 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExAID: A Multimodal Explanation Framework for Computer-Aided Diagnosis of Skin Lesions
Jan 04, 2022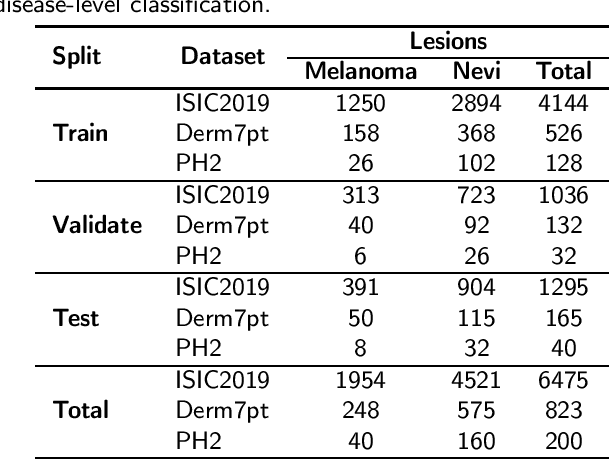
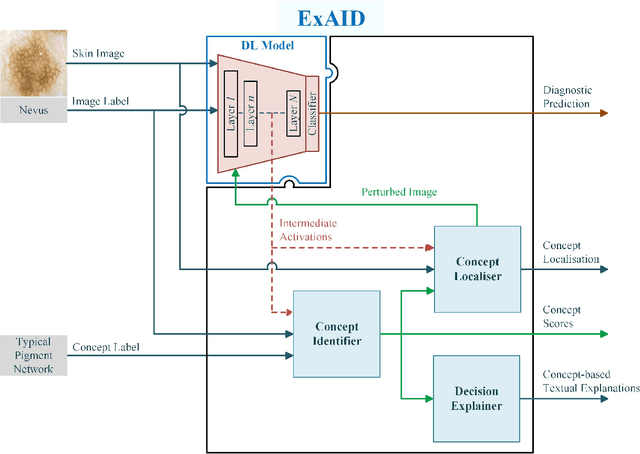
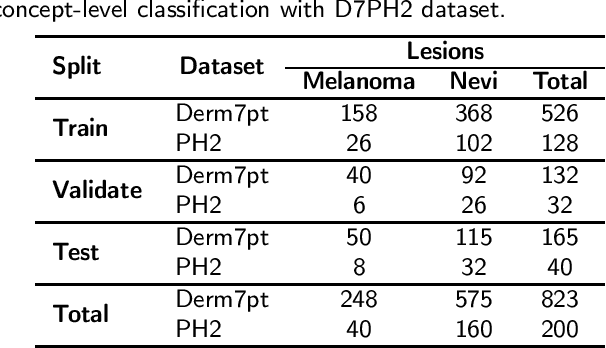
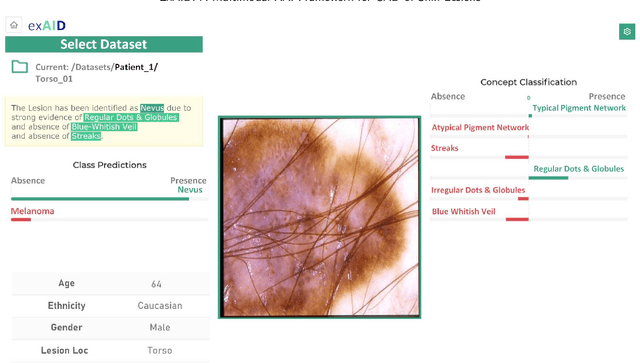
One principal impediment in the successful deployment of AI-based Computer-Aided Diagnosis (CAD) systems in clinical workflows is their lack of transparent decision making. Although commonly used eXplainable AI methods provide some insight into opaque algorithms, such explanations are usually convoluted and not readily comprehensible except by highly trained experts. The explanation of decisions regarding the malignancy of skin lesions from dermoscopic images demands particular clarity, as the underlying medical problem definition is itself ambiguous. This work presents ExAID (Explainable AI for Dermatology), a novel framework for biomedical image analysis, providing multi-modal concept-based explanations consisting of easy-to-understand textual explanations supplemented by visual maps justifying the predictions. ExAID relies on Concept Activation Vectors to map human concepts to those learnt by arbitrary Deep Learning models in latent space, and Concept Localization Maps to highlight concepts in the input space. This identification of relevant concepts is then used to construct fine-grained textual explanations supplemented by concept-wise location information to provide comprehensive and coherent multi-modal explanations. All information is comprehensively presented in a diagnostic interface for use in clinical routines. An educational mode provides dataset-level explanation statistics and tools for data and model exploration to aid medical research and education. Through rigorous quantitative and qualitative evaluation of ExAID, we show the utility of multi-modal explanations for CAD-assisted scenarios even in case of wrong predictions. We believe that ExAID will provide dermatologists an effective screening tool that they both understand and trust. Moreover, it will be the basis for similar applications in other biomedical imaging fields.
