 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalmprint Recognition Using Deep Scattering Convolutional Network
Mar 30, 2016
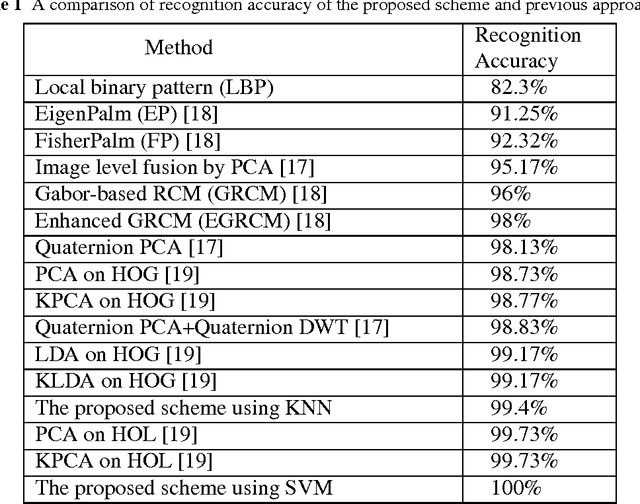


Palmprint recognition has drawn a lot of attention during the recent years. Many algorithms have been proposed for palmprint recognition in the past, majority of them being based on features extracted from the transform domain. Many of these transform domain features are not translation or rotation invariant, and therefore a great deal of preprocessing is needed to align the images. In this paper, a powerful image representation, called scattering network/transform, is used for palmprint recognition. Scattering network is a convolutional network where its architecture and filters are predefined wavelet transforms. The first layer of scattering network captures similar features to SIFT descriptors and the higher-layer features capture higher-frequency content of the signal which are lost in SIFT and other similar descriptors. After extraction of the scattering features, their dimensionality is reduced by applying principal component analysis (PCA) which reduces the computational complexity of the recognition task. Two different classifiers are used for recognition: multi-class SVM and minimum-distance classifier. The proposed scheme has been tested on a well-known palmprint database and achieved accuracy rate of 99.95% and 100% using minimum distance classifier and SVM respectively.
Multispectral Palmprint Recognition Using a Hybrid Feature
Dec 11, 2015


Personal identification problem has been a major field of research in recent years. Biometrics-based technologies that exploit fingerprints, iris, face, voice and palmprints, have been in the center of attention to solve this problem. Palmprints can be used instead of fingerprints that have been of the earliest of these biometrics technologies. A palm is covered with the same skin as the fingertips but has a larger surface, giving us more information than the fingertips. The major features of the palm are palm-lines, including principal lines, wrinkles and ridges. Using these lines is one of the most popular approaches towards solving the palmprint recognition problem. Another robust feature is the wavelet energy of palms. In this paper we used a hybrid feature which combines both of these features. %Moreover, multispectral analysis is applied to improve the performance of the system. At the end, minimum distance classifier is used to match test images with one of the training samples. The proposed algorithm has been tested on a well-known multispectral palmprint dataset and achieved an average accuracy of 98.8\%.
Fingerprint Recognition Using Translation Invariant Scattering Network
Nov 26, 2015

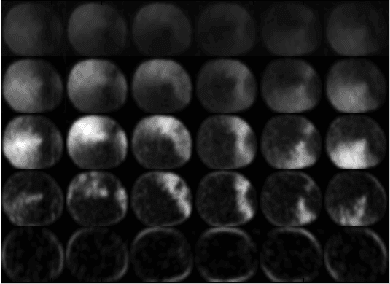

Fingerprint recognition has drawn a lot of attention during last decades. Different features and algorithms have been used for fingerprint recognition in the past. In this paper, a powerful image representation called scattering transform/network, is used for recognition. Scattering network is a convolutional network where its architecture and filters are predefined wavelet transforms. The first layer of scattering representation is similar to sift descriptors and the higher layers capture higher frequency content of the signal. After extraction of scattering features, their dimensionality is reduced by applying principal component analysis (PCA). At the end, multi-class SVM is used to perform template matching for the recognition task. The proposed scheme is tested on a well-known fingerprint database and has shown promising results with the best accuracy rate of 98\%.
On The Power of Joint Wavelet-DCT Features for Multispectral Palmprint Recognition
Nov 26, 2015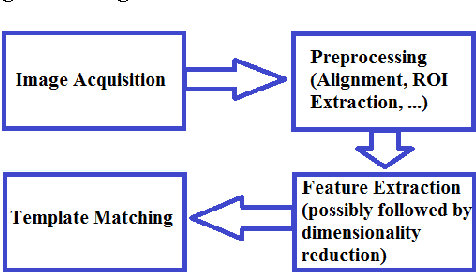

