 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodic features improve sentence segmentation and parsing
Feb 23, 2023Parsing spoken dialogue presents challenges that parsing text does not, including a lack of clear sentence boundaries. We know from previous work that prosody helps in parsing single sentences (Tran et al. 2018), but we want to show the effect of prosody on parsing speech that isn't segmented into sentences. In experiments on the English Switchboard corpus, we find prosody helps our model both with parsing and with accurately identifying sentence boundaries. However, we find that the best-performing parser is not necessarily the parser that produces the best sentence segmentation performance. We suggest that the best parses instead come from modelling sentence boundaries jointly with other constituent boundaries.
Analyzing Acoustic Word Embeddings from Pre-trained Self-supervised Speech Models
Oct 28, 2022



Given the strong results of self-supervised models on various tasks, there have been surprisingly few studies exploring self-supervised representations for acoustic word embeddings (AWE), fixed-dimensional vectors representing variable-length spoken word segments. In this work, we study several pre-trained models and pooling methods for constructing AWEs with self-supervised representations. Owing to the contextualized nature of self-supervised representations, we hypothesize that simple pooling methods, such as averaging, might already be useful for constructing AWEs. When evaluating on a standard word discrimination task, we find that HuBERT representations with mean-pooling rival the state of the art on English AWEs. More surprisingly, despite being trained only on English, HuBERT representations evaluated on Xitsonga, Mandarin, and French consistently outperform the multilingual model XLSR-53 (as well as Wav2Vec 2.0 trained on English).