Evaluating Privacy-Preserving Machine Learning in Critical Infrastructures: A Case Study on Time-Series Classification
Nov 29, 2021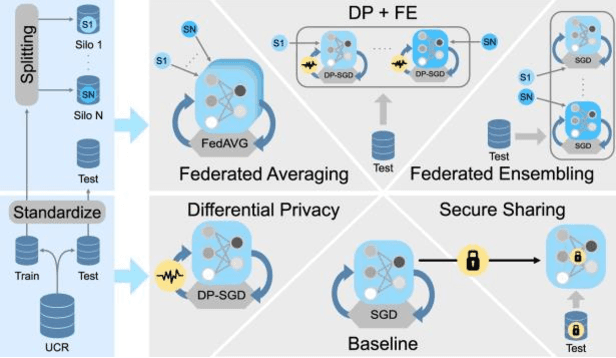
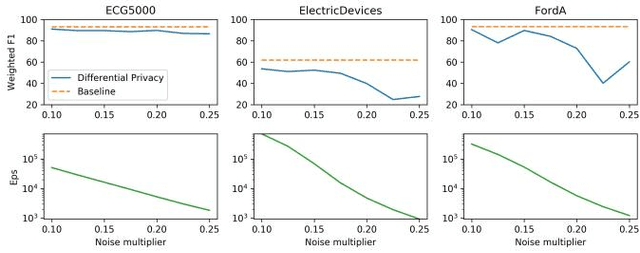
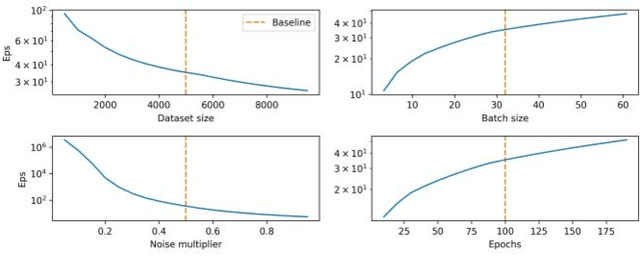
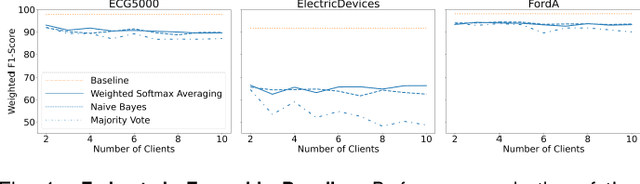
With the advent of machine learning in applications of critical infrastructure such as healthcare and energy, privacy is a growing concern in the minds of stakeholders. It is pivotal to ensure that neither the model nor the data can be used to extract sensitive information used by attackers against individuals or to harm whole societies through the exploitation of critical infrastructure. The applicability of machine learning in these domains is mostly limited due to a lack of trust regarding the transparency and the privacy constraints. Various safety-critical use cases (mostly relying on time-series data) are currently underrepresented in privacy-related considerations. By evaluating several privacy-preserving methods regarding their applicability on time-series data, we validated the inefficacy of encryption for deep learning, the strong dataset dependence of differential privacy, and the broad applicability of federated methods.
