 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Distributions Generated by One-Layer ReLU Networks
Sep 19, 2019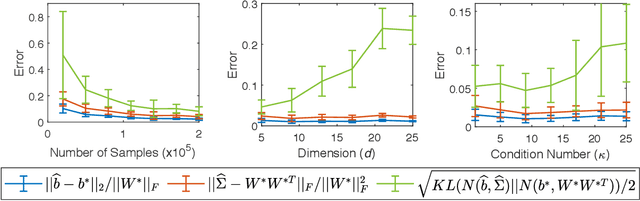
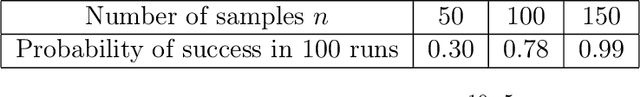
We consider the problem of estimating the parameters of a $d$-dimensional rectified Gaussian distribution from i.i.d. samples. A rectified Gaussian distribution is defined by passing a standard Gaussian distribution through a one-layer ReLU neural network. We give a simple algorithm to estimate the parameters (i.e., the weight matrix and bias vector of the ReLU neural network) up to an error $\epsilon||W||_F$ using $\tilde{O}(1/\epsilon^2)$ samples and $\tilde{O}(d^2/\epsilon^2)$ time (log factors are ignored for simplicity). This implies that we can estimate the distribution up to $\epsilon$ in total variation distance using $\tilde{O}(\kappa^2d^2/\epsilon^2)$ samples, where $\kappa$ is the condition number of the covariance matrix. Our only assumption is that the bias vector is non-negative. Without this non-negativity assumption, we show that estimating the bias vector within any error requires the number of samples at least exponential in the infinity norm of the bias vector. Our algorithm is based on the key observation that vector norms and pairwise angles can be estimated separately. We use a recent result on learning from truncated samples. We also prove two sample complexity lower bounds: $\Omega(1/\epsilon^2)$ samples are required to estimate the parameters up to error $\epsilon$, while $\Omega(d/\epsilon^2)$ samples are necessary to estimate the distribution up to $\epsilon$ in total variation distance. The first lower bound implies that our algorithm is optimal for parameter estimation. Finally, we show an interesting connection between learning a two-layer generative model and non-negative matrix factorization. Experimental results are provided to support our analysis.
Sparse Logistic Regression Learns All Discrete Pairwise Graphical Models
Oct 28, 2018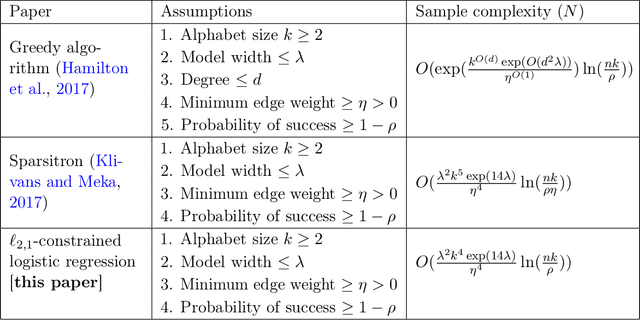
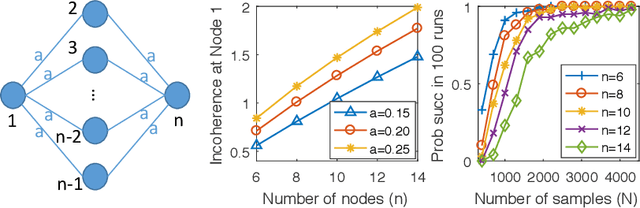
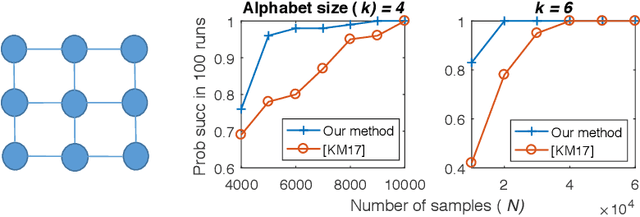

We characterize the effectiveness of a natural and classic algorithm for recovering the Markov graph of a general discrete pairwise graphical model from i.i.d. samples. The algorithm is (appropriately regularized) conditional maximum likelihood, which involves solving a convex program for each node; for Ising models this is $\ell_1$-constrained logistic regression, while for more alphabets an $\ell_{2,1}$ group-norm constraint needs to be used. We show that this algorithm can recover any arbitrary discrete pairwise graphical model, and also characterize its sample complexity as a function of model width, alphabet size, edge parameter accuracy, and the number of variables. We show that along every one of these axes, it matches or improves on all existing results and algorithms for this problem. Our analysis applies a sharp generalization error bound for logistic regression when the weight vector has an $\ell_1$ constraint (or $\ell_{2,1}$ constraint) and the sample vector has an $\ell_{\infty}$ constraint (or $\ell_{2, \infty}$ constraint). We also show that the proposed convex programs can be efficiently optimized in $\tilde{O}(n^2)$ running time (where $n$ is the number of variables) under the same statistical guarantee. Our experimental results verify our analysis.
