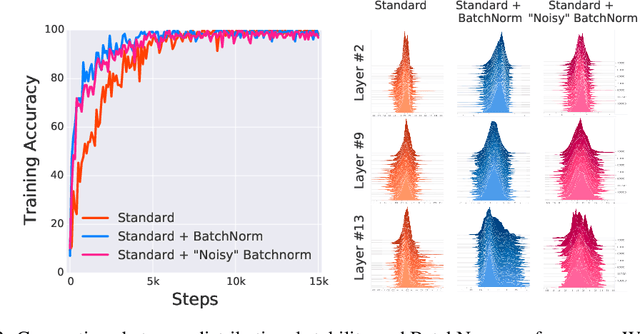
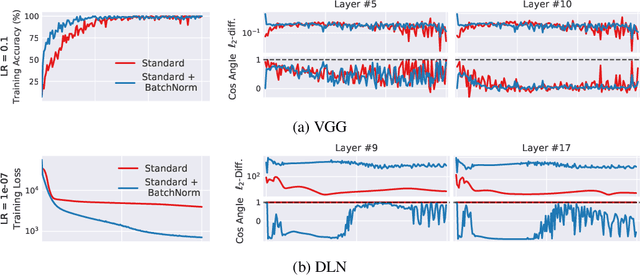
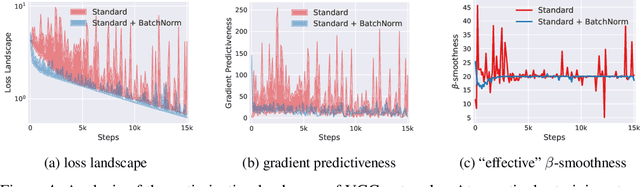
Batch Normalization (BatchNorm) is a widely adopted technique that enables faster and more stable training of deep neural networks (DNNs). Despite its pervasiveness, the exact reasons for BatchNorm's effectiveness are still poorly understood. The popular belief is that this effectiveness stems from controlling the change of the layers' input distributions during training to reduce the so-called "internal covariate shift". In this work, we demonstrate that such distributional stability of layer inputs has little to do with the success of BatchNorm. Instead, we uncover a more fundamental impact of BatchNorm on the training process: it makes the optimization landscape significantly smoother. This smoothness induces a more predictive and stable behavior of the gradients, allowing for faster training.
Robustness May Be at Odds with Accuracy
Oct 11, 2018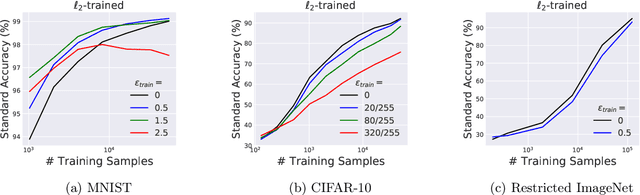
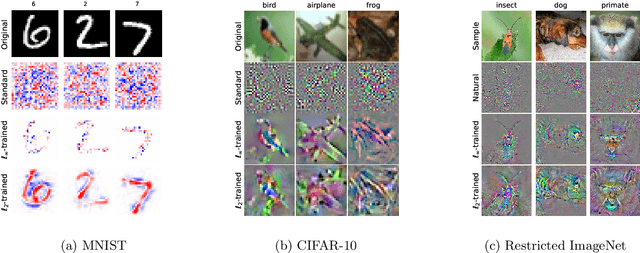

We show that there exists an inherent tension between the goal of adversarial robustness and that of standard generalization. Specifically, training robust models may not only be more resource-consuming, but also lead to a reduction of standard accuracy. We demonstrate that this trade-off between the standard accuracy of a model and its robustness to adversarial perturbations provably exists even in a fairly simple and natural setting. These findings also corroborate a similar phenomenon observed in practice. Further, we argue that this phenomenon is a consequence of robust classifiers learning fundamentally different feature representations than standard classifiers. These differences, in particular, seem to result in unexpected benefits: the representations learned by robust models tend to align better with salient data characteristics and human perception.