XAI Handbook: Towards a Unified Framework for Explainable AI
May 14, 2021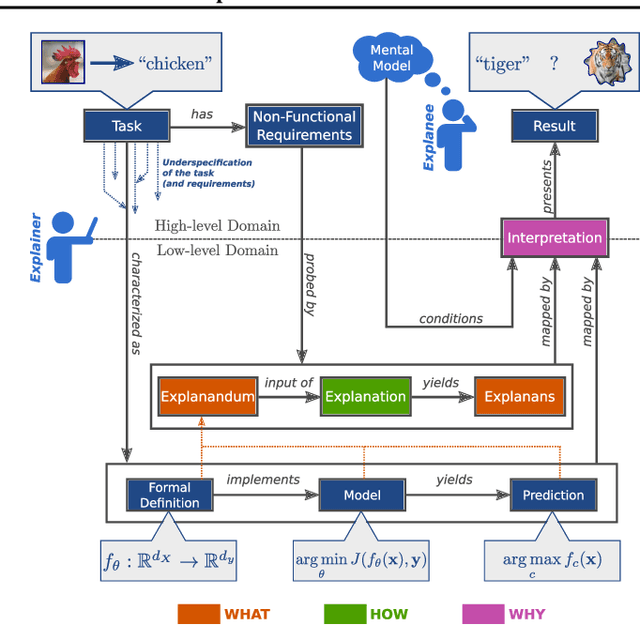
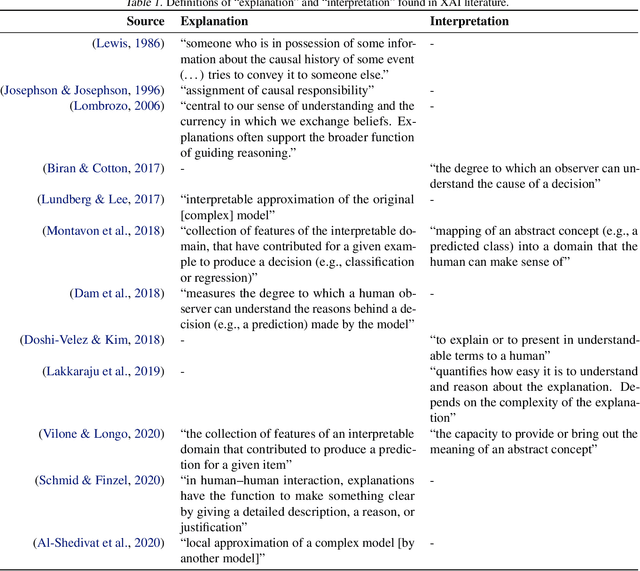

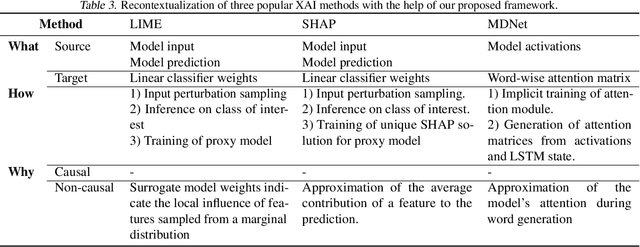
The field of explainable AI (XAI) has quickly become a thriving and prolific community. However, a silent, recurrent and acknowledged issue in this area is the lack of consensus regarding its terminology. In particular, each new contribution seems to rely on its own (and often intuitive) version of terms like "explanation" and "interpretation". Such disarray encumbers the consolidation of advances in the field towards the fulfillment of scientific and regulatory demands e.g., when comparing methods or establishing their compliance with respect to biases and fairness constraints. We propose a theoretical framework that not only provides concrete definitions for these terms, but it also outlines all steps necessary to produce explanations and interpretations. The framework also allows for existing contributions to be re-contextualized such that their scope can be measured, thus making them comparable to other methods. We show that this framework is compliant with desiderata on explanations, on interpretability and on evaluation metrics. We present a use-case showing how the framework can be used to compare LIME, SHAP and MDNet, establishing their advantages and shortcomings. Finally, we discuss relevant trends in XAI as well as recommendations for future work, all from the standpoint of our framework.
Deep Learning Based Decision Support for Medicine -- A Case Study on Skin Cancer Diagnosis
Mar 02, 2021
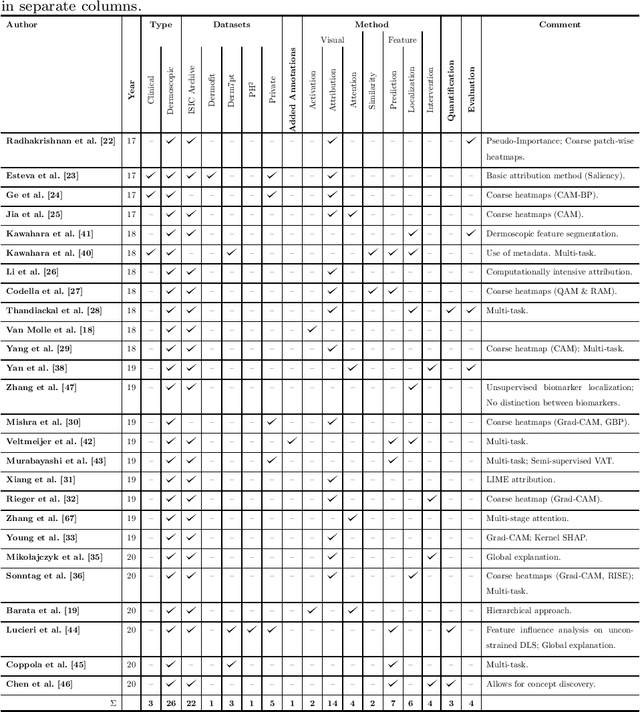
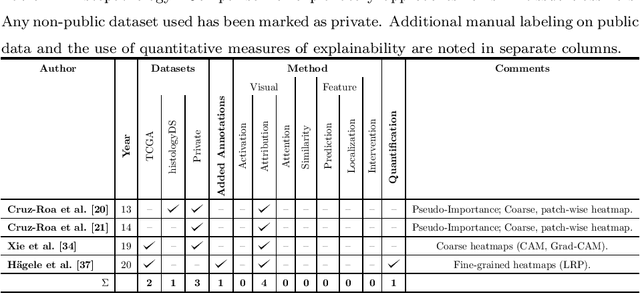
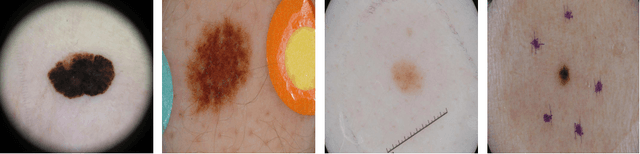
Early detection of skin cancers like melanoma is crucial to ensure high chances of survival for patients. Clinical application of Deep Learning (DL)-based Decision Support Systems (DSS) for skin cancer screening has the potential to improve the quality of patient care. The majority of work in the medical AI community focuses on a diagnosis setting that is mainly relevant for autonomous operation. Practical decision support should, however, go beyond plain diagnosis and provide