 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Propensity Scores for Causal Effect Estimation
Jun 01, 2023Propensity scores are commonly used to balance observed covariates while estimating treatment effects. Estimates obtained through propensity score weighing can be biased when the propensity score model cannot learn the true treatment assignment mechanism. We argue that the probabilistic output of a learned propensity score model should be calibrated, i.e. a predictive treatment probability of 90% should correspond to 90% of individuals being assigned the treatment group. We propose simple recalibration techniques to ensure this property. We investigate the theoretical properties of a calibrated propensity score model and its role in unbiased treatment effect estimation. We demonstrate improved causal effect estimation with calibrated propensity scores in several tasks including high-dimensional genome-wide association studies, where we also show reduced computational requirements when calibration is applied to simpler propensity score models.
Online Calibrated Regression for Adversarially Robust Forecasting
Feb 23, 2023Accurately estimating uncertainty is a crucial component of decision-making and forecasting in machine learning. However, existing uncertainty estimation methods developed for IID data may fail when these IID assumptions no longer hold. In this paper, we present a novel approach to uncertainty estimation that leverages the principles of online learning. Specifically, we define a task called online calibrated forecasting which seeks to extend existing online learning methods to handle predictive uncertainty while ensuring high accuracy. We introduce algorithms for this task that provide formal guarantees on the accuracy and calibration of probabilistic predictions even on adversarial input. We demonstrate the practical utility of our methods on several forecasting tasks, showing that our probabilistic predictions improve over natural baselines. Overall, our approach advances calibrated uncertainty estimation, and takes a step towards more robust and reliable decision-making and forecasting in risk-sensitive scenarios.
Multi-Modal Causal Inference with Deep Structural Equation Models
Mar 21, 2022
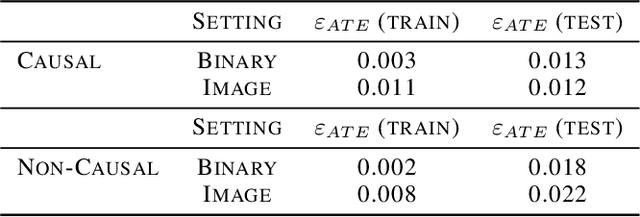
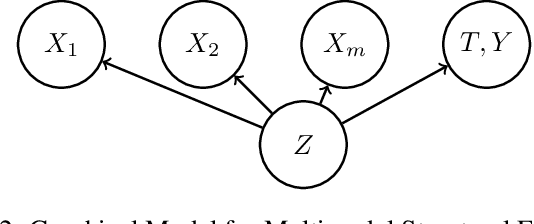

Accounting for the effects of confounders is one of the central challenges in causal inference. Unstructured multi-modal data (images, time series, text) contains valuable information about diverse types of confounders, yet it is typically left unused by most existing methods. This paper seeks to develop techniques that leverage this unstructured data within causal inference to correct for additional confounders that may otherwise not be accounted for. We formalize this task and we propose algorithms based on deep structural equations that treat multi-modal unstructured data as proxy variables. We empirically demonstrate on tasks in genomics and healthcare that unstructured data can be used to correct for diverse sources of confounding, potentially enabling the use of large amounts of data that were previously not used in causal inference.
Calibrated and Sharp Uncertainties in Deep Learning via Simple Density Estimation
Dec 14, 2021

