 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Domain-based Perceptual Loss for Super Resolution
Jul 23, 2020

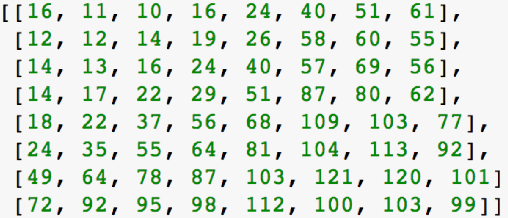
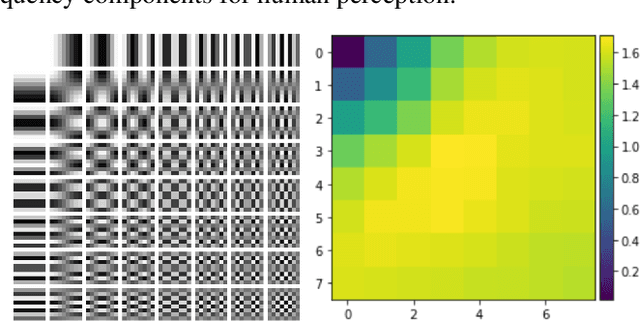
We introduce Frequency Domain Perceptual Loss (FDPL), a loss function for single image super resolution (SR). Unlike previous loss functions used to train SR models, which are all calculated in the pixel (spatial) domain, FDPL is computed in the frequency domain. By working in the frequency domain we can encourage a given model to learn a mapping that prioritizes those frequencies most related to human perception. While the goal of FDPL is not to maximize the Peak Signal to Noise Ratio (PSNR), we found that there is a correlation between decreasing FDPL and increasing PSNR. Training a model with FDPL results in a higher average PSRN (30.94), compared to the same model trained with pixel loss (30.59), as measured on the Set5 image dataset. We also show that our method achieves higher qualitative results, which is the goal of a perceptual loss function. However, it is not clear that the improved perceptual quality is due to the slightly higher PSNR or the perceptual nature of FDPL.
Predicting Confusion from Eye-Tracking Data with Recurrent Neural Networks
Jun 19, 2019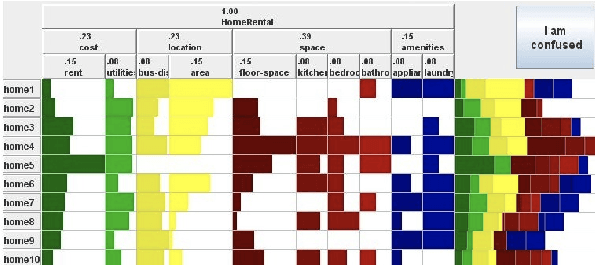

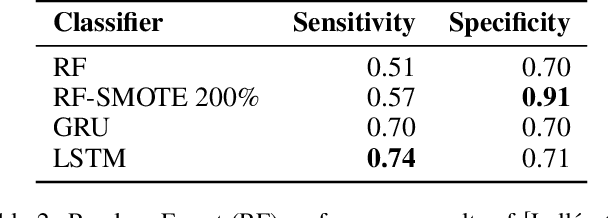
Encouraged by the success of deep learning in a variety of domains, we investigate the suitability and effectiveness of Recurrent Neural Networks (RNNs) in a domain where deep learning has not yet been used; namely detecting confusion from eye-tracking data. Through experiments with a dataset of user interactions with ValueChart (an interactive visualization tool), we found that RNNs learn a feature representation from the raw data that allows for a more powerful classifier than previous methods that use engineered features. This is evidenced by the stronger performance of the RNN (0.74/0.71 sensitivity/specificity), as compared to a Random Forest classifier (0.51/0.70 sensitivity/specificity), when both are trained on an un-augmented dataset. However, using engineered features allows for simple data augmentation methods to be used. These same methods are not as effective at augmentation for the feature representation learned from the raw data, likely due to an inability to match the temporal dynamics of the data.