 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecific versus General Principles for Constitutional AI
Oct 20, 2023



Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023



Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Coarsening Optimization for Differentiable Programming
Oct 05, 2021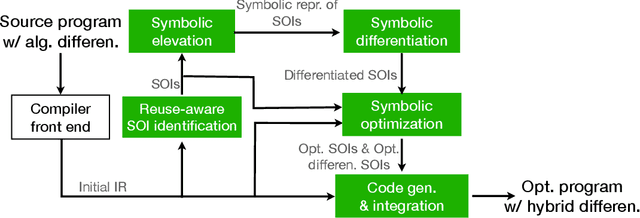
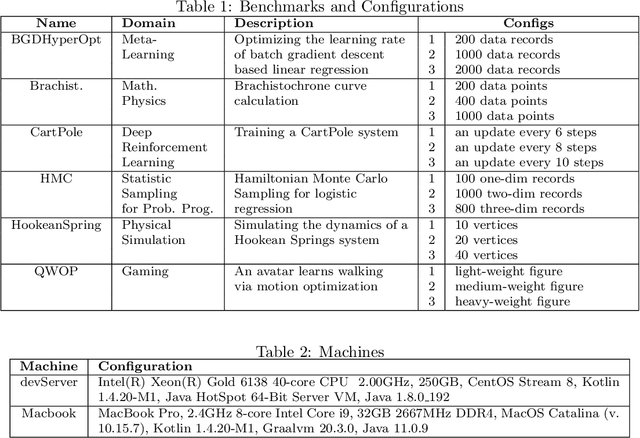

This paper presents a novel optimization for differentiable programming named coarsening optimization. It offers a systematic way to synergize symbolic differentiation and algorithmic differentiation (AD). Through it, the granularity of the computations differentiated by each step in AD can become much larger than a single operation, and hence lead to much reduced runtime computations and data allocations in AD. To circumvent the difficulties that control flow creates to symbolic differentiation in coarsening, this work introduces phi-calculus, a novel method to allow symbolic reasoning and differentiation of computations that involve branches and loops. It further avoids "expression swell" in symbolic differentiation and balance reuse and coarsening through the design of reuse-centric segment of interest identification. Experiments on a collection of real-world applications show that coarsening optimization is effective in speeding up AD, producing several times to two orders of magnitude speedups.
Gradient Descent: The Ultimate Optimizer
Sep 29, 2019
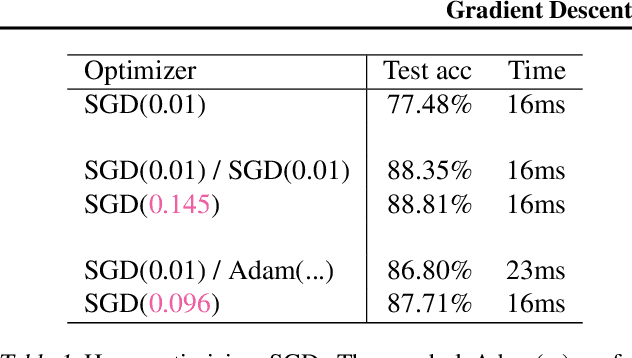
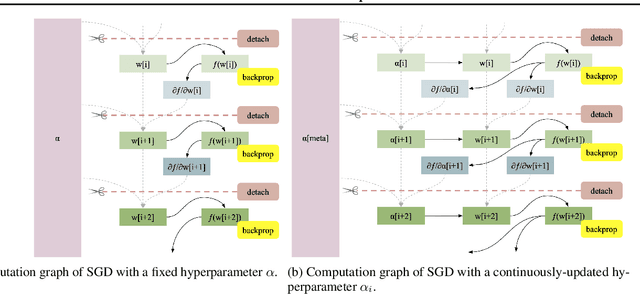
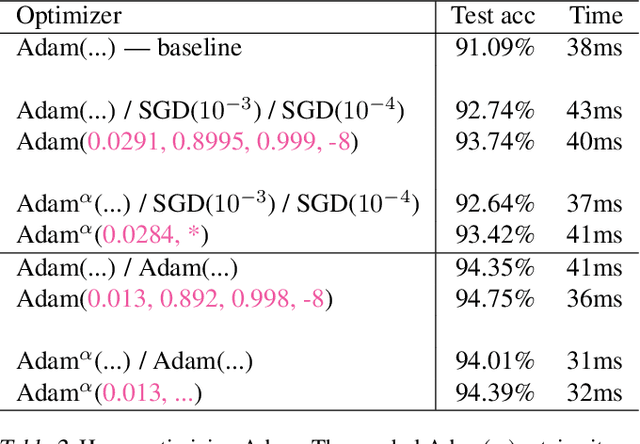
Working with any gradient-based machine learning algorithm involves the tedious task of tuning the optimizer's hyperparameters, such as the learning rate. There exist many techniques for automated hyperparameter optimization, but they typically introduce even more hyperparameters to control the hyperparameter optimization process. We propose to instead learn the hyperparameters themselves by gradient descent, and furthermore to learn the hyper-hyperparameters by gradient descent as well, and so on ad infinitum. As these towers of gradient-based optimizers grow, they become significantly less sensitive to the choice of top-level hyperparameters, hence decreasing the burden on the user to search for optimal values.