 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapes of Cognition for Computational Cognitive Modeling
Sep 16, 2025Shapes of cognition is a new conceptual paradigm for the computational cognitive modeling of Language-Endowed Intelligent Agents (LEIAs). Shapes are remembered constellations of sensory, linguistic, conceptual, episodic, and procedural knowledge that allow agents to cut through the complexity of real life the same way as people do: by expecting things to be typical, recognizing patterns, acting by habit, reasoning by analogy, satisficing, and generally minimizing cognitive load to the degree situations permit. Atypical outcomes are treated using shapes-based recovery methods, such as learning on the fly, asking a human partner for help, or seeking an actionable, even if imperfect, situational understanding. Although shapes is an umbrella term, it is not vague: shapes-based modeling involves particular objectives, hypotheses, modeling strategies, knowledge bases, and actual models of wide-ranging phenomena, all implemented within a particular cognitive architecture. Such specificity is needed both to vet our hypotheses and to achieve our practical aims of building useful agent systems that are explainable, extensible, and worthy of our trust, even in critical domains. However, although the LEIA example of shapes-based modeling is specific, the principles can be applied more broadly, giving new life to knowledge-based and hybrid AI.
HARMONIC: A Content-Centric Cognitive Robotic Architecture
Sep 16, 2025This paper introduces HARMONIC, a cognitive-robotic architecture designed for robots in human-robotic teams. HARMONIC supports semantic perception interpretation, human-like decision-making, and intentional language communication. It addresses the issues of safety and quality of results; aims to solve problems of data scarcity, explainability, and safety; and promotes transparency and trust. Two proof-of-concept HARMONIC-based robotic systems are demonstrated, each implemented in both a high-fidelity simulation environment and on physical robotic platforms.
HARMONIC: A Framework for Explanatory Cognitive Robots
Sep 26, 2024We present HARMONIC, a framework for implementing cognitive robots that transforms general-purpose robots into trusted teammates capable of complex decision-making, natural communication and human-level explanation. The framework supports interoperability between a strategic (cognitive) layer for high-level decision-making and a tactical (robot) layer for low-level control and execution. We describe the core features of the framework and our initial implementation, in which HARMONIC was deployed on a simulated UGV and drone involved in a multi-robot search and retrieval task.
HARMONIC: Cognitive and Control Collaboration in Human-Robotic Teams
Sep 26, 2024



This paper presents a novel approach to multi-robot planning and collaboration. We demonstrate a cognitive strategy for robots in human-robot teams that incorporates metacognition, natural language communication, and explainability. The system is embodied using the HARMONIC architecture that flexibly integrates cognitive and control capabilities across the team. We evaluate our approach through simulation experiments involving a joint search task by a team of heterogeneous robots (a UGV and a drone) and a human. We detail the system's handling of complex, real-world scenarios, effective action coordination between robots with different capabilities, and natural human-robot communication. This work demonstrates that the robots' ability to reason about plans, goals, and attitudes, and to provide explanations for actions and decisions are essential prerequisites for realistic human-robot teaming.
Explaining Explaining
Sep 26, 2024Explanation is key to people having confidence in high-stakes AI systems. However, machine-learning-based systems - which account for almost all current AI - can't explain because they are usually black boxes. The explainable AI (XAI) movement hedges this problem by redefining "explanation". The human-centered explainable AI (HCXAI) movement identifies the explanation-oriented needs of users but can't fulfill them because of its commitment to machine learning. In order to achieve the kinds of explanations needed by real people operating in critical domains, we must rethink how to approach AI. We describe a hybrid approach to developing cognitive agents that uses a knowledge-based infrastructure supplemented by data obtained through machine learning when applicable. These agents will serve as assistants to humans who will bear ultimate responsibility for the decisions and actions of the human-robot team. We illustrate the explanatory potential of such agents using the under-the-hood panels of a demonstration system in which a team of simulated robots collaborates on a search task assigned by a human.
