 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissingness Bias Calibration in Feature Attribution Explanations
Mar 05, 2026Popular explanation methods often produce unreliable feature importance scores due to missingness bias, a systematic distortion that arises when models are probed with ablated, out-of-distribution inputs. Existing solutions treat this as a deep representational flaw that requires expensive retraining or architectural modifications. In this work, we challenge this assumption and show that missingness bias can be effectively treated as a superficial artifact of the model's output space. We introduce MCal, a lightweight post-hoc method that corrects this bias by fine-tuning a simple linear head on the outputs of a frozen base model. Surprisingly, we find this simple correction consistently reduces missingness bias and is competitive with, or even outperforms, prior heavyweight approaches across diverse medical benchmarks spanning vision, language, and tabular domains.
Parsimonious Computing: A Minority Training Regime for Effective Prediction in Large Microarray Expression Data Sets
May 18, 2020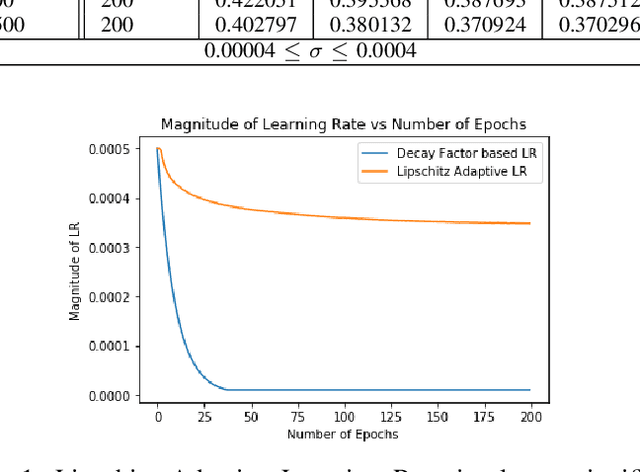
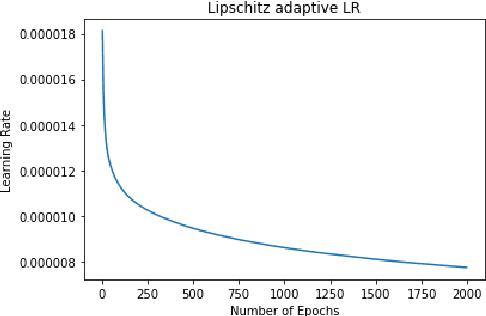
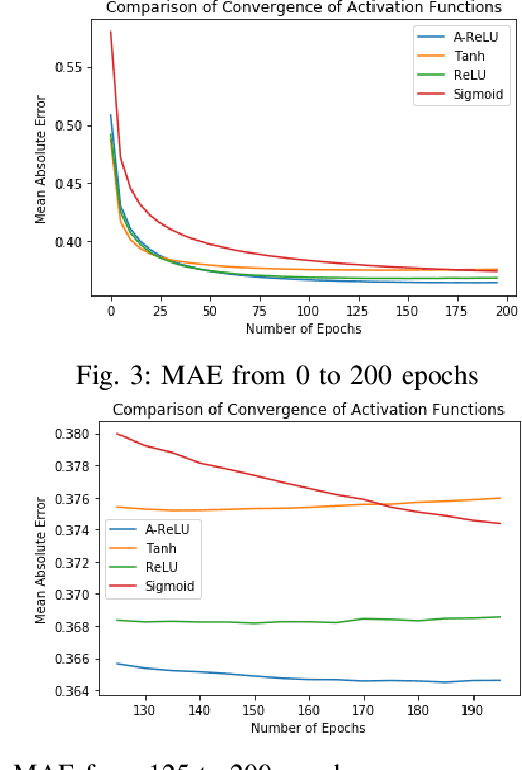
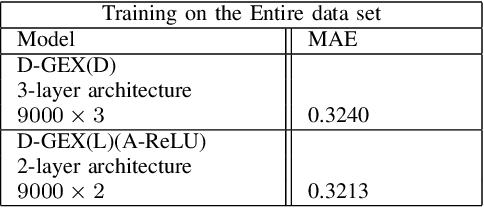
Rigorous mathematical investigation of learning rates used in back-propagation in shallow neural networks has become a necessity. This is because experimental evidence needs to be endorsed by a theoretical background. Such theory may be helpful in reducing the volume of experimental effort to accomplish desired results. We leveraged the functional property of Mean Square Error, which is Lipschitz continuous to compute learning rate in shallow neural networks. We claim that our approach reduces tuning efforts, especially when a significant corpus of data has to be handled. We achieve remarkable improvement in saving computational cost while surpassing prediction accuracy reported in literature. The learning rate, proposed here, is the inverse of the Lipschitz constant. The work results in a novel method for carrying out gene expression inference on large microarray data sets with a shallow architecture constrained by limited computing resources. A combination of random sub-sampling of the dataset, an adaptive Lipschitz constant inspired learning rate and a new activation function, A-ReLU helped accomplish the results reported in the paper.