 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG1020: A Benchmark Retinal Fundus Image Dataset for Computer-Aided Glaucoma Detection
May 28, 2020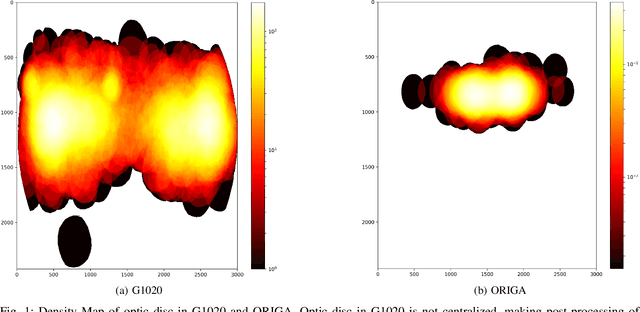
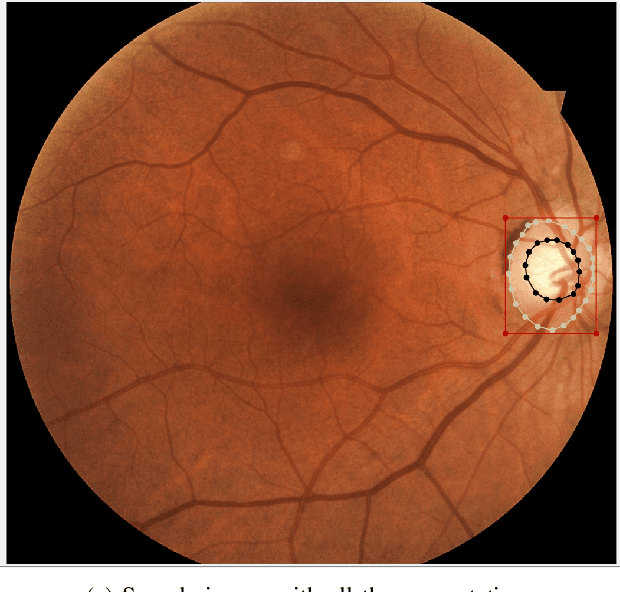
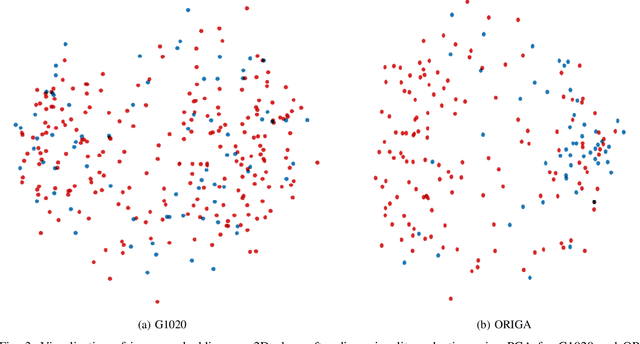
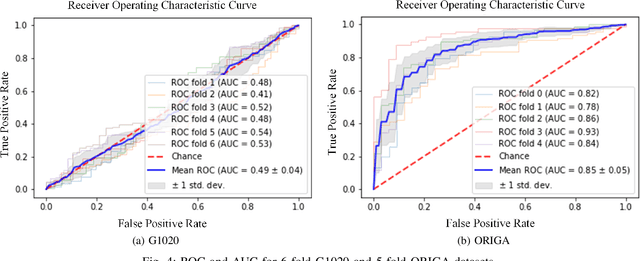
Scarcity of large publicly available retinal fundus image datasets for automated glaucoma detection has been the bottleneck for successful application of artificial intelligence towards practical Computer-Aided Diagnosis (CAD). A few small datasets that are available for research community usually suffer from impractical image capturing conditions and stringent inclusion criteria. These shortcomings in already limited choice of existing datasets make it challenging to mature a CAD system so that it can perform in real-world environment. In this paper we present a large publicly available retinal fundus image dataset for glaucoma classification called G1020. The dataset is curated by conforming to standard practices in routine ophthalmology and it is expected to serve as standard benchmark dataset for glaucoma detection. This database consists of 1020 high resolution colour fundus images and provides ground truth annotations for glaucoma diagnosis, optic disc and optic cup segmentation, vertical cup-to-disc ratio, size of neuroretinal rim in inferior, superior, nasal and temporal quadrants, and bounding box location for optic disc. We also report baseline results by conducting extensive experiments for automated glaucoma diagnosis and segmentation of optic disc and optic cup.