Cross-linguistically Consistent Semantic and Syntactic Annotation of Child-directed Speech
Sep 22, 2021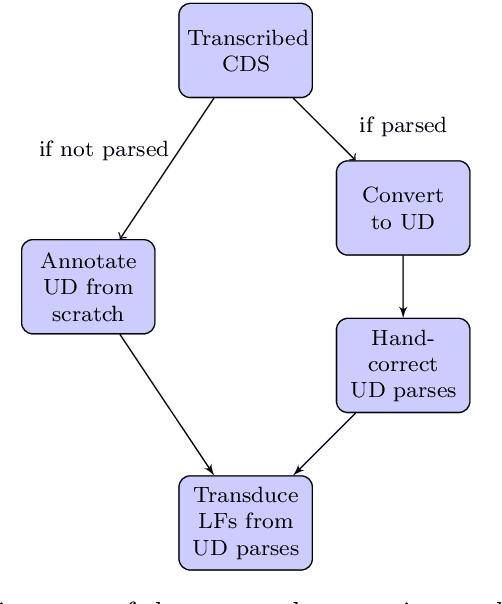
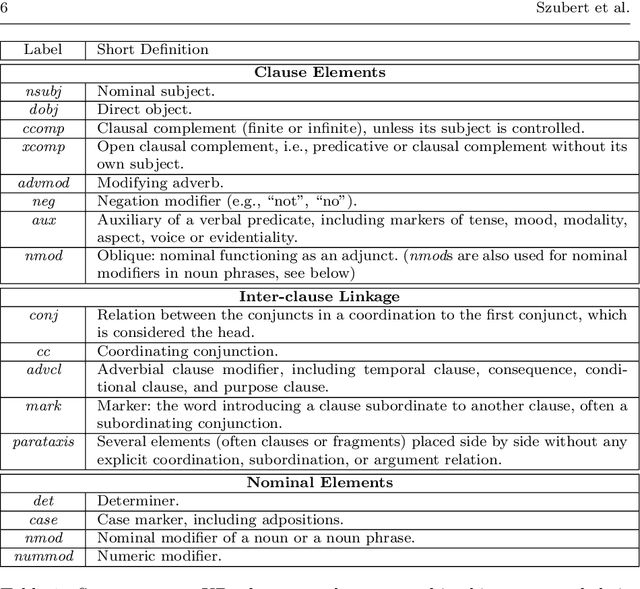
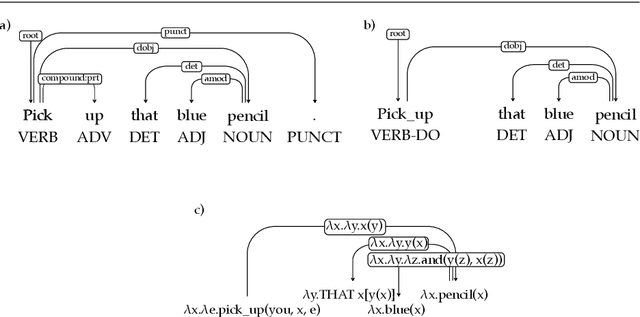
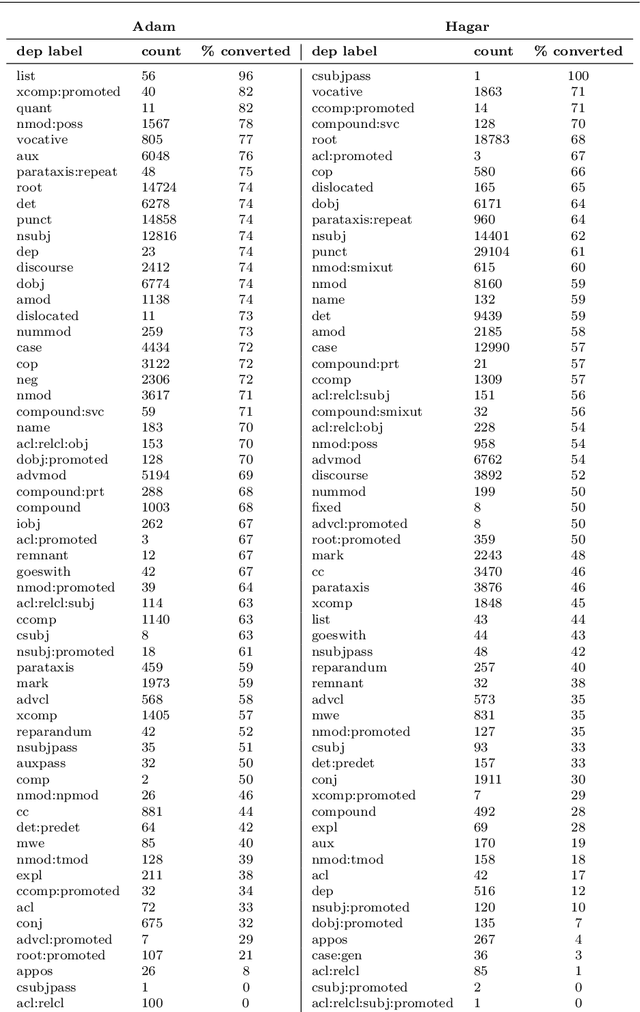
While corpora of child speech and child-directed speech (CDS) have enabled major contributions to the study of child language acquisition, semantic annotation for such corpora is still scarce and lacks a uniform standard. We compile two CDS corpora with sentential logical forms, one in English and the other in Hebrew. In compiling the corpora we employ a methodology that enforces a cross-linguistically consistent representation, building on recent advances in dependency representation and semantic parsing. The corpora are based on a sizable portion of Brown's Adam corpus from CHILDES (about 80% of its child-directed utterances), and to all child-directed utterances from Berman's Hebrew CHILDES corpus Hagar. We begin by annotating the corpora with the Universal Dependencies (UD) scheme for syntactic annotation, motivated by its applicability to a wide variety of domains and languages. We then proceed by applying an automatic method for transducing sentential logical forms (LFs) from UD structures. The two representations have complementary strengths: UD structures are language-neutral and support direct annotation, whereas LFs are neutral as to the interface between syntax and semantics, and transparently encode semantic distinctions. We verify the quality of the annotated UD annotation using an inter-annotator agreement study. We then demonstrate the utility of the compiled corpora through a longitudinal corpus study of the prevalence of different syntactic and semantic phenomena.