explanations. This paper provides an overview of works towards explainable, DL-based decision support in medical applications with the example of skin cancer diagnosis from clinical, dermoscopic and histopathologic images. Analysis reveals that comparably little attention is payed to the explanation of histopathologic skin images and that current work is dominated by visual relevance maps as well as dermoscopic feature identification. We conclude that future work should focus on meeting the stakeholder's cognitive concepts, providing exhaustive explanations that combine global and local approaches and leverage diverse modalities. Moreover, the possibility to intervene and guide models in case of misbehaviour is identified as a major step towards successful deployment of AI as DL-based DSS and beyond.
PatchX: Explaining Deep Models by Intelligible Pattern Patches for Time-series Classification
Feb 11, 2021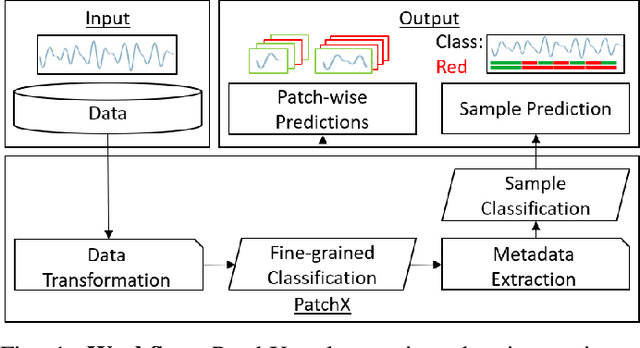
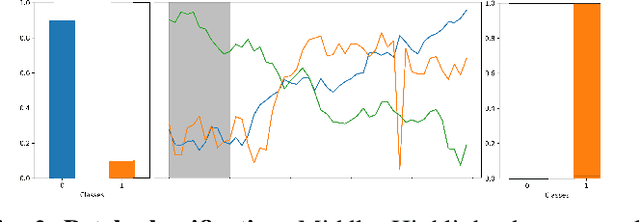
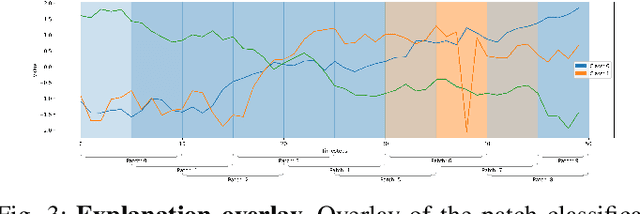
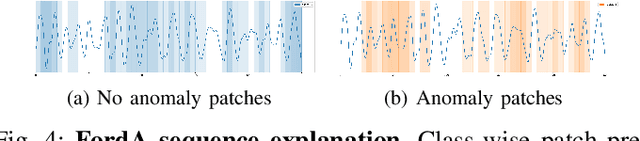
The classification of time-series data is pivotal for streaming data and comes with many challenges. Although the amount of publicly available datasets increases rapidly, deep neural models are only exploited in a few areas. Traditional methods are still used very often compared to deep neural models. These methods get preferred in safety-critical, financial, or medical fields because of their interpretable results. However, their performance and scale-ability are limited, and finding suitable explanations for time-series classification tasks is challenging due to the concepts hidden in the numerical time-series data. Visualizing complete time-series results in a cognitive overload concerning our perception and leads to confusion. Therefore, we believe that patch-wise processing of the data results in a more interpretable representation. We propose a novel hybrid approach that utilizes deep neural networks and traditional machine learning algorithms to introduce an interpretable and scale-able time-series classification approach. Our method first performs a fine-grained classification for the patches followed by sample level classification.