Interpreting Deep Models through the Lens of Data
May 19, 2020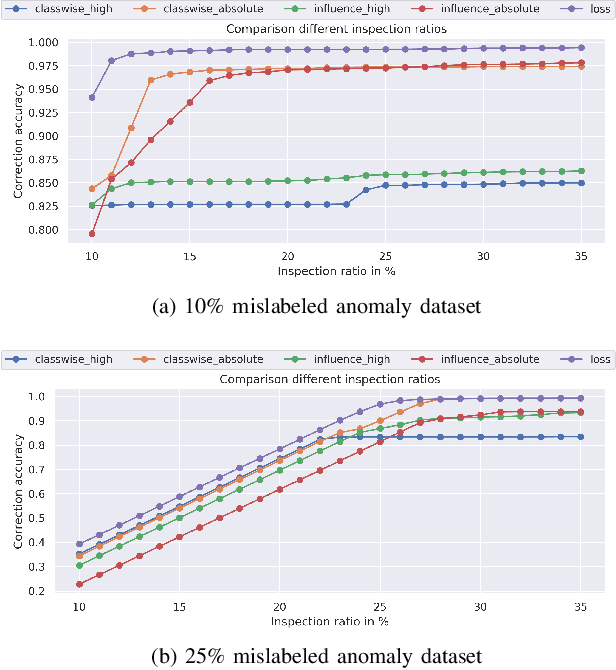
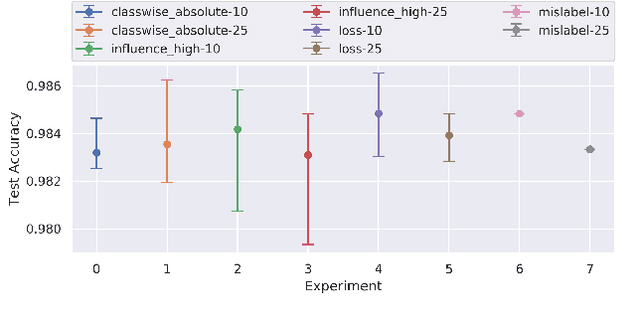
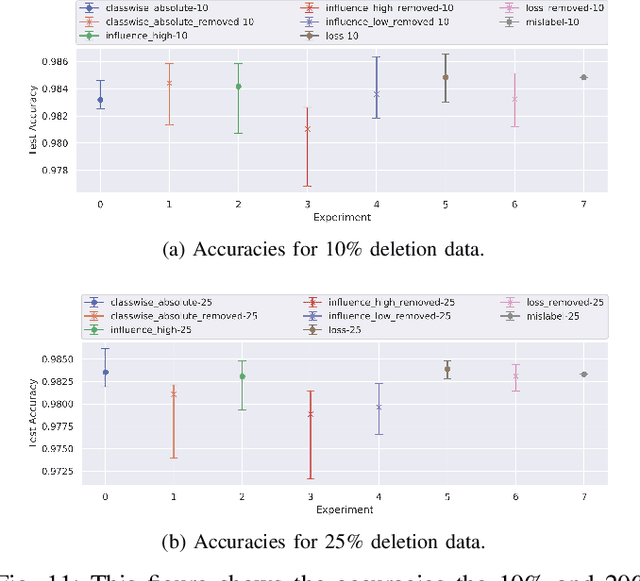
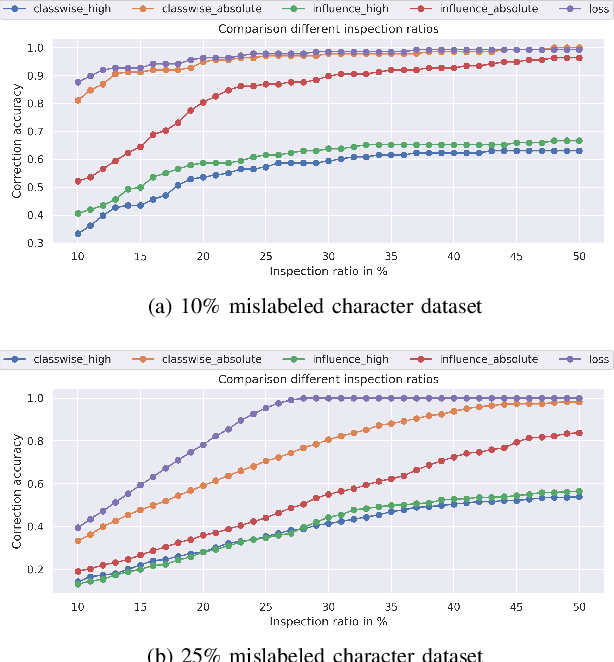
Identification of input data points relevant for the classifier (i.e. serve as the support vector) has recently spurred the interest of researchers for both interpretability as well as dataset debugging. This paper presents an in-depth analysis of the methods which attempt to identify the influence of these data points on the resulting classifier. To quantify the quality of the influence, we curated a set of experiments where we debugged and pruned the dataset based on the influence information obtained from different methods. To do so, we provided the classifier with mislabeled examples that hampered the overall performance. Since the classifier is a combination of both the data and the model, therefore, it is essential to also analyze these influences for the interpretability of deep learning models. Analysis of the results shows that some interpretability methods can detect mislabels better than using a random approach, however, contrary to the claim of these methods, the sample selection based on the training loss showed a superior performance.