Metacognitive AI: Framework and the Case for a Neurosymbolic Approach
Jun 17, 2024
Metacognition is the concept of reasoning about an agent's own internal processes and was originally introduced in the field of developmental psychology. In this position paper, we examine the concept of applying metacognition to artificial intelligence. We introduce a framework for understanding metacognitive artificial intelligence (AI) that we call TRAP: transparency, reasoning, adaptation, and perception. We discuss each of these aspects in-turn and explore how neurosymbolic AI (NSAI) can be leveraged to address challenges of metacognition.
Automating Knowledge Acquisition for Content-Centric Cognitive Agents Using LLMs
Dec 27, 2023



The paper describes a system that uses large language model (LLM) technology to support the automatic learning of new entries in an intelligent agent's semantic lexicon. The process is bootstrapped by an existing non-toy lexicon and a natural language generator that converts formal, ontologically-grounded representations of meaning into natural language sentences. The learning method involves a sequence of LLM requests and includes an automatic quality control step. To date, this learning method has been applied to learning multiword expressions whose meanings are equivalent to those of transitive verbs in the agent's lexicon. The experiment demonstrates the benefits of a hybrid learning architecture that integrates knowledge-based methods and resources with both traditional data analytics and LLMs.
Knowledge Engineering in the Long Game of Artificial Intelligence: The Case of Speech Acts
