 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVEN: A Mesh-Aware Volumetric Encoding Network for Simulating 3D Flexible Deformation
Apr 06, 2026Deep learning-based approaches, particularly graph neural networks (GNNs), have gained prominence in simulating flexible deformations and contacts of solids, due to their ability to handle unstructured physical fields and nonlinear regression on graph structures. However, existing GNNs commonly represent meshes with graphs built solely from vertices and edges. These approaches tend to overlook higher-dimensional spatial features, e.g., 2D facets and 3D cells, from the original geometry. As a result, it is challenging to accurately capture boundary representations and volumetric characteristics, though this information is critically important for modeling contact interactions and internal physical quantity propagation, particularly under sparse mesh discretization. In this paper, we introduce MAVEN, a mesh-aware volumetric encoding network for simulating 3D flexible deformation, which explicitly models geometric mesh elements of higher dimension to achieve a more accurate and natural physical simulation. MAVEN establishes learnable mappings among 3D cells, 2D facets, and vertices, enabling flexible mutual transformations. Explicit geometric features are incorporated into the model to alleviate the burden of implicitly learning geometric patterns. Experimental results show that MAVEN consistently achieves state-of-the-art performance across established datasets and a novel metal stretch-bending task featuring large deformations and prolonged contacts.
Life cycle assessment for all organic chemicals
Mar 15, 2026Chemicals are embedded in nearly every aspect of modern society, yet their production poses substantial sustainability concerns. Achieving a sustainable chemical industry requires detailed Life Cycle Assessment (LCA); however, current assessments face many unknowns due to limited, partly inconsistent, and untransparent data coverage since existing Life Cycle Inventory (LCI) databases account for only a tiny fraction of traded chemicals. Here, we introduce the Chemical RetrosYnthesiS for Transparent Assessment of Life-cycles (CRYSTAL) framework, which automatically generates consistent and transparent LCI data for organic chemicals based on their molecular structure using retrosynthesis and machine-learned gate-to-gate inventories. Using the predictive power of CRYSTAL, we create a consistent database for more than 70000 organic chemicals, comprising over 110000 transparent LCI datasets that quantify both feedstock and energy demands, together with associated auxiliary materials, biosphere flows, and waste flows. From this comprehensive database, we identify 50 key environmental hotspots driving high impacts of organic chemical production across multiple environmental categories and pivotal hub chemicals that are most critical for downstream chemical production. In providing this comprehensive data foundation, the CRYSTAL framework offers systematic guidance for targeted engineering and policy interventions. Its transparent, modular nature is designed to shift chemical LCA from a reliance on "unknown unknowns" to a collaboratively improvable mapping of "known unknowns".
Neural Latent Arbitrary Lagrangian-Eulerian Grids for Fluid-Solid Interaction
Feb 28, 2026Fluid-solid interaction (FSI) problems are fundamental in many scientific and engineering applications, yet effectively capturing the highly nonlinear two-way interactions remains a significant challenge. Most existing deep learning methods are limited to simplified one-way FSI scenarios, often assuming rigid and static solid to reduce complexity. Even in two-way setups, prevailing approaches struggle to capture dynamic, heterogeneous interactions due to the lack of cross-domain awareness. In this paper, we introduce \textbf{Fisale}, a data-driven framework for handling complex two-way \textbf{FSI} problems. It is inspired by classical numerical methods, namely the Arbitrary Lagrangian-Eulerian (\textbf{ALE}) method and the partitioned coupling algorithm. Fisale explicitly models the coupling interface as a distinct component and leverages multiscale latent ALE grids to provide unified, geometry-aware embeddings across domains. A partitioned coupling module (PCM) further decomposes the problem into structured substeps, enabling progressive modeling of nonlinear interdependencies. Compared to existing models, Fisale introduces a more flexible framework that iteratively handles complex dynamics of solid, fluid and their coupling interface on a unified representation, and enables scalable learning of complex two-way FSI behaviors. Experimentally, Fisale excels in three reality-related challenging FSI scenarios, covering 2D, 3D and various tasks. The code is available at \href{https://github.com/therontau0054/Fisale}.