The Sparse Recovery Autoencoder
Jul 05, 2018
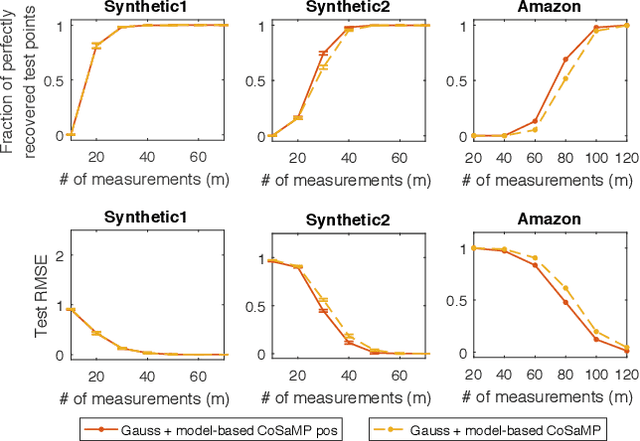
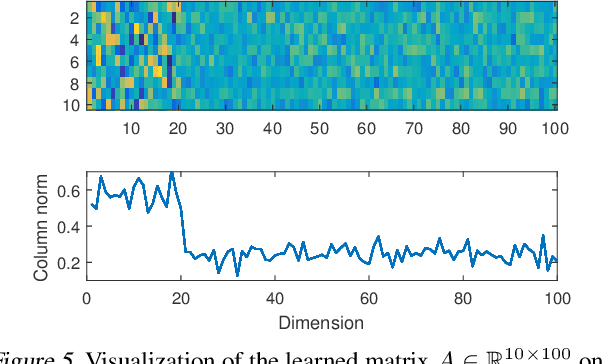
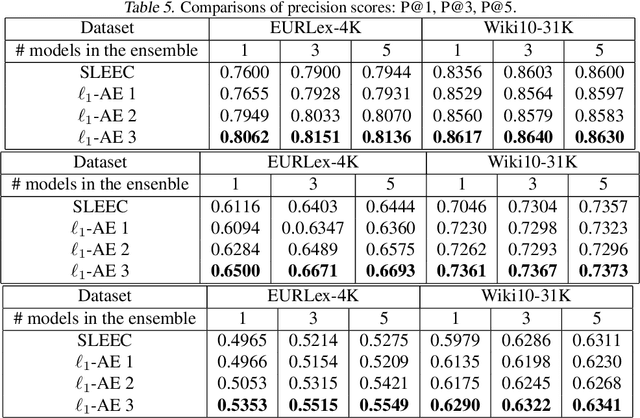
Linear encoding of sparse vectors is widely popular, but is most commonly data-independent -- missing any possible extra (but a-priori unknown) structure beyond sparsity. In this paper we present a new method to learn linear encoders that adapt to data, while still performing well with the widely used $\ell_1$ decoder. The convex $\ell_1$ decoder prevents gradient propagation as needed in standard autoencoder training. Our method is based on the insight that unfolding the convex decoder into $T$ projected gradient steps can address this issue. Our method can be seen as a data-driven way to learn a compressed sensing matrix. Our experiments show that there is indeed additional structure beyond sparsity in several real datasets. Our autoencoder is able to discover it and exploit it to create excellent reconstructions with fewer measurements compared to the previous state of the art methods.