Reliable Model Compression via Label-Preservation-Aware Loss Functions
Dec 03, 2020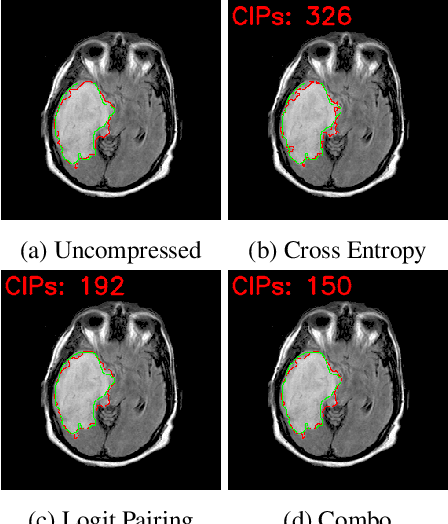
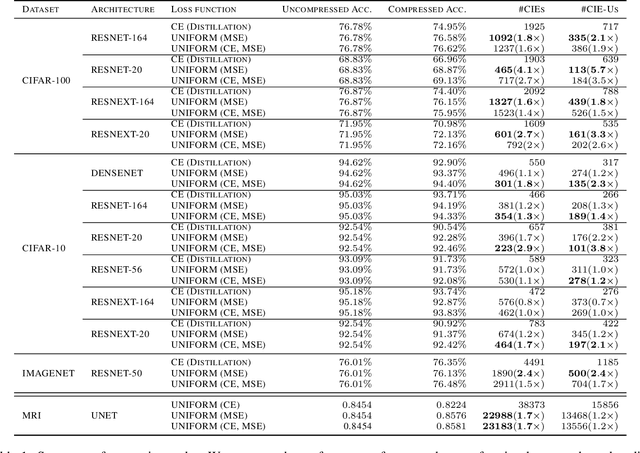
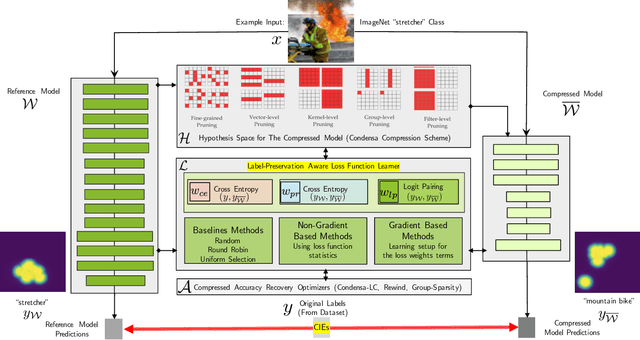
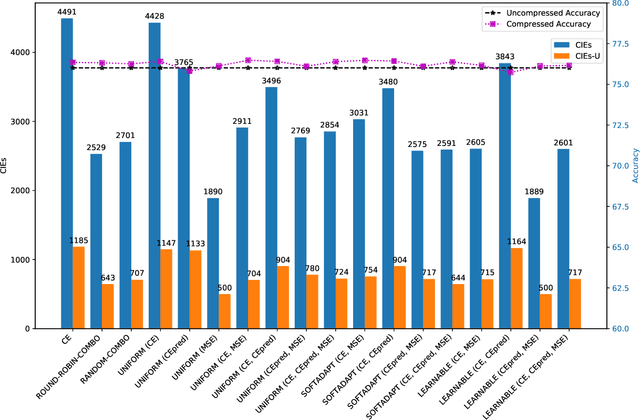
Model compression is a ubiquitous tool that brings the power of modern deep learning to edge devices with power and latency constraints. The goal of model compression is to take a large reference neural network and output a smaller and less expensive compressed network that is functionally equivalent to the reference. Compression typically involves pruning and/or quantization, followed by re-training to maintain the reference accuracy. However, it has been observed that compression can lead to a considerable mismatch in the labels produced by the reference and the compressed models, resulting in bias and unreliability. To combat this, we present a framework that uses a teacher-student learning paradigm to better preserve labels. We investigate the role of additional terms to the loss function and show how to automatically tune the associated parameters. We demonstrate the effectiveness of our approach both quantitatively and qualitatively on multiple compression schemes and accuracy recovery algorithms using a set of 8 different real-world network architectures. We obtain a significant reduction of up to 4.1X in the number of mismatches between the compressed and reference models, and up to 5.7X in cases where the reference model makes the correct prediction.