On the Difficulty of Segmenting Words with Attention
Sep 21, 2021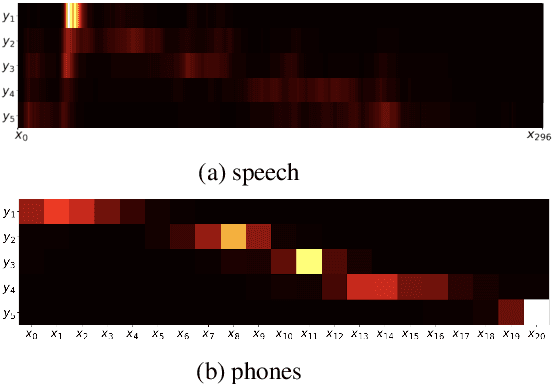

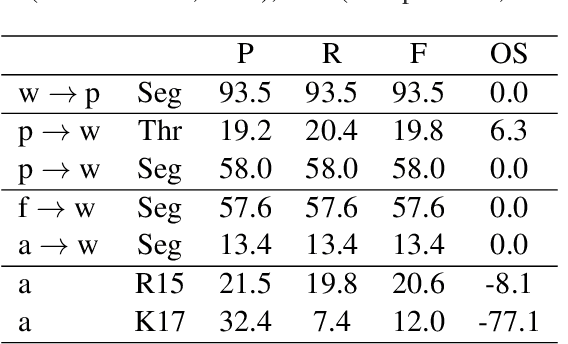
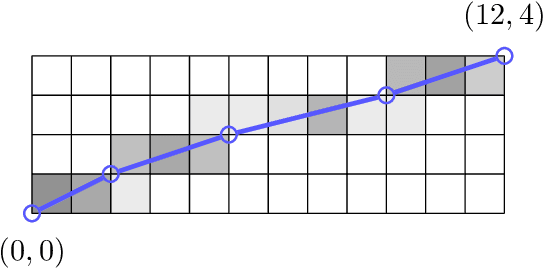
Word segmentation, the problem of finding word boundaries in speech, is of interest for a range of tasks. Previous papers have suggested that for sequence-to-sequence models trained on tasks such as speech translation or speech recognition, attention can be used to locate and segment the words. We show, however, that even on monolingual data this approach is brittle. In our experiments with different input types, data sizes, and segmentation algorithms, only models trained to predict phones from words succeed in the task. Models trained to predict words from either phones or speech (i.e., the opposite direction needed to generalize to new data), yield much worse results, suggesting that attention-based segmentation is only useful in limited scenarios.
Prosodic segmentation for parsing spoken dialogue
May 26, 2021
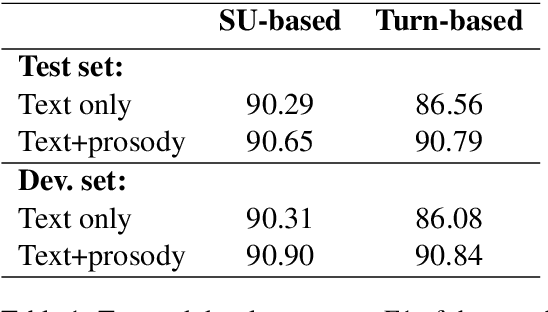
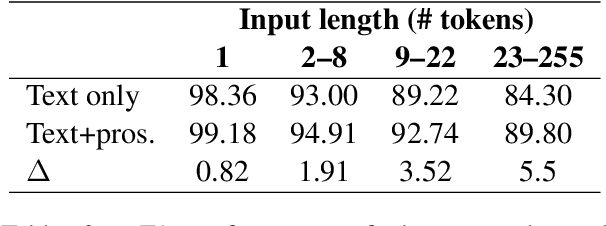
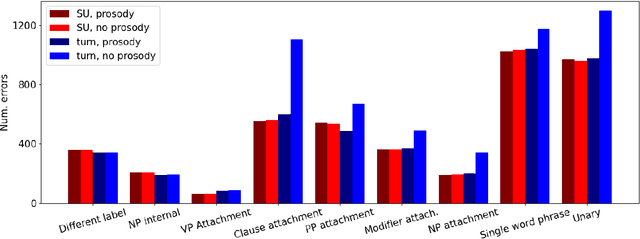
Parsing spoken dialogue poses unique difficulties, including disfluencies and unmarked boundaries between sentence-like units. Previous work has shown that prosody can help with parsing disfluent speech (Tran et al. 2018), but has assumed that the input to the parser is already segmented into sentence-like units (SUs), which isn't true in existing speech applications. We investigate how prosody affects a parser that receives an entire dialogue turn as input (a turn-based model), instead of gold standard pre-segmented SUs (an SU-based model). In experiments on the English Switchboard corpus, we find that when using transcripts alone, the turn-based model has trouble segmenting SUs, leading to worse parse performance than the SU-based model. However, prosody can effectively replace gold standard SU boundaries: with prosody, the turn-based model performs as well as the SU-based model (90.79 vs. 90.65 F1 score, respectively), despite performing two tasks (SU segmentation and parsing) rather than one (parsing alone). Analysis shows that pitch and intensity features are the most important for this corpus, since they allow the model to correctly distinguish an SU boundary from a speech disfluency -- a distinction that the model otherwise struggles to make.
