 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYPE: Human eYe Perceptual Evaluation of Generative Models
Apr 24, 2019


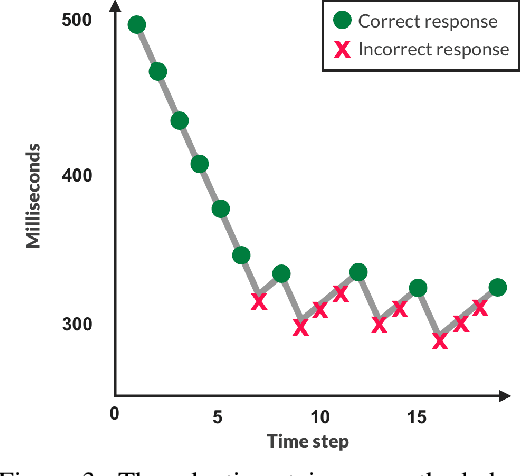
Generative models often use human evaluations to determine and justify progress. Unfortunately, existing human evaluation methods are ad-hoc: there is currently no standardized, validated evaluation that: (1) measures perceptual fidelity, (2) is reliable, (3) separates models into clear rank order, and (4) ensures high-quality measurement without intractable cost. In response, we construct Human-eYe Perceptual Evaluation (HYPE), a human metric that is (1) grounded in psychophysics research in perception, (2) reliable across different sets of randomly sampled outputs from a model, (3) results in separable model performances, and (4) efficient in cost and time. We introduce two methods. The first, HYPE-Time, measures visual perception under adaptive time constraints to determine the minimum length of time (e.g., 250ms) that model output such as a generated face needs to be visible for people to distinguish it as real or fake. The second, HYPE-Infinity, measures human error rate on fake and real images with no time constraints, maintaining stability and drastically reducing time and cost. We test HYPE across four state-of-the-art generative adversarial networks (GANs) on unconditional image generation using two datasets, the popular CelebA and the newer higher-resolution FFHQ, and two sampling techniques of model outputs. By simulating HYPE's evaluation multiple times, we demonstrate consistent ranking of different models, identifying StyleGAN with truncation trick sampling (27.6% HYPE-Infinity deception rate, with roughly one quarter of images being misclassified by humans) as superior to StyleGAN without truncation (19.0%) on FFHQ. See https://hype.stanford.edu for details.