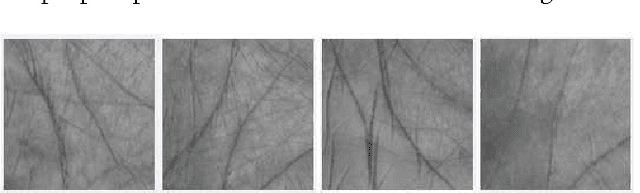
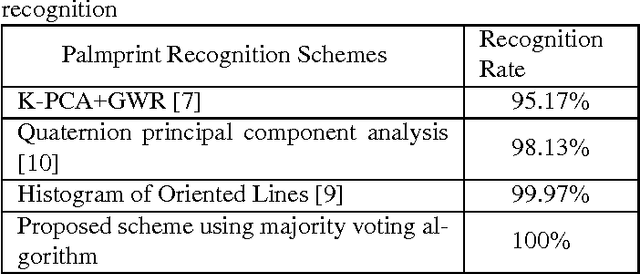
Biometric-based identification has drawn a lot of attention in the recent years. Among all biometrics, palmprint is known to possess a rich set of features. In this paper we have proposed to use DCT-based features in parallel with wavelet-based ones for palmprint identification. PCA is applied to the features to reduce their dimensionality and the majority voting algorithm is used to perform classification. The features introduced here result in a near-perfectly accurate identification. This method is tested on a well-known multispectral palmprint database and an accuracy rate of 99.97-100\% is achieved, outperforming all previous methods in similar conditions.
Screen Content Image Segmentation Using Sparse-Smooth Decomposition
Nov 21, 2015
Sparse decomposition has been extensively used for different applications including signal compression and denoising and document analysis. In this paper, sparse decomposition is used for image segmentation. The proposed algorithm separates the background and foreground using a sparse-smooth decomposition technique such that the smooth and sparse components correspond to the background and foreground respectively. This algorithm is tested on several test images from HEVC test sequences and is shown to have superior performance over other methods, such as the hierarchical k-means clustering in DjVu. This segmentation algorithm can also be used for text extraction, video compression and medical image segmentation.
A Robust Regression Approach for Background/Foreground Segmentation
Sep 01, 2015

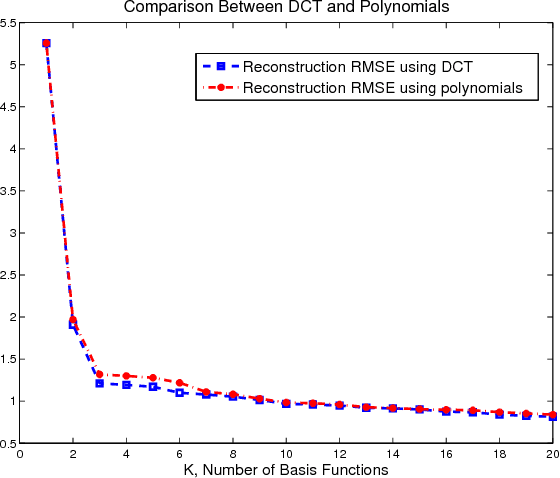
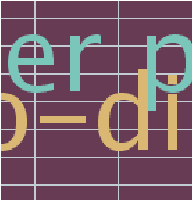
Background/foreground segmentation has a lot of applications in image and video processing. In this paper, a segmentation algorithm is proposed which is mainly designed for text and line extraction in screen content. The proposed method makes use of the fact that the background in each block is usually smoothly varying and can be modeled well by a linear combination of a few smoothly varying basis functions, while the foreground text and graphics create sharp discontinuity. The algorithm separates the background and foreground pixels by trying to fit pixel values in the block into a smooth function using a robust regression method. The inlier pixels that can fit well will be considered as background, while remaining outlier pixels will be considered foreground. This algorithm has been extensively tested on several images from HEVC standard test sequences for screen content coding, and is shown to have superior performance over other methods, such as the k-means clustering based segmentation algorithm in DjVu. This background/foreground segmentation can be used in different applications such as: text extraction, separate coding of background and foreground for compression of screen content and mixed content documents, principle line extraction from palmprint and crease detection in fingerprint images.
Iris Recognition Using Scattering Transform and Textural Features
Jul 08, 2015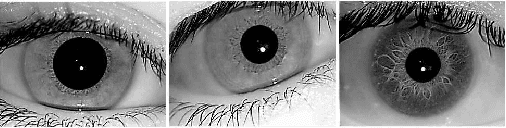
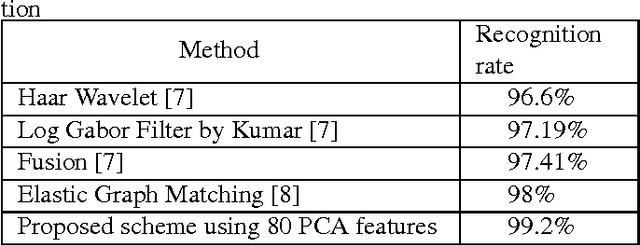