Cardiovascular Disease Detection By Leveraging Semi-Supervised Learning
Dec 13, 2024



Cardiovascular disease (CVD) persists as a primary cause of death on a global scale, which requires more effective and timely detection methods. Traditional supervised learning approaches for CVD detection rely heavily on large-labeled datasets, which are often difficult to obtain. This paper employs semi-supervised learning models to boost efficiency and accuracy of CVD detection when there are few labeled samples. By leveraging both labeled and vast amounts of unlabeled data, our approach demonstrates improvements in prediction performance, while reducing the dependency on labeled data. Experimental results in a publicly available dataset show that semi-supervised models outperform traditional supervised learning techniques, providing an intriguing approach for the initial identification of cardiovascular disease within clinical environments.
Graphical Structural Learning of rs-fMRI data in Heavy Smokers
Sep 16, 2024



Recent studies revealed structural and functional brain changes in heavy smokers. However, the specific changes in topological brain connections are not well understood. We used Gaussian Undirected Graphs with the graphical lasso algorithm on rs-fMRI data from smokers and non-smokers to identify significant changes in brain connections. Our results indicate high stability in the estimated graphs and identify several brain regions significantly affected by smoking, providing valuable insights for future clinical research.
Identification of Prognostic Biomarkers for Stage III Non-Small Cell Lung Carcinoma in Female Nonsmokers Using Machine Learning
Aug 30, 2024



Lung cancer remains a leading cause of cancer-related deaths globally, with non-small cell lung cancer (NSCLC) being the most common subtype. This study aimed to identify key biomarkers associated with stage III NSCLC in non-smoking females using gene expression profiling from the GDS3837 dataset. Utilizing XGBoost, a machine learning algorithm, the analysis achieved a strong predictive performance with an AUC score of 0.835. The top biomarkers identified - CCAAT enhancer binding protein alpha (C/EBP-alpha), lactate dehydrogenase A4 (LDHA), UNC-45 myosin chaperone B (UNC-45B), checkpoint kinase 1 (CHK1), and hypoxia-inducible factor 1 subunit alpha (HIF-1-alpha) - have been validated in the literature as being significantly linked to lung cancer. These findings highlight the potential of these biomarkers for early diagnosis and personalized therapy, emphasizing the value of integrating machine learning with molecular profiling in cancer research.
Domain Knowledge integrated for Blast Furnace Classifier Design
Mar 31, 2023Blast furnace modeling and control is one of the important problems in the industrial field, and the black-box model is an effective mean to describe the complex blast furnace system. In practice, there are often different learning targets, such as safety and energy saving in industrial applications, depending on the application. For this reason, this paper proposes a framework to design a domain knowledge integrated classification model that yields a classifier for industrial application. Our knowledge incorporated learning scheme allows the users to create a classifier that identifies "important samples" (whose misclassifications can lead to severe consequences) more correctly, while keeping the proper precision of classifying the remaining samples. The effectiveness of the proposed method has been verified by two real blast furnace datasets, which guides the operators to utilize their prior experience for controlling the blast furnace systems better.