Black or White but never neutral: How readers perceive identity from yellow or skin-toned emoji
May 12, 2021Research in sociology and linguistics shows that people use language not only to express their own identity but to understand the identity of others. Recent work established a connection between expression of identity and emoji usage on social media, through use of emoji skin tone modifiers. Motivated by that finding, this work asks if, as with language, readers are sensitive to such acts of self-expression and use them to understand the identity of authors. In behavioral experiments (n=488), where text and emoji content of social media posts were carefully controlled before being presented to participants, we find in the affirmative -- emoji are a salient signal of author identity. That signal is distinct from, and complementary to, the one encoded in language. Participant groups (based on self-identified ethnicity) showed no differences in how they perceive this signal, except in the case of the default yellow emoji. While both groups associate this with a White identity, the effect was stronger in White participants. Our finding that emoji can index social variables will have experimental applications for researchers but also implications for designers: supposedly ``neutral`` defaults may be more representative of some users than others.
Identity Signals in Emoji Do not Influence Perception of Factual Truth on Twitter
May 07, 2021
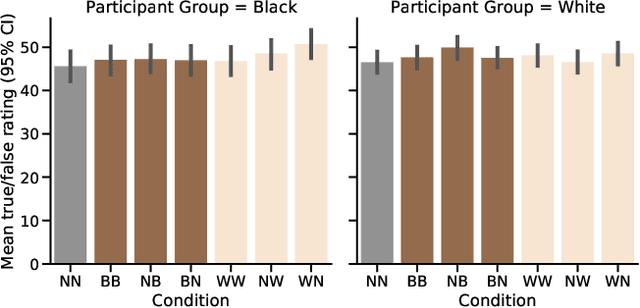
Prior work has shown that Twitter users use skin-toned emoji as an act of self-representation to express their racial/ethnic identity. We test whether this signal of identity can influence readers' perceptions about the content of a post containing that signal. In a large scale (n=944) pre-registered controlled experiment, we manipulate the presence of skin-toned emoji and profile photos in a task where readers rate obscure trivia facts (presented as tweets) as true or false. Using a Bayesian statistical analysis, we find that neither emoji nor profile photo has an effect on how readers rate these facts. This result will be of some comfort to anyone concerned about the manipulation of online users through the crafting of fake profiles.