P2ExNet: Patch-based Prototype Explanation Network
May 05, 2020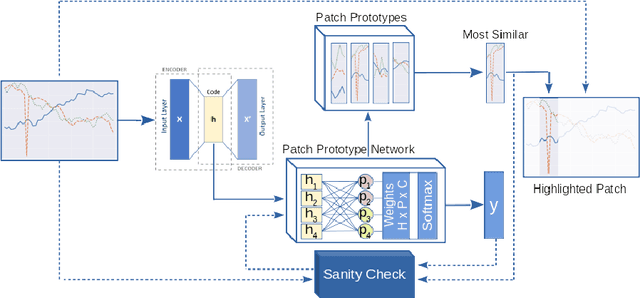
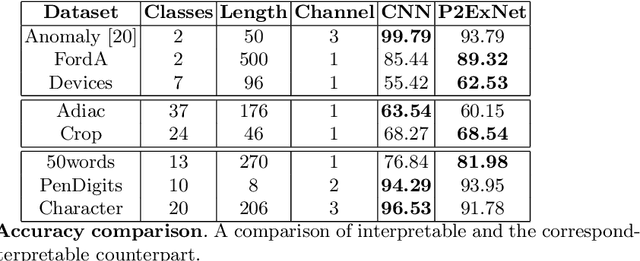

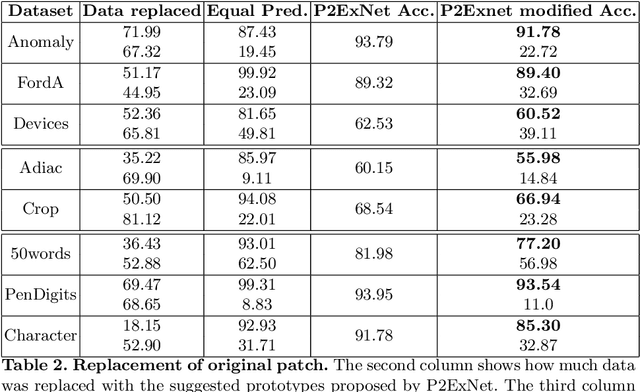
Deep learning methods have shown great success in several domains as they process a large amount of data efficiently, capable of solving complex classification, forecast, segmentation, and other tasks. However, they come with the inherent drawback of inexplicability limiting their applicability and trustworthiness. Although there exists work addressing this perspective, most of the existing approaches are limited to the image modality due to the intuitive and prominent concepts. Conversely, the concepts in the time-series domain are more complex and non-comprehensive but these and an explanation for the network decision are pivotal in critical domains like medical, financial, or industry. Addressing the need for an explainable approach, we propose a novel interpretable network scheme, designed to inherently use an explainable reasoning process inspired by the human cognition without the need of additional post-hoc explainability methods. Therefore, class-specific patches are used as they cover local concepts relevant to the classification to reveal similarities with samples of the same class. In addition, we introduce a novel loss concerning interpretability and accuracy that constraints P2ExNet to provide viable explanations of the data including relevant patches, their position, class similarities, and comparison methods without compromising accuracy. Analysis of the results on eight publicly available time-series datasets reveals that P2ExNet reaches comparable performance when compared to its counterparts while inherently providing understandable and traceable decisions.
ImpactCite: An XLNet-based method for Citation Impact Analysis
May 05, 2020
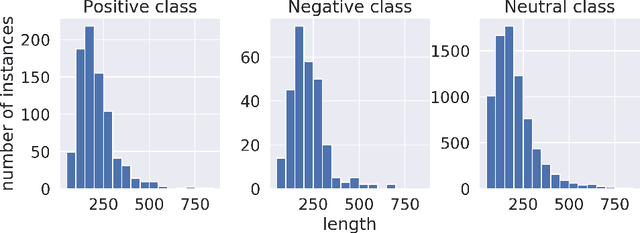
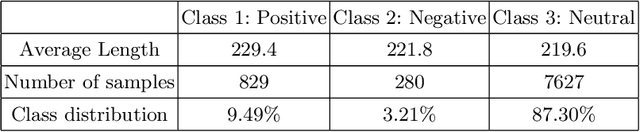
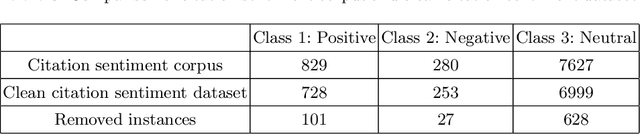
Citations play a vital role in understanding the impact of scientific literature. Generally, citations are analyzed quantitatively whereas qualitative analysis of citations can reveal deeper insights into the impact of a scientific artifact in the community. Therefore, citation impact analysis (which includes sentiment and intent classification) enables us to quantify the quality of the citations which can eventually assist us in the estimation of ranking and impact. The contribution of this paper is two-fold. First, we benchmark the well-known language models like BERT and ALBERT along with several popular networks for both tasks of sentiment and intent classification. Second, we provide ImpactCite, which is XLNet-based method for citation impact analysis. All evaluations are performed on a set of publicly available citation analysis datasets. Evaluation results reveal that ImpactCite achieves a new state-of-the-art performance for both citation intent and sentiment classification by outperforming the existing approaches by 3.44% and 1.33% in F1-score. Therefore, we emphasize ImpactCite (XLNet-based solution) for both tasks to better understand the impact of a citation. Additional efforts have been performed to come up with CSC-Clean corpus, which is a clean and reliable dataset for citation sentiment classification.