Transfer Learning in Information Criteria-based Feature Selection
Jul 06, 2021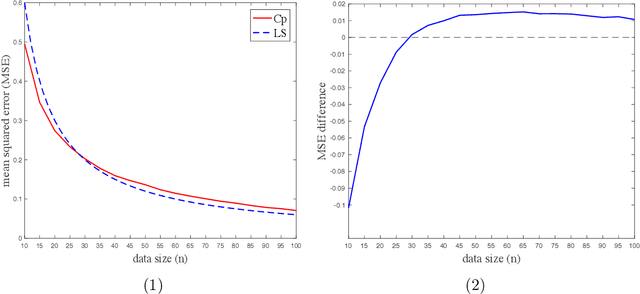
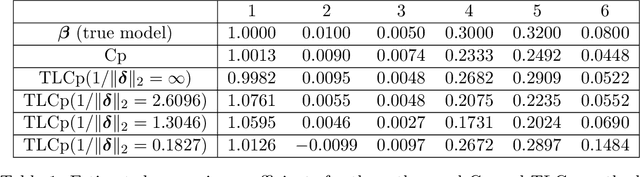
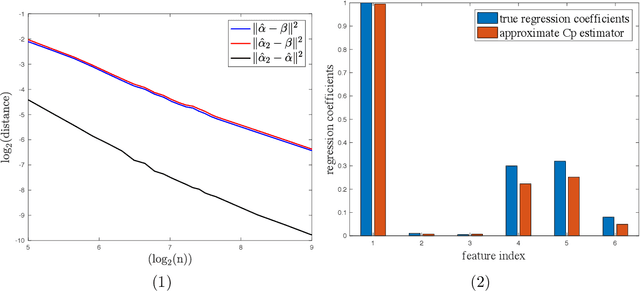
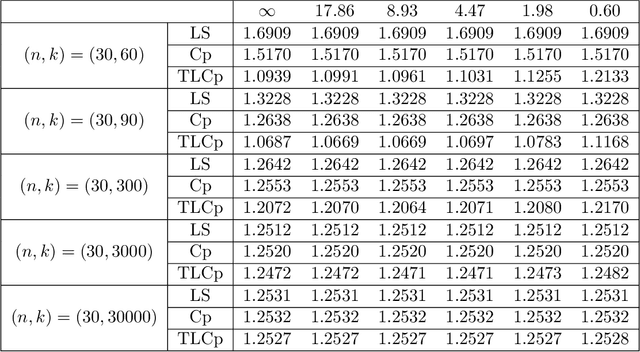
This paper investigates the effectiveness of transfer learning based on Mallows' Cp. We propose a procedure that combines transfer learning with Mallows' Cp (TLCp) and prove that it outperforms the conventional Mallows' Cp criterion in terms of accuracy and stability. Our theoretical results indicate that, for any sample size in the target domain, the proposed TLCp estimator performs better than the Cp estimator by the mean squared error (MSE) metric in the case of orthogonal predictors, provided that i) the dissimilarity between the tasks from source domain and target domain is small, and ii) the procedure parameters (complexity penalties) are tuned according to certain explicit rules. Moreover, we show that our transfer learning framework can be extended to other feature selection criteria, such as the Bayesian information criterion. By analyzing the solution of the orthogonalized Cp, we identify an estimator that asymptotically approximates the solution of the Cp criterion in the case of non-orthogonal predictors. Similar results are obtained for the non-orthogonal TLCp. Finally, simulation studies and applications with real data demonstrate the usefulness of the TLCp scheme.
Knowledge Integrated Classifier Design Based on Utility Optimization
Sep 05, 2018This paper proposes a systematic framework to design a classification model that yields a classifier which optimizes a utility function based on prior knowledge. Specifically, as the data size grows, we prove that the produced classifier asymptotically converges to the optimal classifier, an extended version of the Bayes rule, which maximizes the utility function. Therefore, we provide a meaningful theoretical interpretation for modeling with the knowledge incorporated. Our knowledge incorporation method allows domain experts to guide the classifier towards correctly classifying data that they think to be more significant.
Asymptotic performance of regularized multi-task learning
May 31, 2018



This paper analyzes asymptotic performance of a regularized multi-task learning model where task parameters are optimized jointly. If tasks are closely related, empirical work suggests multi-task learning models to outperform single-task ones in finite sample cases. As data size grows indefinitely, we show the learned multi-classifier to optimize an average misclassification error function which depicts the risk of applying multi-task learning algorithm to making decisions. This technique conclusion demonstrates the regularized multi-task learning model to be able to produce reliable decision rule for each task in the sense that it will asymptotically converge to the corresponding Bayes rule. Also, we find the interaction effect between tasks vanishes as data size growing indefinitely, which is quite different from the behavior in finite sample cases.