A phonetic model of non-native spoken word processing
Jan 27, 2021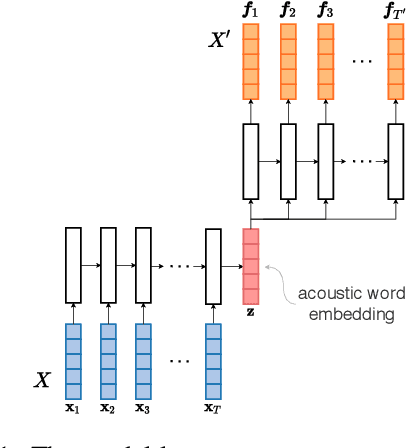
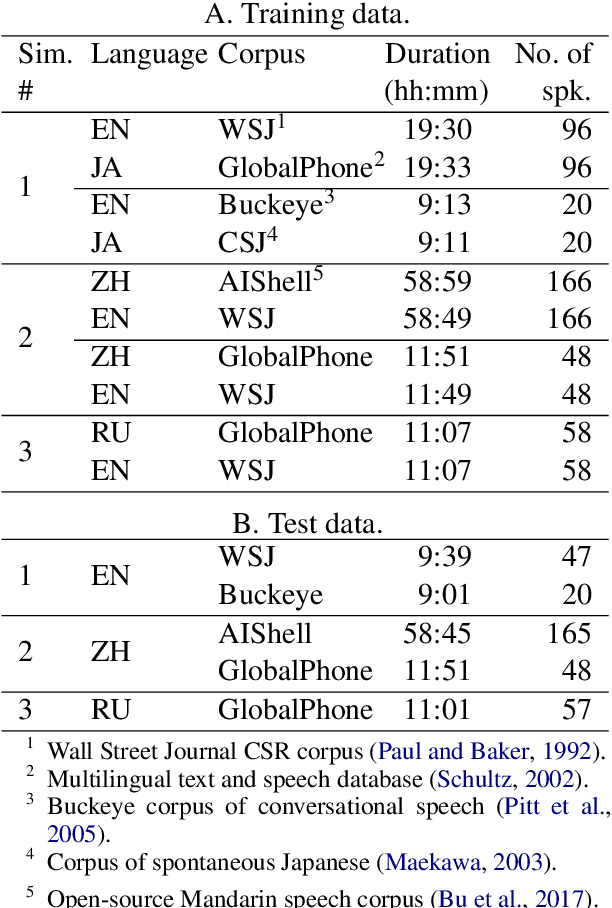
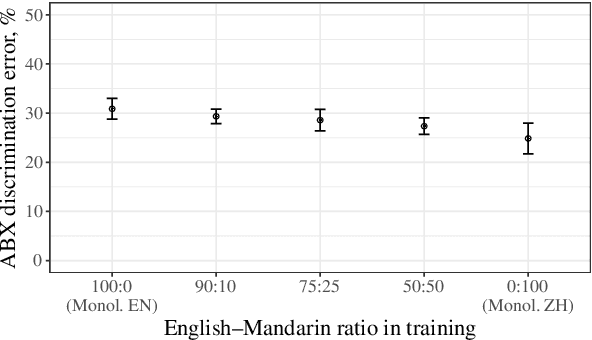
Non-native speakers show difficulties with spoken word processing. Many studies attribute these difficulties to imprecise phonological encoding of words in the lexical memory. We test an alternative hypothesis: that some of these difficulties can arise from the non-native speakers' phonetic perception. We train a computational model of phonetic learning, which has no access to phonology, on either one or two languages. We first show that the model exhibits predictable behaviors on phone-level and word-level discrimination tasks. We then test the model on a spoken word processing task, showing that phonology may not be necessary to explain some of the word processing effects observed in non-native speakers. We run an additional analysis of the model's lexical representation space, showing that the two training languages are not fully separated in that space, similarly to the languages of a bilingual human speaker.