A Classification-Based Study of Covariate Shift in GAN Distributions
Jun 06, 2018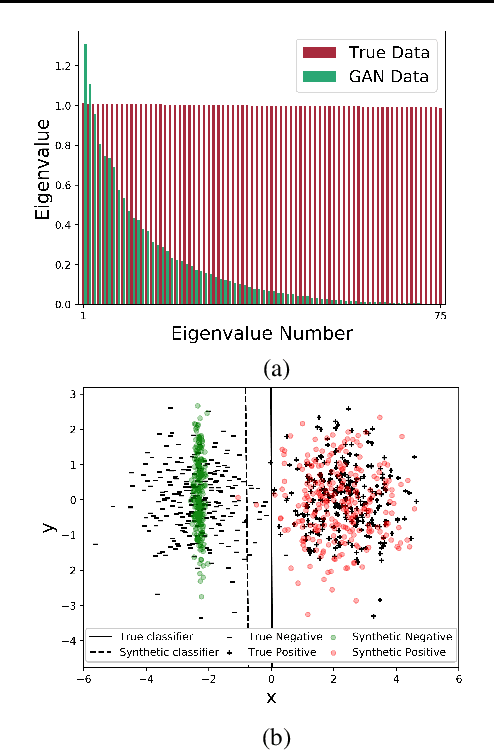
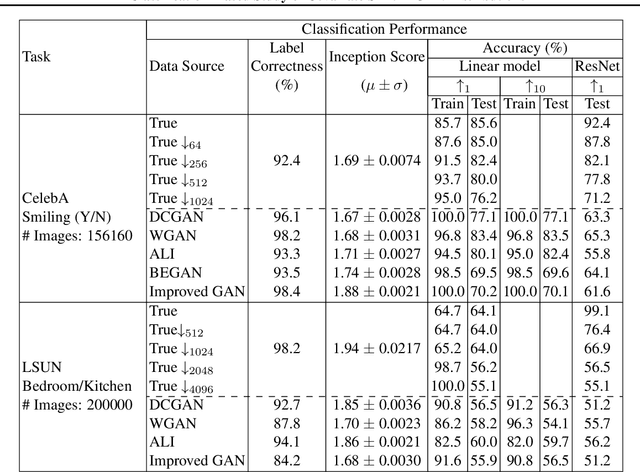
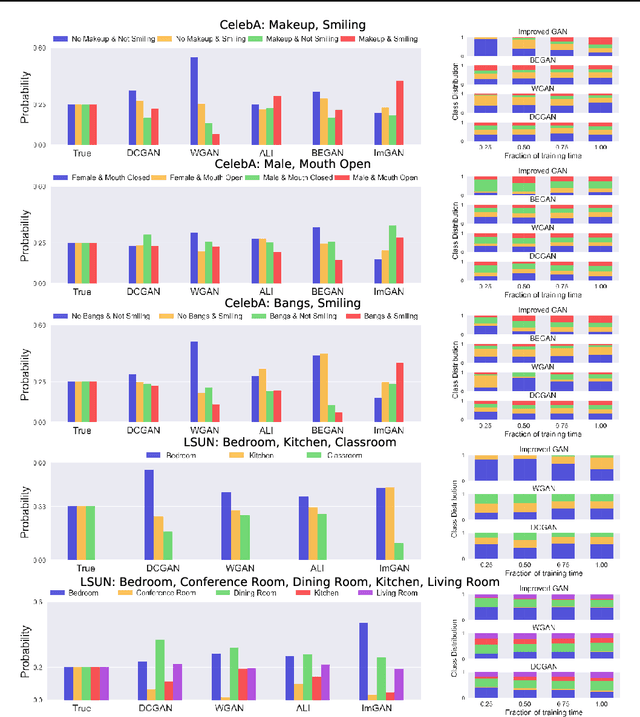
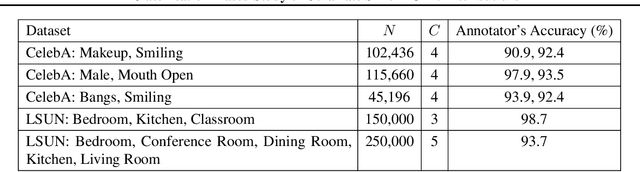
A basic, and still largely unanswered, question in the context of Generative Adversarial Networks (GANs) is whether they are truly able to capture all the fundamental characteristics of the distributions they are trained on. In particular, evaluating the diversity of GAN distributions is challenging and existing methods provide only a partial understanding of this issue. In this paper, we develop quantitative and scalable tools for assessing the diversity of GAN distributions. Specifically, we take a classification-based perspective and view loss of diversity as a form of covariate shift introduced by GANs. We examine two specific forms of such shift: mode collapse and boundary distortion. In contrast to prior work, our methods need only minimal human supervision and can be readily applied to state-of-the-art GANs on large, canonical datasets. Examining popular GANs using our tools indicates that these GANs have significant problems in reproducing the more distributional properties of their training dataset.