Achievements and Challenges in Explaining Deep Learning based Computer-Aided Diagnosis Systems
Nov 26, 2020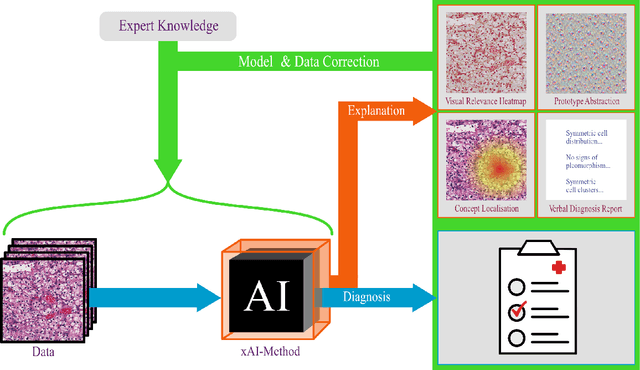
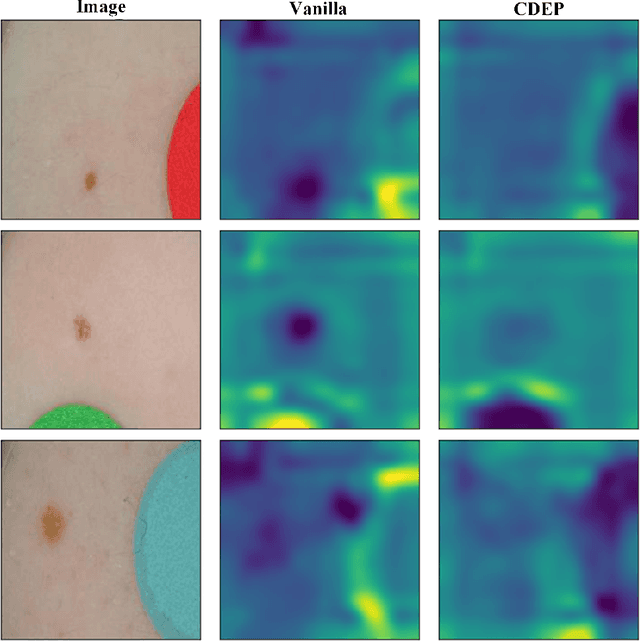
Remarkable success of modern image-based AI methods and the resulting interest in their applications in critical decision-making processes has led to a surge in efforts to make such intelligent systems transparent and explainable. The need for explainable AI does not stem only from ethical and moral grounds but also from stricter legislation around the world mandating clear and justifiable explanations of any decision taken or assisted by AI. Especially in the medical context where Computer-Aided Diagnosis can have a direct influence on the treatment and well-being of patients, transparency is of utmost importance for safe transition from lab research to real world clinical practice. This paper provides a comprehensive overview of current state-of-the-art in explaining and interpreting Deep Learning based algorithms in applications of medical research and diagnosis of diseases. We discuss early achievements in development of explainable AI for validation of known disease criteria, exploration of new potential biomarkers, as well as methods for the subsequent correction of AI models. Various explanation methods like visual, textual, post-hoc, ante-hoc, local and global have been thoroughly and critically analyzed. Subsequently, we also highlight some of the remaining challenges that stand in the way of practical applications of AI as a clinical decision support tool and provide recommendations for the direction of future research.
Benchmarking adversarial attacks and defenses for time-series data
Aug 30, 2020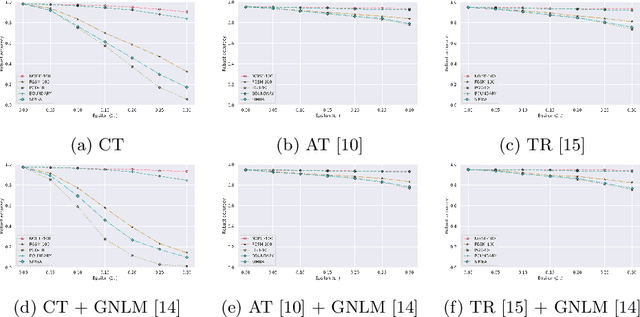
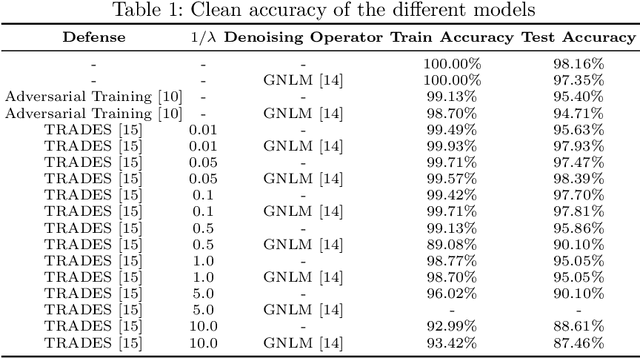
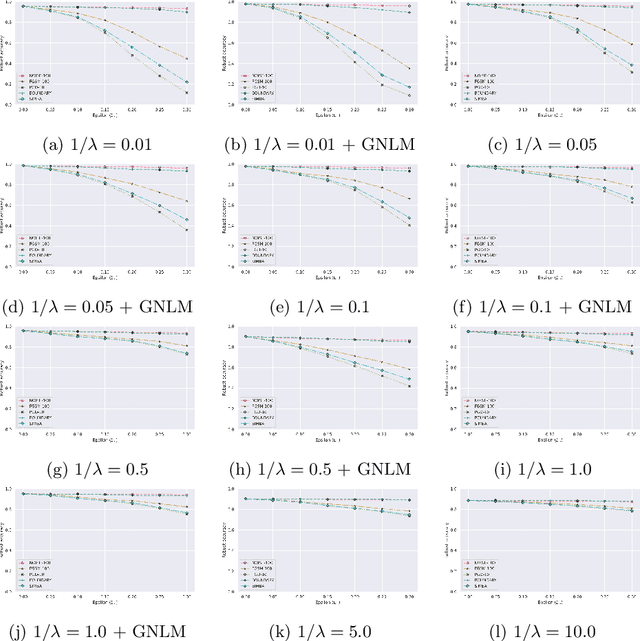
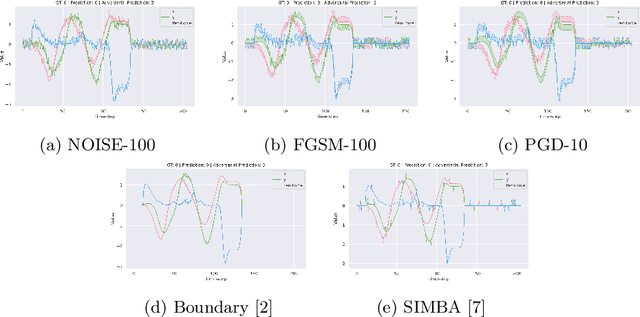