LemMED: Fast and Effective Neural Morphological Analysis with Short Context Windows
Oct 21, 2020
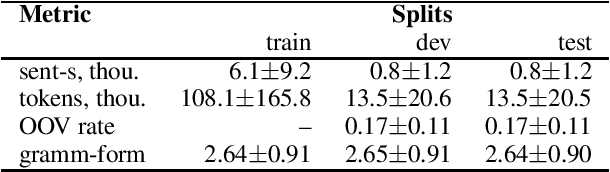
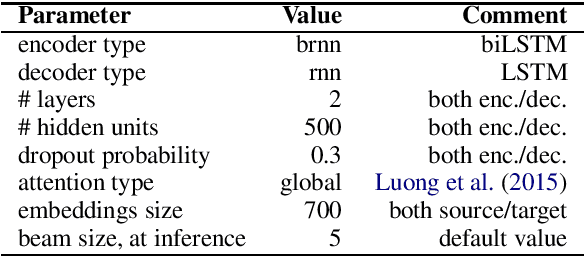
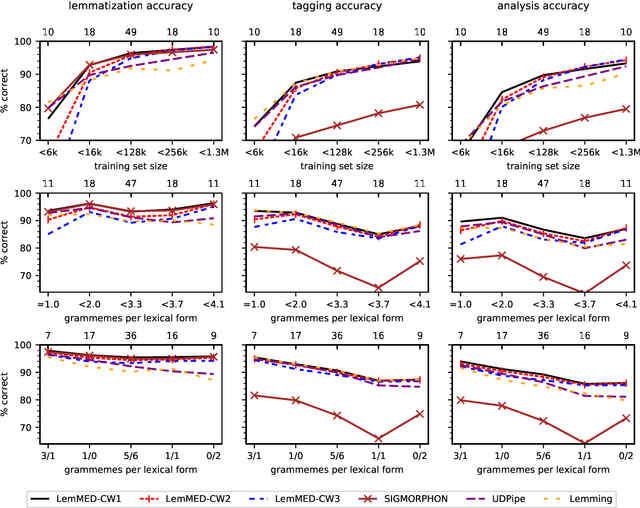
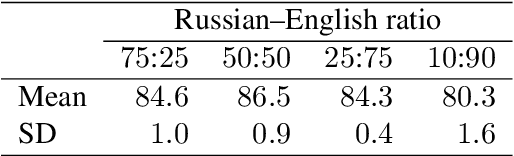
We present LemMED, a character-level encoder-decoder for contextual morphological analysis (combined lemmatization and tagging). LemMED extends and is named after two other attention-based models, namely Lematus, a contextual lemmatizer, and MED, a morphological (re)inflection model. Our approach does not require training separate lemmatization and tagging models, nor does it need additional resources and tools, such as morphological dictionaries or transducers. Moreover, LemMED relies solely on character-level representations and on local context. Although the model can, in principle, account for global context on sentence level, our experiments show that using just a single word of context around each target word is not only more computationally feasible, but yields better results as well. We evaluate LemMED in the framework of the SIMGMORPHON-2019 shared task on combined lemmatization and tagging. In terms of average performance LemMED ranks 5th among 13 systems and is bested only by the submissions that use contextualized embeddings.
Evaluating computational models of infant phonetic learning across languages
Aug 06, 2020



In the first year of life, infants' speech perception becomes attuned to the sounds of their native language. Many accounts of this early phonetic learning exist, but computational models predicting the attunement patterns observed in infants from the speech input they hear have been lacking. A recent study presented the first such model, drawing on algorithms proposed for unsupervised learning from naturalistic speech, and tested it on a single phone contrast. Here we study five such algorithms, selected for their potential cognitive relevance. We simulate phonetic learning with each algorithm and perform tests on three phone contrasts from different languages, comparing the results to infants' discrimination patterns. The five models display varying degrees of agreement with empirical observations, showing that our approach can help decide between candidate mechanisms for early phonetic learning, and providing insight into which aspects of the models are critical for capturing infants' perceptual development.
* 7 pages, 1 figure