 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOP-SPIN: TOPic discovery via Sparse Principal component INterference
Nov 04, 2013
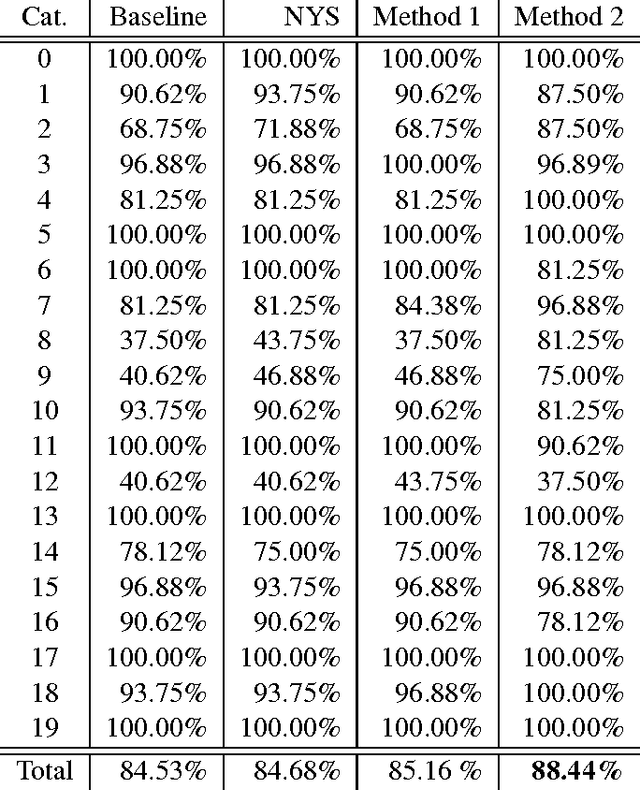
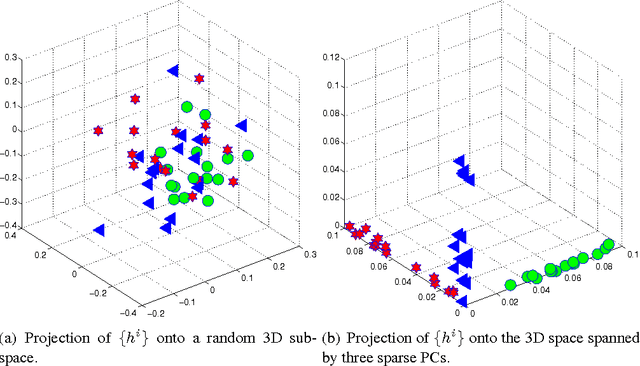
We propose a novel topic discovery algorithm for unlabeled images based on the bag-of-words (BoW) framework. We first extract a dictionary of visual words and subsequently for each image compute a visual word occurrence histogram. We view these histograms as rows of a large matrix from which we extract sparse principal components (PCs). Each PC identifies a sparse combination of visual words which co-occur frequently in some images but seldom appear in others. Each sparse PC corresponds to a topic, and images whose interference with the PC is high belong to that topic, revealing the common parts possessed by the images. We propose to solve the associated sparse PCA problems using an Alternating Maximization (AM) method, which we modify for purpose of efficiently extracting multiple PCs in a deflation scheme. Our approach attacks the maximization problem in sparse PCA directly and is scalable to high-dimensional data. Experiments on automatic topic discovery and category prediction demonstrate encouraging performance of our approach.
Alternating Maximization: Unifying Framework for 8 Sparse PCA Formulations and Efficient Parallel Codes
Dec 17, 2012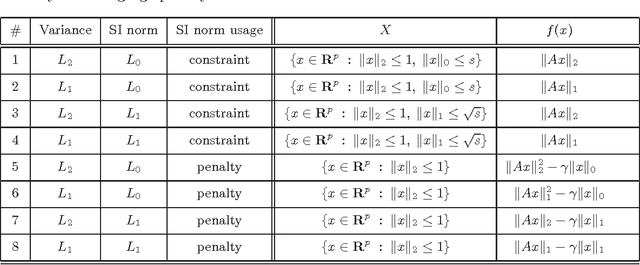

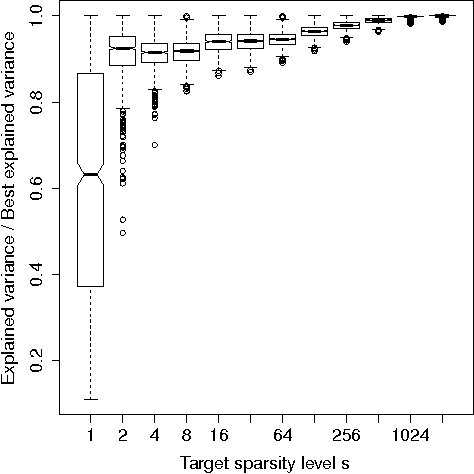
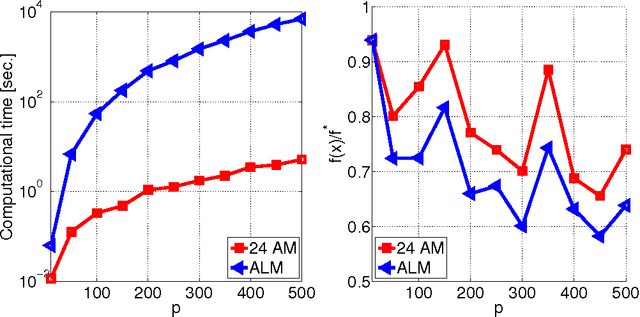
Given a multivariate data set, sparse principal component analysis (SPCA) aims to extract several linear combinations of the variables that together explain the variance in the data as much as possible, while controlling the number of nonzero loadings in these combinations. In this paper we consider 8 different optimization formulations for computing a single sparse loading vector; these are obtained by combining the following factors: we employ two norms for measuring variance (L2, L1) and two sparsity-inducing norms (L0, L1), which are used in two different ways (constraint, penalty). Three of our formulations, notably the one with L0 constraint and L1 variance, have not been considered in the literature. We give a unifying reformulation which we propose to solve via a natural alternating maximization (AM) method. We show the the AM method is nontrivially equivalent to GPower (Journ\'{e}e et al; JMLR 11:517--553, 2010) for all our formulations. Besides this, we provide 24 efficient parallel SPCA implementations: 3 codes (multi-core, GPU and cluster) for each of the 8 problems. Parallelism in the methods is aimed at i) speeding up computations (our GPU code can be 100 times faster than an efficient serial code written in C++), ii) obtaining solutions explaining more variance and iii) dealing with big data problems (our cluster code is able to solve a 357 GB problem in about a minute).