The adversarial vulnerability of deep networks has spurred the interest of researchers worldwide. Unsurprisingly, like images, adversarial examples also translate to time-series data as they are an inherent weakness of the model itself rather than the modality. Several attempts have been made to defend against these adversarial attacks, particularly for the visual modality. In this paper, we perform detailed benchmarking of well-proven adversarial defense methodologies on time-series data. We restrict ourselves to the $L_{\infty}$ threat model. We also explore the trade-off between smoothness and clean accuracy for regularization-based defenses to better understand the trade-offs that they offer. Our analysis shows that the explored adversarial defenses offer robustness against both strong white-box as well as black-box attacks. This paves the way for future research in the direction of adversarial attacks and defenses, particularly for time-series data.
Combining Fine- and Coarse-Grained Classifiers for Diabetic Retinopathy Detection
May 28, 2020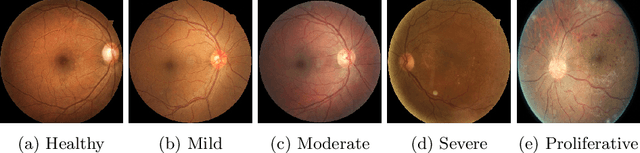
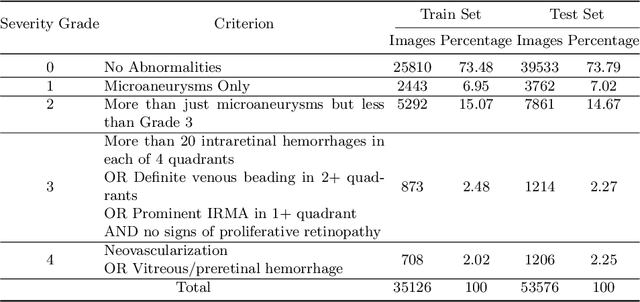
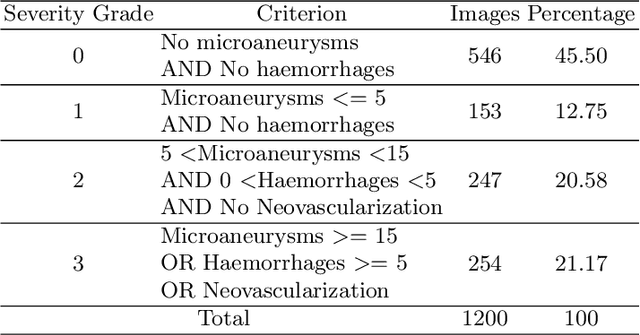
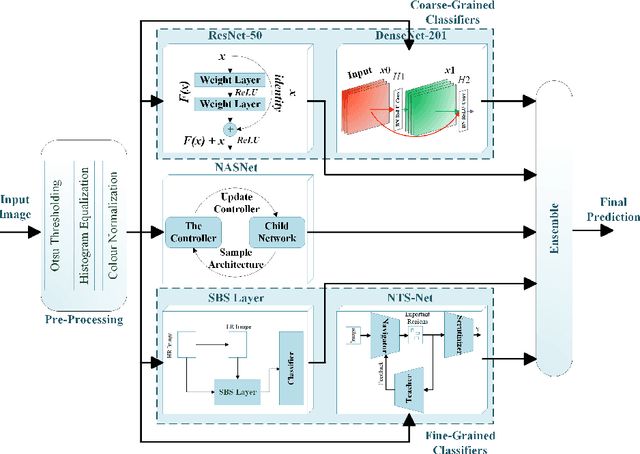
Visual artefacts of early diabetic retinopathy in retinal fundus images are usually small in size, inconspicuous, and scattered all over retina. Detecting diabetic retinopathy requires physicians to look at the whole image and fixate on some specific regions to locate potential biomarkers of the disease. Therefore, getting inspiration from ophthalmologist, we propose to combine coarse-grained classifiers that detect discriminating features from the whole images, with a recent breed of fine-grained classifiers that discover and pay particular attention to pathologically significant regions. To evaluate the performance of this proposed ensemble, we used publicly available EyePACS and Messidor datasets. Extensive experimentation for binary, ternary and quaternary classification shows that this ensemble largely outperforms individual image classifiers as well as most of the published works in most training setups for diabetic retinopathy detection. Furthermore, the performance of fine-grained classifiers is found notably superior than coarse-grained image classifiers encouraging the development of task-oriented fine-grained classifiers modelled after specialist ophthalmologists.
