 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic Group Projection for Enumerating Quasi-Cyclic Codes Trapping Sets
Jan 26, 2024This paper introduces a novel approach to enumerate and assess Trapping sets in quasi-cyclic codes, those with circulant sizes that are non-prime numbers. Leveraging the quasi-cyclic properties, the method employs a tabular technique to streamline the importance sampling step for estimating the pseudo-codeword weight of Trapping sets. The presented methodology draws on the mathematical framework established in the provided theorem, which elucidates the behavior of projection and lifting transformations on pseudo-codewords
Topology-Aware Exploration of Energy-Based Models Equilibrium: Toric QC-LDPC Codes and Hyperbolic MET QC-LDPC Codes
Jan 26, 2024This paper presents a method for achieving equilibrium in the ISING Hamiltonian when confronted with unevenly distributed charges on an irregular grid. Employing (Multi-Edge) QC-LDPC codes and the Boltzmann machine, our approach involves dimensionally expanding the system, substituting charges with circulants, and representing distances through circulant shifts. This results in a systematic mapping of the charge system onto a space, transforming the irregular grid into a uniform configuration, applicable to Torical and Circular Hyperboloid Topologies. The paper covers fundamental definitions and notations related to QC-LDPC Codes, Multi-Edge QC-LDPC codes, and the Boltzmann machine. It explores the marginalization problem in code on the graph probabilistic models for evaluating the partition function, encompassing exact and approximate estimation techniques. Rigorous proof is provided for the attainability of equilibrium states for the Boltzmann machine under Torical and Circular Hyperboloid, paving the way for the application of our methodology. Practical applications of our approach are investigated in Finite Geometry QC-LDPC Codes, specifically in Material Science. The paper further explores its effectiveness in the realm of Natural Language Processing Transformer Deep Neural Networks, examining Generalized Repeat Accumulate Codes, Spatially-Coupled and Cage-Graph QC-LDPC Codes. The versatile and impactful nature of our topology-aware hardware-efficient quasi-cycle codes equilibrium method is showcased across diverse scientific domains without the use of specific section delineations.
Spherical and Hyperbolic Toric Topology-Based Codes On Graph Embedding for Ising MRF Models: Classical and Quantum Topology Machine Learning
Jul 28, 2023



The paper introduces the application of information geometry to describe the ground states of Ising models. This is achieved by utilizing parity-check matrices of cyclic and quasi-cyclic codes on toric and spherical topologies. The approach establishes a connection between machine learning and error-correcting coding, specifically in terms of automorphism and the size of the circulant of the quasi-cyclic code. This proposed approach has implications for the development of new embedding methods based on trapping sets. Statistical physics and number geometry are utilized to optimize error-correcting codes, leading to these embedding and sparse factorization methods. The paper establishes a direct connection between DNN architecture and error-correcting coding by demonstrating how state-of-the-art DNN architectures (ChordMixer, Mega, Mega-chunk, CDIL, ...) from the long-range arena can be equivalent to specific types (Cage-graph, Repeat Accumulate) of block and convolutional LDPC codes. QC codes correspond to certain types of chemical elements, with the carbon element being represented by the mixed automorphism Shu-Lin-Fossorier QC-LDPC code. The Quantum Approximate Optimization Algorithm (QAOA) used in the Sherrington-Kirkpatrick Ising model can be seen as analogous to the back-propagation loss function landscape in training DNNs. This similarity creates a comparable problem with TS pseudo-codeword, resembling the belief propagation method. Additionally, the layer depth in QAOA correlates to the number of decoding belief propagation iterations in the Wiberg decoding tree. Overall, this work has the potential to advance multiple fields, from Information Theory, DNN architecture design (sparse and structured prior graph topology), efficient hardware design for Quantum and Classical DPU/TPU (graph, quantize and shift register architect.) to Materials Science and beyond.
Self-supervised similarity models based on well-logging data
Sep 26, 2022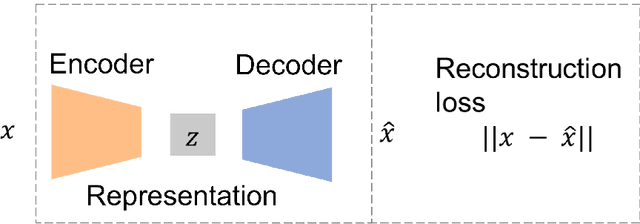

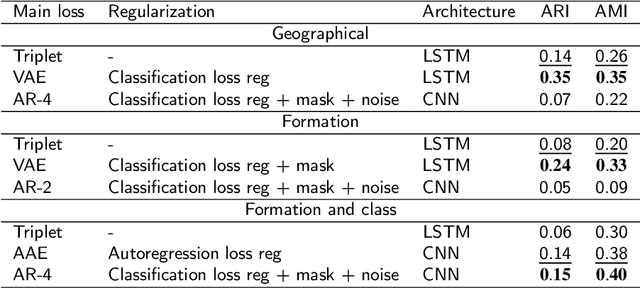
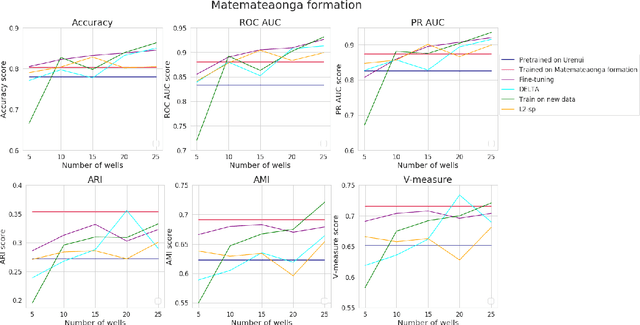
Adopting data-based approaches leads to model improvement in numerous Oil&Gas logging data processing problems. These improvements become even more sound due to new capabilities provided by deep learning. However, usage of deep learning is limited to areas where researchers possess large amounts of high-quality data. We present an approach that provides universal data representations suitable for solutions to different problems for different oil fields with little additional data. Our approach relies on the self-supervised methodology for sequential logging data for intervals from well, so it also doesn't require labelled data from the start. For validation purposes of the received representations, we consider classification and clusterization problems. We as well consider the transfer learning scenario. We found out that using the variational autoencoder leads to the most reliable and accurate models. approach We also found that a researcher only needs a tiny separate data set for the target oil field to solve a specific problem on top of universal representations.