Leveraging Sparsity for Efficient Submodular Data Summarization
Mar 08, 2017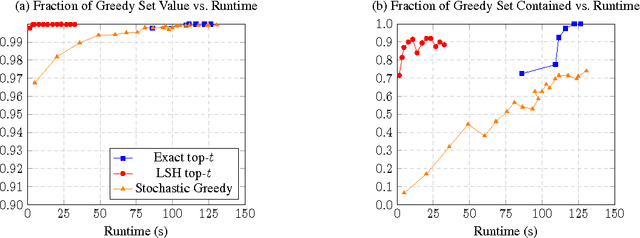
The facility location problem is widely used for summarizing large datasets and has additional applications in sensor placement, image retrieval, and clustering. One difficulty of this problem is that submodular optimization algorithms require the calculation of pairwise benefits for all items in the dataset. This is infeasible for large problems, so recent work proposed to only calculate nearest neighbor benefits. One limitation is that several strong assumptions were invoked to obtain provable approximation guarantees. In this paper we establish that these extra assumptions are not necessary---solving the sparsified problem will be almost optimal under the standard assumptions of the problem. We then analyze a different method of sparsification that is a better model for methods such as Locality Sensitive Hashing to accelerate the nearest neighbor computations and extend the use of the problem to a broader family of similarities. We validate our approach by demonstrating that it rapidly generates interpretable summaries.
Single Pass PCA of Matrix Products
Oct 26, 2016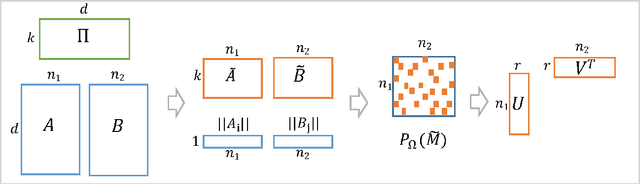
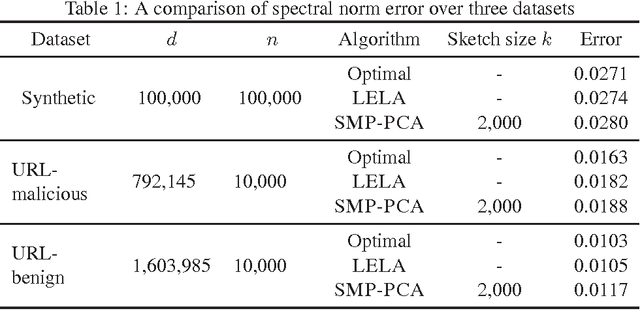
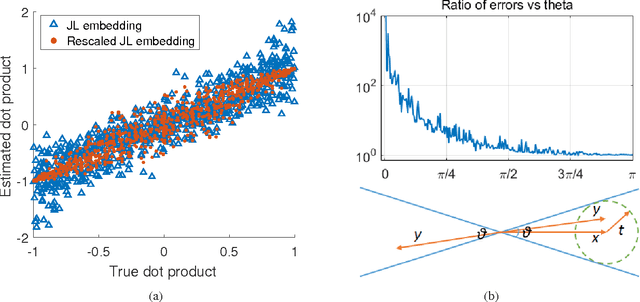
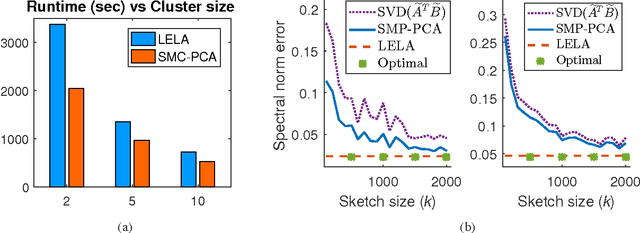
In this paper we present a new algorithm for computing a low rank approximation of the product $A^TB$ by taking only a single pass of the two matrices $A$ and $B$. The straightforward way to do this is to (a) first sketch $A$ and $B$ individually, and then (b) find the top components using PCA on the sketch. Our algorithm in contrast retains additional summary information about $A,B$ (e.g. row and column norms etc.) and uses this additional information to obtain an improved approximation from the sketches. Our main analytical result establishes a comparable spectral norm guarantee to existing two-pass methods; in addition we also provide results from an Apache Spark implementation that shows better computational and statistical performance on real-world and synthetic evaluation datasets.