Iris recognition has drawn a lot of attention since the mid-twentieth century. Among all biometric features, iris is known to possess a rich set of features. Different features have been used to perform iris recognition in the past. In this paper, two powerful sets of features are introduced to be used for iris recognition: scattering transform-based features and textural features. PCA is also applied on the extracted features to reduce the dimensionality of the feature vector while preserving most of the information of its initial value. Minimum distance classifier is used to perform template matching for each new test sample. The proposed scheme is tested on a well-known iris database, and showed promising results with the best accuracy rate of 99.2%.
Highly Accurate Multispectral Palmprint Recognition Using Statistical and Wavelet Features
Jun 24, 2015
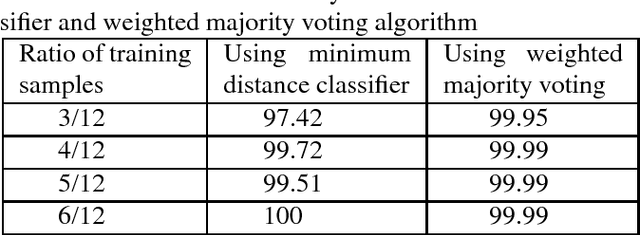
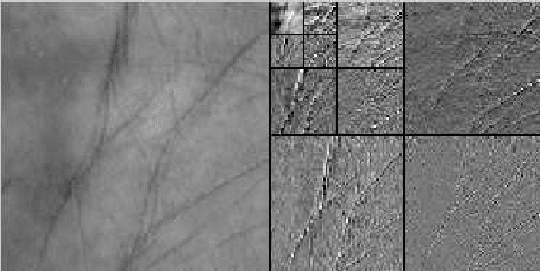
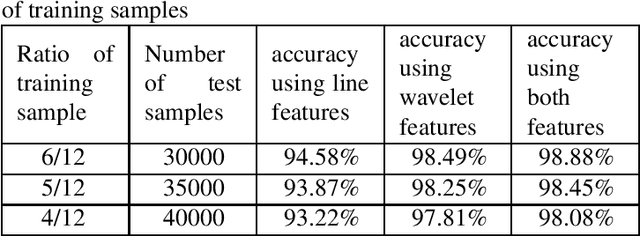
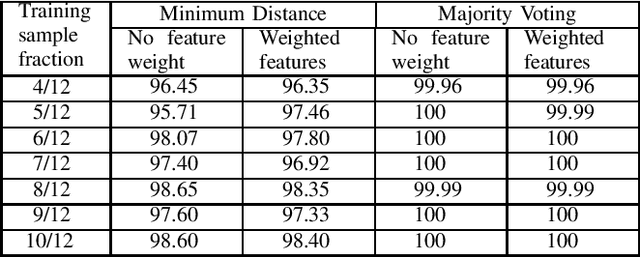
Palmprint is one of the most useful physiological biometrics that can be used as a powerful means in personal recognition systems. The major features of the palmprints are palm lines, wrinkles and ridges, and many approaches use them in different ways towards solving the palmprint recognition problem. Here we have proposed to use a set of statistical and wavelet-based features; statistical to capture the general characteristics of palmprints; and wavelet-based to find those information not evident in the spatial domain. Also we use two different classification approaches, minimum distance classifier scheme and weighted majority voting algorithm, to perform palmprint matching. The proposed method is tested on a well-known palmprint dataset of 6000 samples and has shown an impressive accuracy rate of 99.65\%-100\% for most scenarios.
Screen Content Image Segmentation Using Least Absolute Deviation Fitting
Feb 19, 2015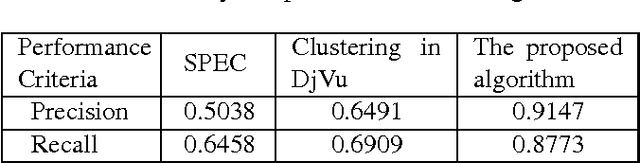