On Interpretability of Deep Learning based Skin Lesion Classifiers using Concept Activation Vectors
May 05, 2020
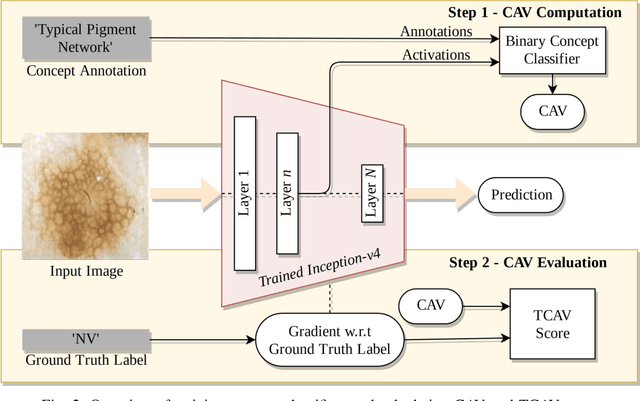
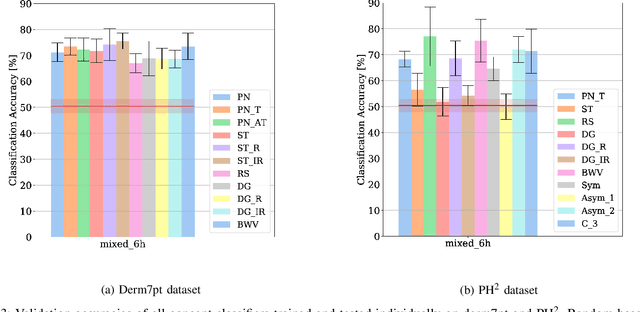
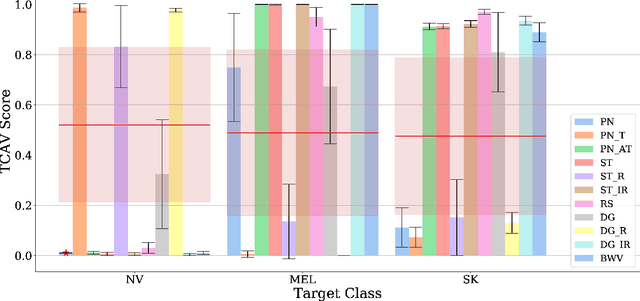
Deep learning based medical image classifiers have shown remarkable prowess in various application areas like ophthalmology, dermatology, pathology, and radiology. However, the acceptance of these Computer-Aided Diagnosis (CAD) systems in real clinical setups is severely limited primarily because their decision-making process remains largely obscure. This work aims at elucidating a deep learning based medical image classifier by verifying that the model learns and utilizes similar disease-related concepts as described and employed by dermatologists. We used a well-trained and high performing neural network developed by REasoning for COmplex Data (RECOD) Lab for classification of three skin tumours, i.e. Melanocytic Naevi, Melanoma and Seborrheic Keratosis and performed a detailed analysis on its latent space. Two well established and publicly available skin disease datasets, PH2 and derm7pt, are used for experimentation. Human understandable concepts are mapped to RECOD image classification model with the help of Concept Activation Vectors (CAVs), introducing a novel training and significance testing paradigm for CAVs. Our results on an independent evaluation set clearly shows that the classifier learns and encodes human understandable concepts in its latent representation. Additionally, TCAV scores (Testing with CAVs) suggest that the neural network indeed makes use of disease-related concepts in the correct way when making predictions. We anticipate that this work can not only increase confidence of medical practitioners on CAD but also serve as a stepping stone for further development of CAV-based neural network interpretation methods.
