 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROSAQ: Rotation-based Saliency-Aware Weight Quantization for Efficiently Compressing Large Language Models
Jun 16, 2025



Quantization has been widely studied as an effective technique for reducing the memory requirement of large language models (LLMs), potentially improving the latency time as well. Utilizing the characteristic of rotational invariance of transformer, we propose the rotation-based saliency-aware weight quantization (ROSAQ), which identifies salient channels in the projection feature space, not in the original feature space, where the projected "principal" dimensions are naturally considered as "salient" features. The proposed ROSAQ consists of 1) PCA-based projection, which first performs principal component analysis (PCA) on a calibration set and transforms via the PCA projection, 2) Salient channel dentification, which selects dimensions corresponding to the K-largest eigenvalues as salient channels, and 3) Saliency-aware quantization with mixed-precision, which uses FP16 for salient dimensions and INT3/4 for other dimensions. Experiment results show that ROSAQ shows improvements over the baseline saliency-aware quantization on the original feature space and other existing quantization methods. With kernel fusion, ROSAQ presents about 2.3x speed up over FP16 implementation in generating 256 tokens with a batch size of 64.
Improving Term Frequency Normalization for Multi-topical Documents, and Application to Language Modeling Approaches
Feb 08, 2015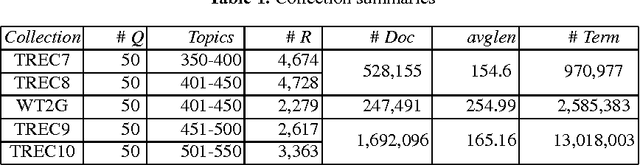
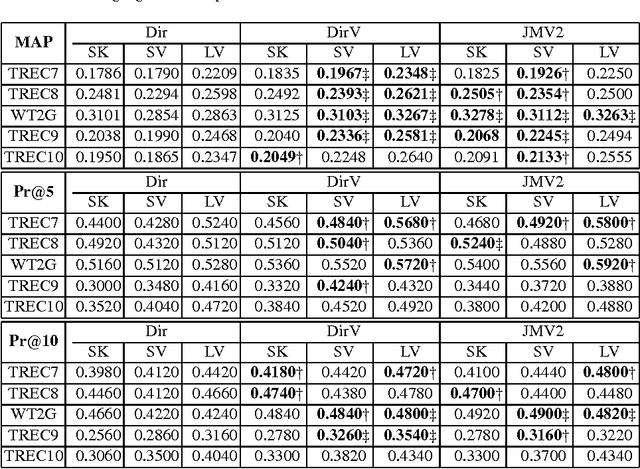
Term frequency normalization is a serious issue since lengths of documents are various. Generally, documents become long due to two different reasons - verbosity and multi-topicality. First, verbosity means that the same topic is repeatedly mentioned by terms related to the topic, so that term frequency is more increased than the well-summarized one. Second, multi-topicality indicates that a document has a broad discussion of multi-topics, rather than single topic. Although these document characteristics should be differently handled, all previous methods of term frequency normalization have ignored these differences and have used a simplified length-driven approach which decreases the term frequency by only the length of a document, causing an unreasonable penalization. To attack this problem, we propose a novel TF normalization method which is a type of partially-axiomatic approach. We first formulate two formal constraints that the retrieval model should satisfy for documents having verbose and multi-topicality characteristic, respectively. Then, we modify language modeling approaches to better satisfy these two constraints, and derive novel smoothing methods. Experimental results show that the proposed method increases significantly the precision for keyword queries, and substantially improves MAP (Mean Average Precision) for verbose queries.
* 8 pages, conference paper, published in ECIR '08