Feb 02, 2022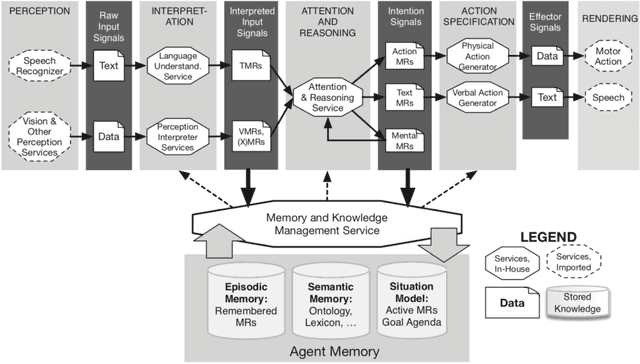



This paper describes principles and practices of knowledge engineering that enable the development of holistic language-endowed intelligent agents that can function across domains and applications, as well as expand their ontological and lexical knowledge through lifelong learning. For illustration, we focus on dialog act modeling, a task that has been widely pursued in linguistics, cognitive modeling, and statistical natural language processing. We describe an integrative approach grounded in the OntoAgent knowledge-centric cognitive architecture and highlight the limitations of past approaches that isolate dialog from other agent functionalities.
From Submit to Submitted via Submission: On Lexical Rules in Large-Scale Lexicon Acquisition
Jul 08, 1996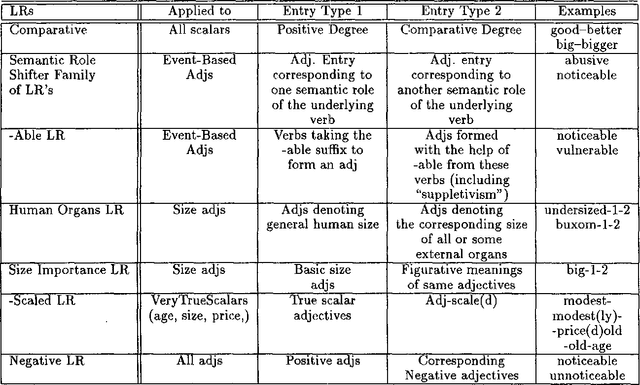
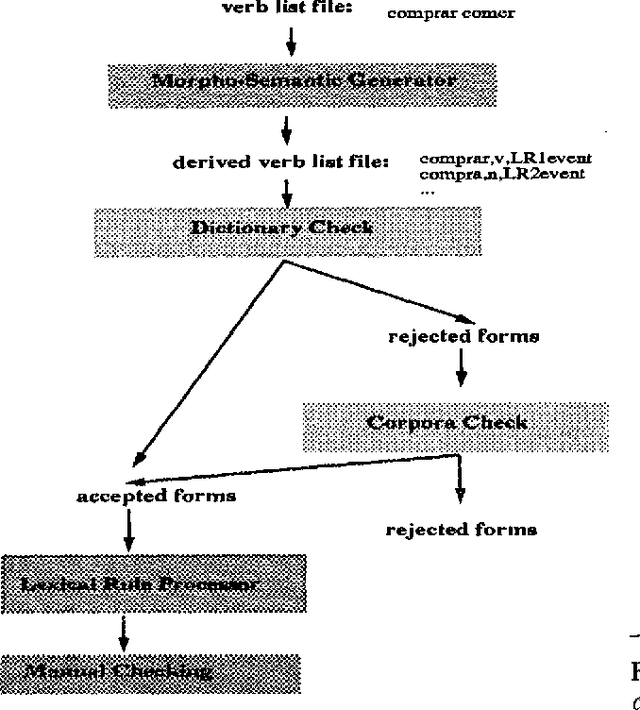

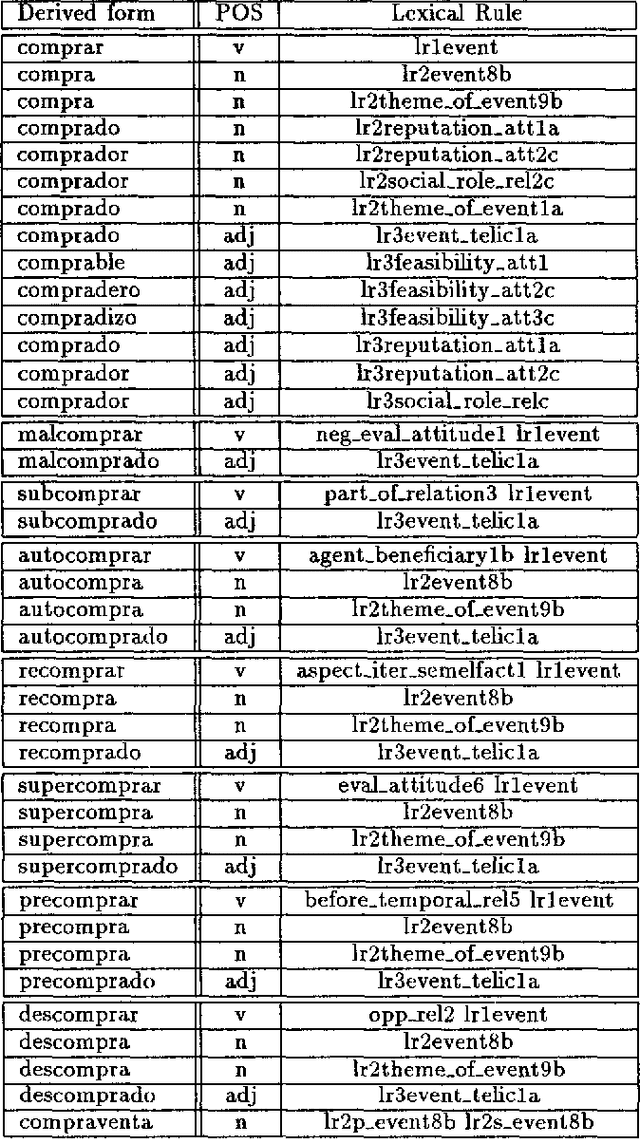
This paper deals with the discovery, representation, and use of lexical rules (LRs) during large-scale semi-automatic computational lexicon acquisition. The analysis is based on a set of LRs implemented and tested on the basis of Spanish and English business- and finance-related corpora. We show that, though the use of LRs is justified, they do not come cost-free. Semi-automatic output checking is required, even with blocking and preemtion procedures built in. Nevertheless, large-scope LRs are justified because they facilitate the unavoidable process of large-scale semi-automatic lexical acquisition. We also argue that the place of LRs in the computational process is a complex issue.