Explaining AI-based Decision Support Systems using Concept Localization Maps
May 04, 2020
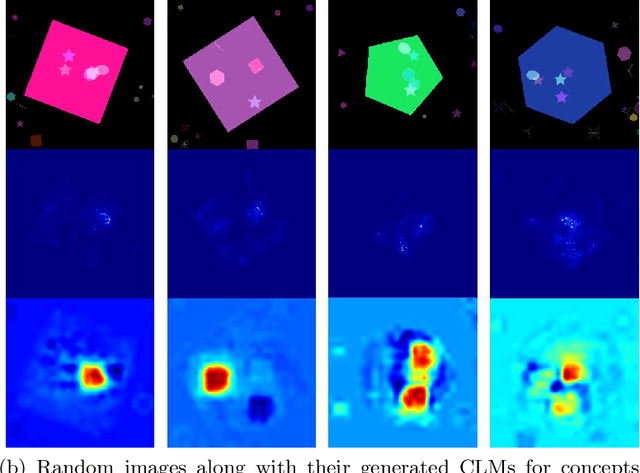
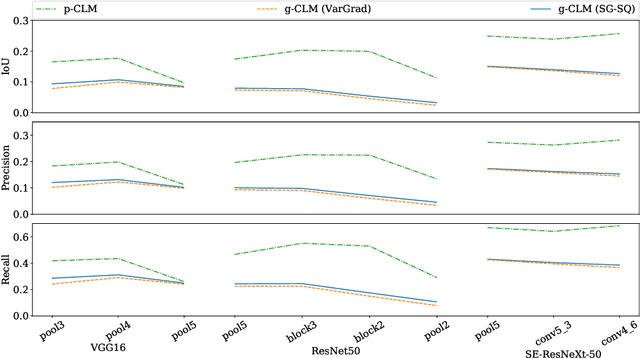

Human-centric explainability of AI-based Decision Support Systems (DSS) using visual input modalities is directly related to reliability and practicality of such algorithms. An otherwise accurate and robust DSS might not enjoy trust of experts in critical application areas if it is not able to provide reasonable justification of its predictions. This paper introduces Concept Localization Maps (CLMs), which is a novel approach towards explainable image classifiers employed as DSS. CLMs extend Concept Activation Vectors (CAVs) by locating significant regions corresponding to a learned concept in the latent space of a trained image classifier. They provide qualitative and quantitative assurance of a classifier's ability to learn and focus on similar concepts important for humans during image recognition. To better understand the effectiveness of the proposed method, we generated a new synthetic dataset called Simple Concept DataBase (SCDB) that includes annotations for 10 distinguishable concepts, and made it publicly available. We evaluated our proposed method on SCDB as well as a real-world dataset called CelebA. We achieved localization recall of above 80% for most relevant concepts and average recall above 60% for all concepts using SE-ResNeXt-50 on SCDB. Our results on both datasets show great promise of CLMs for easing acceptance of DSS in practice.
If You Like It, GAN It. Probabilistic Multivariate Times Series Forecast With GAN
May 03, 2020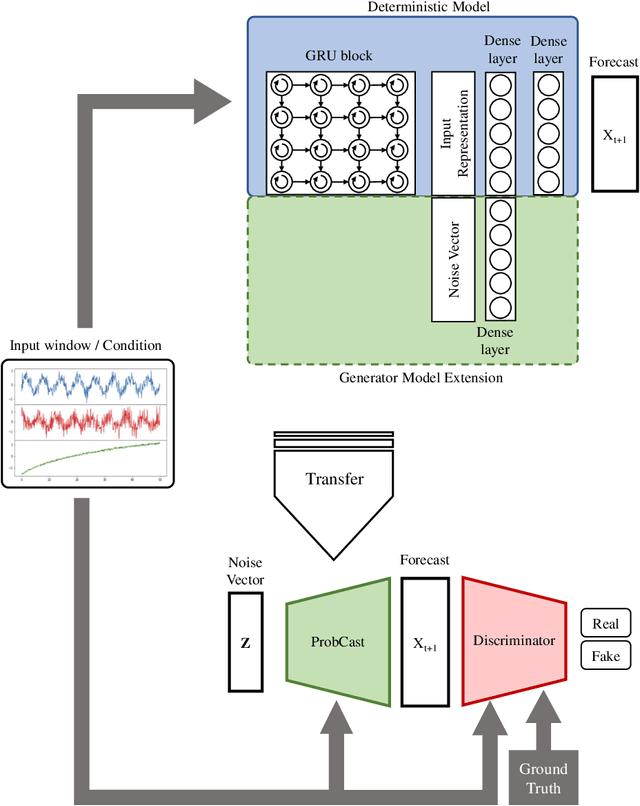

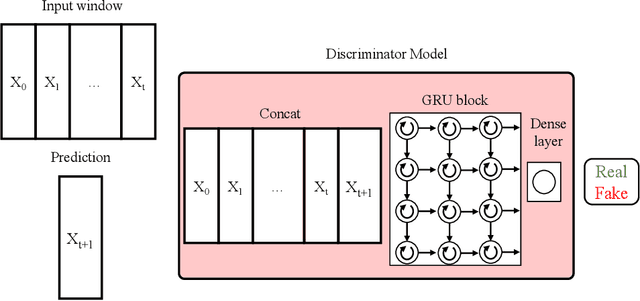
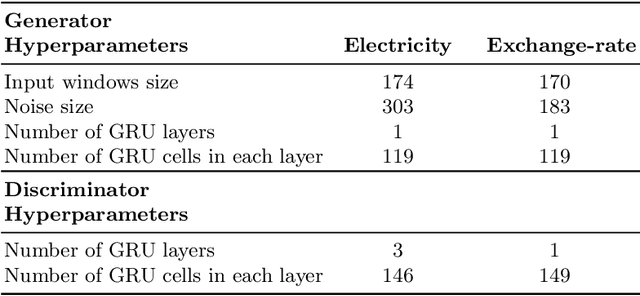
The contribution of this paper is two-fold. First, we present ProbCast - a novel probabilistic model for multivariate time-series forecasting. We employ a conditional GAN framework to train our model with adversarial training. Second, we propose a framework that lets us transform a deterministic model into a probabilistic one with improved performance. The motivation of the framework is to either transform existing highly accurate point forecast models to their probabilistic counterparts or to train GANs stably by selecting the architecture of GAN's component carefully and efficiently. We conduct experiments over two publicly available datasets namely electricity consumption dataset and exchange-rate dataset. The results of the experiments demonstrate the remarkable performance of our model as well as the successful application of our proposed framework.