Two-stage framework for optic disc localization and glaucoma classification in retinal fundus images using deep learning
May 28, 2020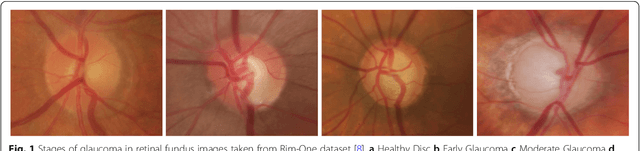
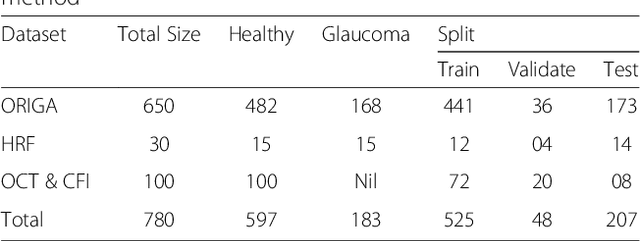
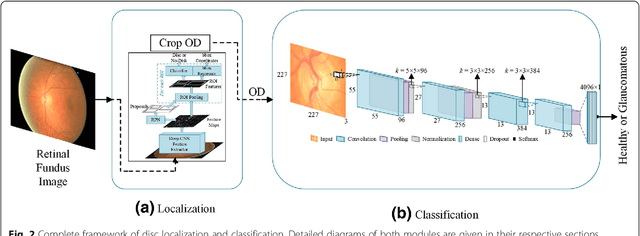
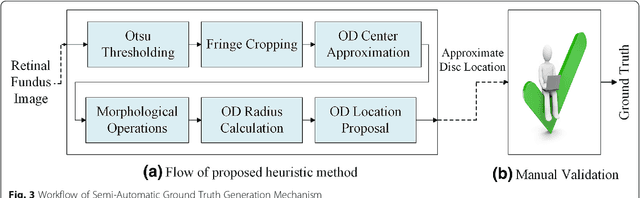
With the advancement of powerful image processing and machine learning techniques, CAD has become ever more prevalent in all fields of medicine including ophthalmology. Since optic disc is the most important part of retinal fundus image for glaucoma detection, this paper proposes a two-stage framework that first detects and localizes optic disc and then classifies it into healthy or glaucomatous. The first stage is based on RCNN and is responsible for localizing and extracting optic disc from a retinal fundus image while the second stage uses Deep CNN to classify the extracted disc into healthy or glaucomatous. In addition to the proposed solution, we also developed a rule-based semi-automatic ground truth generation method that provides necessary annotations for training RCNN based model for automated disc localization. The proposed method is evaluated on seven publicly available datasets for disc localization and on ORIGA dataset, which is the largest publicly available dataset for glaucoma classification. The results of automatic localization mark new state-of-the-art on six datasets with accuracy reaching 100% on four of them. For glaucoma classification we achieved AUC equal to 0.874 which is 2.7% relative improvement over the state-of-the-art results previously obtained for classification on ORIGA. Once trained on carefully annotated data, Deep Learning based methods for optic disc detection and localization are not only robust, accurate and fully automated but also eliminates the need for dataset-dependent heuristic algorithms. Our empirical evaluation of glaucoma classification on ORIGA reveals that reporting only AUC, for datasets with class imbalance and without pre-defined train and test splits, does not portray true picture of the classifier's performance and calls for additional performance metrics to substantiate the results.
* 16 Pages, 10 Figures