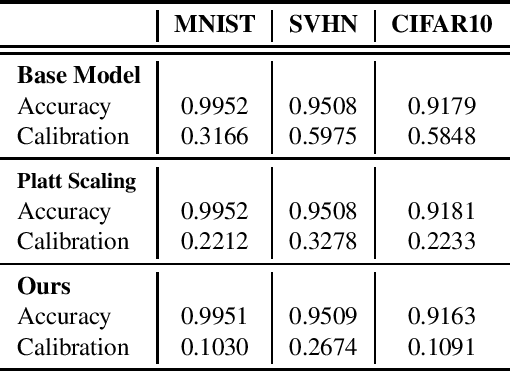
Predictive uncertainties can be characterized by two properties--calibration and sharpness. This paper argues for reasoning about uncertainty in terms these properties and proposes simple algorithms for enforcing them in deep learning. Our methods focus on the strongest notion of calibration--distribution calibration--and enforce it by fitting a low-dimensional density or quantile function with a neural estimator. The resulting approach is much simpler and more broadly applicable than previous methods across both classification and regression. Empirically, we find that our methods improve predictive uncertainties on several tasks with minimal computational and implementation overhead. Our insights suggest simple and improved ways of training deep learning models that lead to accurate uncertainties that should be leveraged to improve performance across downstream applications.
Calibration Improves Bayesian Optimization
Dec 08, 2021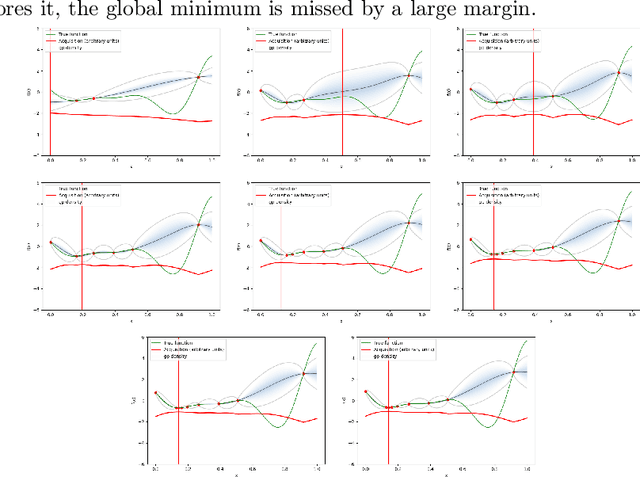
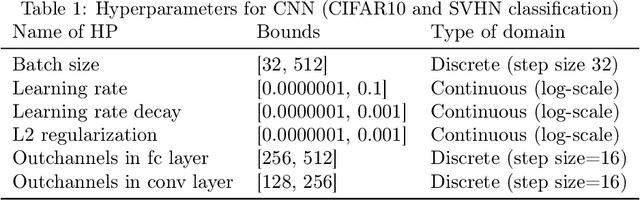
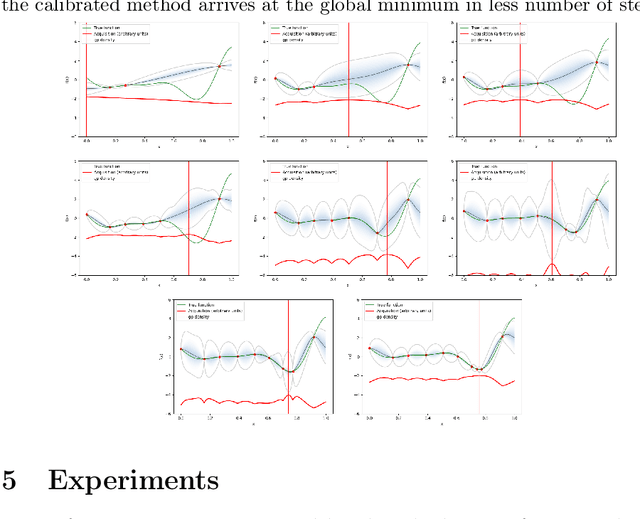

Bayesian optimization is a procedure that allows obtaining the global optimum of black-box functions and that is useful in applications such as hyper-parameter optimization. Uncertainty estimates over the shape of the objective function are instrumental in guiding the optimization process. However, these estimates can be inaccurate if the objective function violates assumptions made within the underlying model (e.g., Gaussianity). We propose a simple algorithm to calibrate the uncertainty of posterior distributions over the objective function as part of the Bayesian optimization process. We show that by improving the uncertainty estimates of the posterior distribution with calibration, Bayesian optimization makes better decisions and arrives at the global optimum in fewer steps. We show that this technique improves the performance of Bayesian optimization on standard benchmark functions and hyperparameter optimization tasks.