DeepCFD: Efficient Steady-State Laminar Flow Approximation with Deep Convolutional Neural Networks
May 02, 2020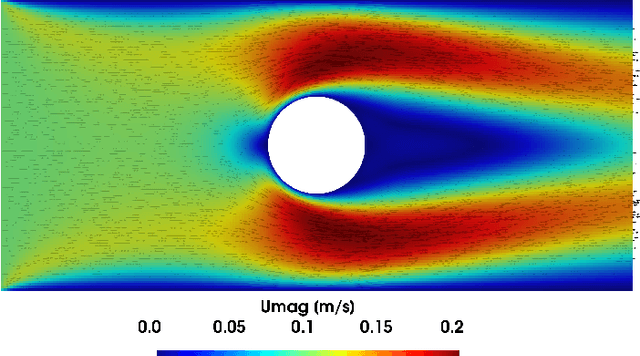
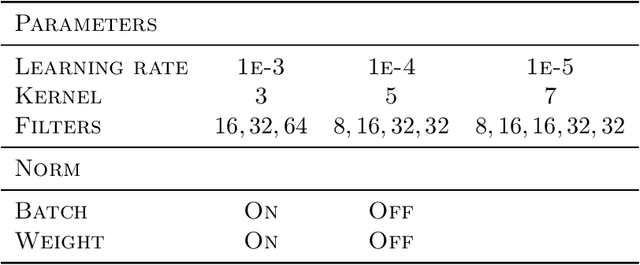
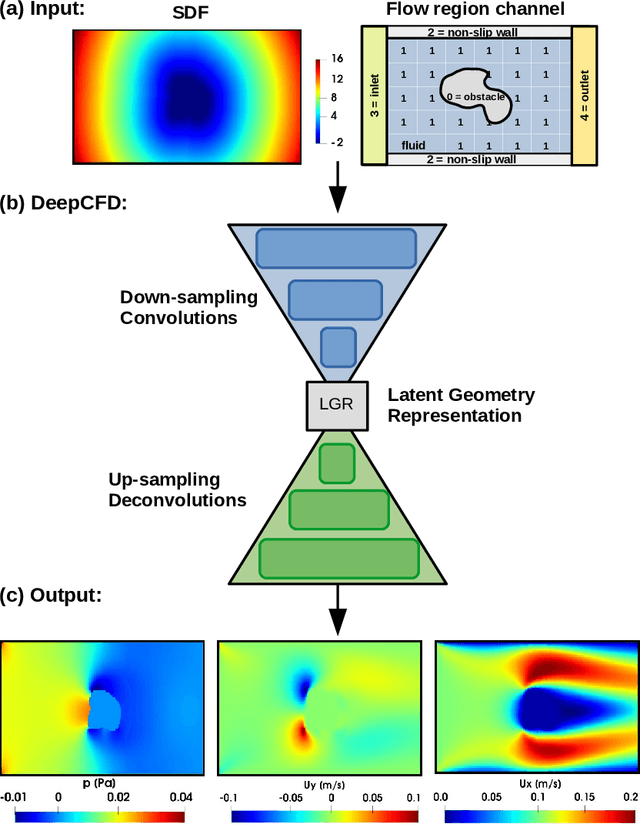
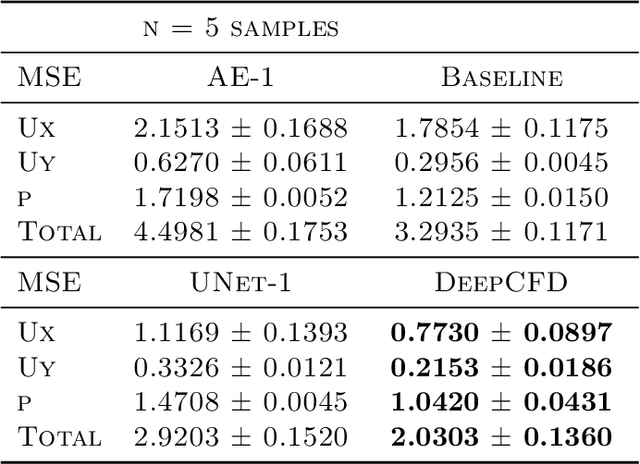
Computational Fluid Dynamics (CFD) simulation by the numerical solution of the Navier-Stokes equations is an essential tool in a wide range of applications from engineering design to climate modeling. However, the computational cost and memory demand required by CFD codes may become very high for flows of practical interest, such as in aerodynamic shape optimization. This expense is associated with the complexity of the fluid flow governing equations, which include non-linear partial derivative terms that are of difficult solution, leading to long computational times and limiting the number of hypotheses that can be tested during the process of iterative design. Therefore, we propose DeepCFD: a convolutional neural network (CNN) based model that efficiently approximates solutions for the problem of non-uniform steady laminar flows. The proposed model is able to learn complete solutions of the Navier-Stokes equations, for both velocity and pressure fields, directly from ground-truth data generated using a state-of-the-art CFD code. Using DeepCFD, we found a speedup of up to 3 orders of magnitude compared to the standard CFD approach at a cost of low error rates.