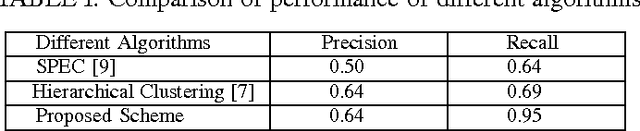
We propose an algorithm for separating the foreground (mainly text and line graphics) from the smoothly varying background in screen content images. The proposed method is designed based on the assumption that the background part of the image is smoothly varying and can be represented by a linear combination of a few smoothly varying basis functions, while the foreground text and graphics create sharp discontinuity and cannot be modeled by this smooth representation. The algorithm separates the background and foreground using a least absolute deviation method to fit the smooth model to the image pixels. This algorithm has been tested on several images from HEVC standard test sequences for screen content coding, and is shown to have superior performance over other popular methods, such as k-means clustering based segmentation in DjVu and shape primitive extraction and coding (SPEC) algorithm. Such background/foreground segmentation are important pre-processing steps for text extraction and separate coding of background and foreground for compression of screen content images.
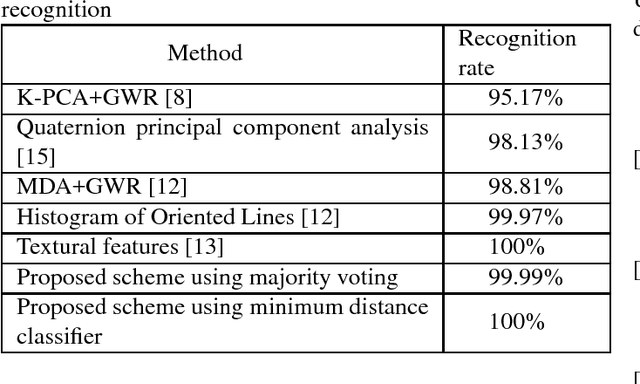
Multispectral Palmprint Recognition Using Textural Features
Feb 12, 2015
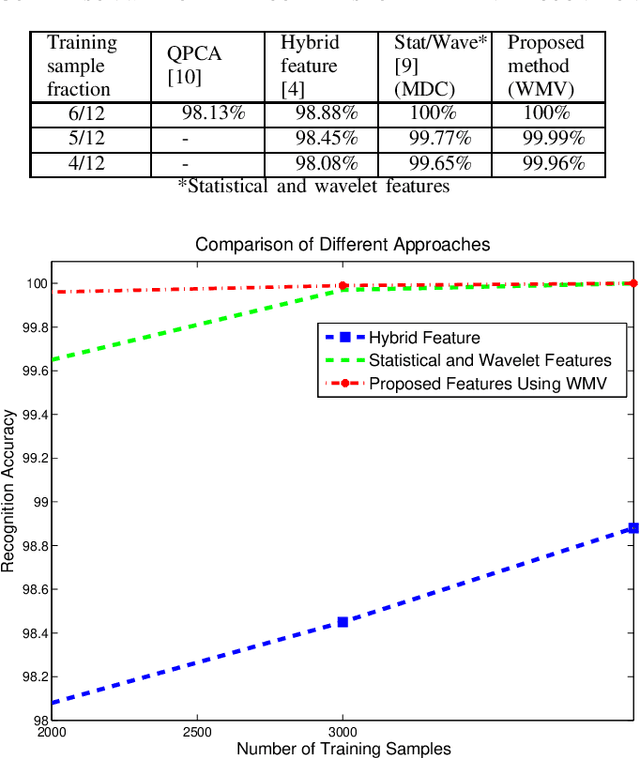
In order to utilize identification to the best extent, we need robust and fast algorithms and systems to process the data. Having palmprint as a reliable and unique characteristic of every person, we extract and use its features based on its geometry, lines and angles. There are countless ways to define measures for the recognition task. To analyze a new point of view, we extracted textural features and used them for palmprint recognition. Co-occurrence matrix can be used for textural feature extraction. As classifiers, we have used the minimum distance classifier (MDC) and the weighted majority voting system (WMV). The proposed method is tested on a well-known multispectral palmprint dataset of 6000 samples and an accuracy rate of 99.96-100% is obtained for most scenarios which outperforms all previous works in multispectral palmprint recognition.