 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Predictive Optimization and Generation for Business AI
May 14, 2025



The sales process involves sales functions converting leads or opportunities to customers and selling more products to existing customers. The optimization of the sales process thus is key to success of any B2B business. In this work, we introduce a principled approach to sales optimization and business AI, namely the Causal Predictive Optimization and Generation, which includes three layers: 1) prediction layer with causal ML 2) optimization layer with constraint optimization and contextual bandit 3) serving layer with Generative AI and feedback-loop for system enhancement. We detail the implementation and deployment of the system in LinkedIn, showcasing significant wins over legacy systems and sharing learning and insight broadly applicable to this field.
Sales Channel Optimization via Simulations Based on Observational Data with Delayed Rewards: A Case Study at LinkedIn
Sep 16, 2022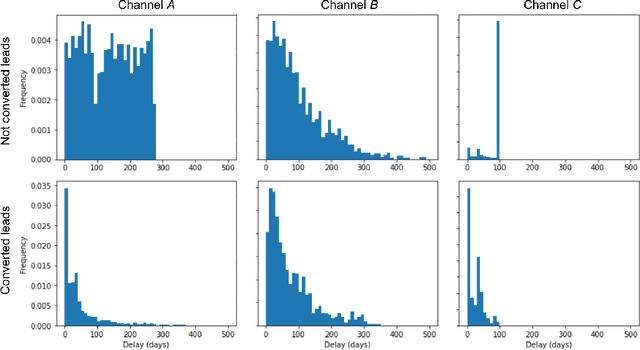
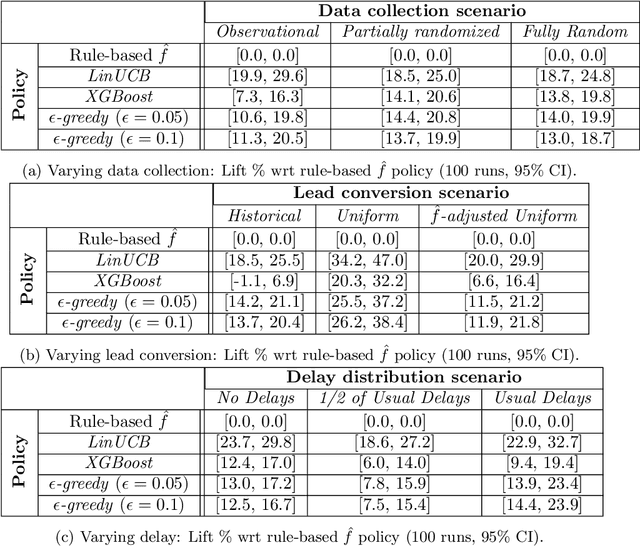
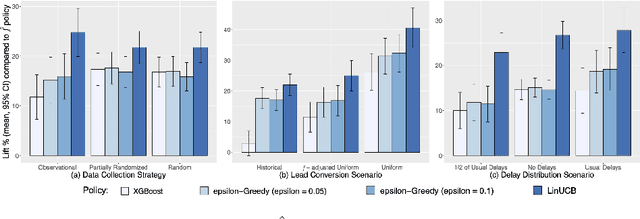
Training models on data obtained from randomized experiments is ideal for making good decisions. However, randomized experiments are often time-consuming, expensive, risky, infeasible or unethical to perform, leaving decision makers little choice but to rely on observational data collected under historical policies when training models. This opens questions regarding not only which decision-making policies would perform best in practice, but also regarding the impact of different data collection protocols on the performance of various policies trained on the data, or the robustness of policy performance with respect to changes in problem characteristics such as action- or reward- specific delays in observing outcomes. We aim to answer such questions for the problem of optimizing sales channel allocations at LinkedIn, where sales accounts (leads) need to be allocated to one of three channels, with the goal of maximizing the number of successful conversions over a period of time. A key problem feature constitutes the presence of stochastic delays in observing allocation outcomes, whose distribution is both channel- and outcome- dependent. We built a discrete-time simulation that can handle our problem features and used it to evaluate: a) a historical rule-based policy; b) a supervised machine learning policy (XGBoost); and c) multi-armed bandit (MAB) policies, under different scenarios involving: i) data collection used for training (observational vs randomized); ii) lead conversion scenarios; iii) delay distributions. Our simulation results indicate that LinUCB, a simple MAB policy, consistently outperforms the other policies, achieving a 18-47% lift relative to a rule-based policy