TSInsight: A local-global attribution framework for interpretability in time-series data
Apr 06, 2020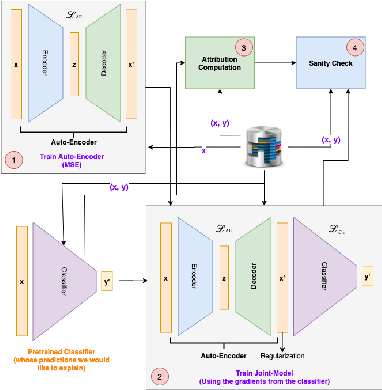
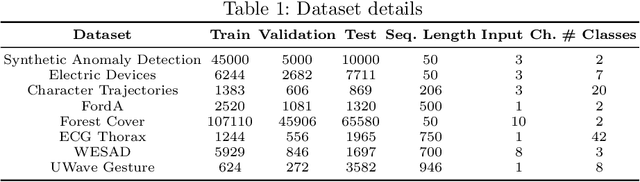
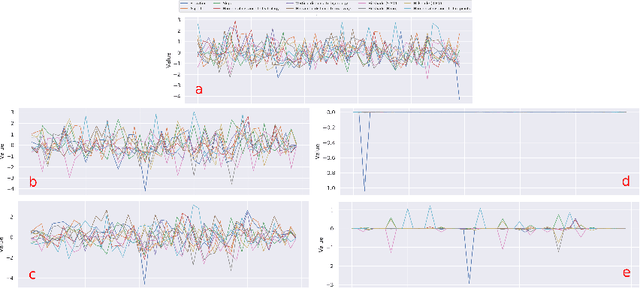
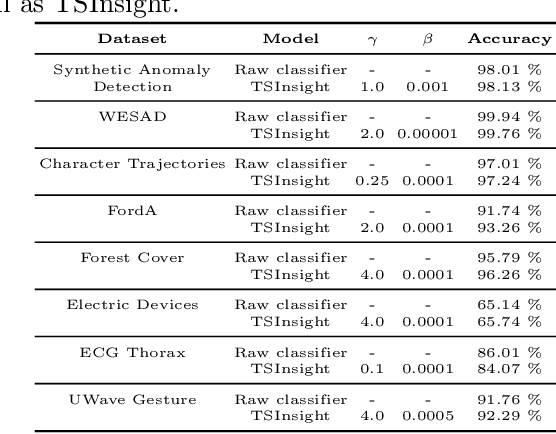
With the rise in the employment of deep learning methods in safety-critical scenarios, interpretability is more essential than ever before. Although many different directions regarding interpretability have been explored for visual modalities, time-series data has been neglected with only a handful of methods tested due to their poor intelligibility. We approach the problem of interpretability in a novel way by proposing TSInsight where we attach an auto-encoder to the classifier with a sparsity-inducing norm on its output and fine-tune it based on the gradients from the classifier and a reconstruction penalty. TSInsight learns to preserve features that are important for prediction by the classifier and suppresses those that are irrelevant i.e. serves as a feature attribution method to boost interpretability. In contrast to most other attribution frameworks, TSInsight is capable of generating both instance-based and model-based explanations. We evaluated TSInsight along with 9 other commonly used attribution methods on 8 different time-series datasets to validate its efficacy. Evaluation results show that TSInsight naturally achieves output space contraction, therefore, is an effective tool for the interpretability of deep time-series models.
A Robust and Precise ConvNet for small non-coding RNA classification
Dec 23, 2019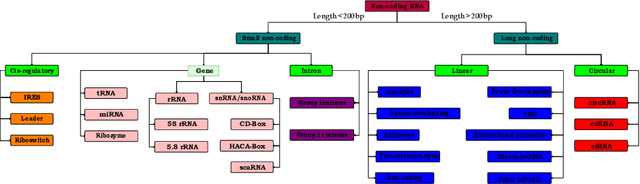
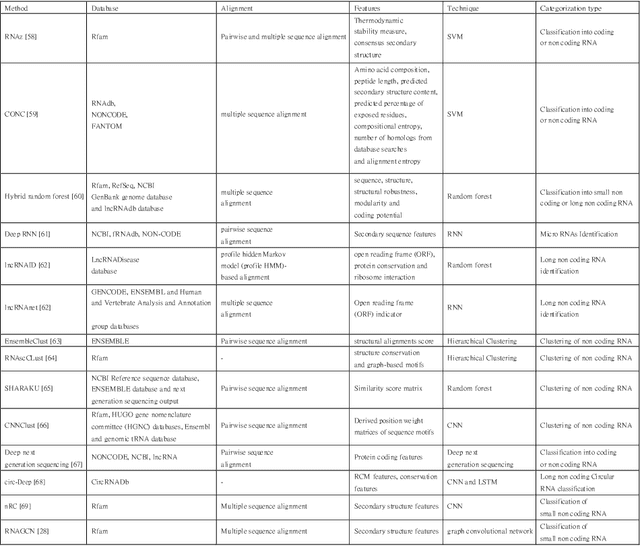
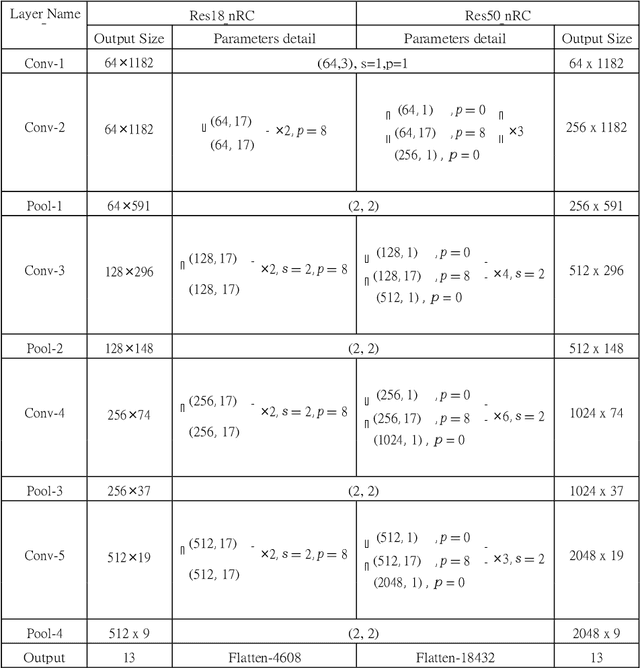
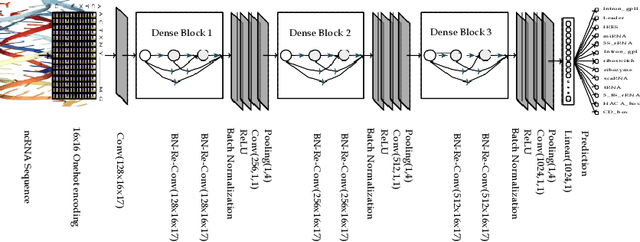
Functional or non-coding RNAs are attracting more attention as they are now potentially considered valuable resources in the development of new drugs intended to cure several human diseases. The identification of drugs targeting the regulatory circuits of functional RNAs depends on knowing its family, a task which is known as RNA sequence classification. State-of-the-art small noncoding RNA classification methodologies take secondary structural features as input. However, in such classification, feature extraction approaches only take global characteristics into account and completely oversight co-relative effect of local structures. Furthermore secondary structure based approaches incorporate high dimensional feature space which proves computationally expensive. This paper proposes a novel Robust and Precise ConvNet (RPC-snRC) methodology which classifies small non-coding RNAs sequences into their relevant families by utilizing the primary sequence of RNAs. RPC-snRC methodology learns hierarchical representation of features by utilizing positioning and occurrences information of nucleotides. To avoid exploding and vanishing gradient problems, we use an approach similar to DenseNet in which gradient can flow straight from subsequent layers to previous layers. In order to assess the effectiveness of deeper architectures for small non-coding RNA classification, we also adapted two ResNet architectures having different number of layers. Experimental results on a benchmark small non-coding RNA dataset show that our proposed methodology does not only outperform existing small non-coding RNA classification approaches with a significant performance margin of 10% but it also outshines adapted ResNet architectures.