 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Posterior Sampling: A Feynman-Kac Analysis of Bias and Stability
May 07, 2026Diffusion-based posterior samplers use pretrained diffusion priors to sample from measurement- or reward-conditioned posteriors, and are widely used for inverse problems. Yet their theoretical behavior remains poorly understood: even with exact prior scores, their outputs are biased, and in low-temperature regimes their discretizations can become unstable. We characterize this bias by introducing a tractable surrogate path connecting the true posterior to a standard Gaussian and comparing it to the sampler's path. Their density ratio satisfies a parabolic PDE whose reaction term measures the accumulated bias. A Feynman-Kac representation then expresses the Radon-Nikodym correction as an explicit path expectation, identifying which posterior regions are over- or under-sampled. We apply this framework to DPS and STSL, a related sampler. For DPS, the correction is an Ornstein-Uhlenbeck path expectation coupling the data conditional covariance with the reward curvature, revealing where DPS over- or under-samples. Next, we reinterpret STSL as an auxiliary drift that steers trajectories toward low-uncertainty regions, flattening the spatially varying part of the DPS reaction term. Finally, we characterize early guidance-stopping, a common mitigation for low-temperature instabilities caused by forward-Euler integration of the vector field. Together, these results clarify sampler bias, explain existing correctives, and guide stable variant designs.
EmDT: Embedding Diffusion Transformer for Tabular Data Generation in Fraud Detection
Mar 13, 2026Imbalanced datasets pose a difficulty in fraud detection, as classifiers are often biased toward the majority class and perform poorly on rare fraudulent transactions. Synthetic data generation is therefore commonly used to mitigate this problem. In this work, we propose the Clustered Embedding Diffusion-Transformer (EmDT), a diffusion model designed to generate fraudulent samples. Our key innovation is to leverage UMAP clustering to identify distinct fraudulent patterns, and train a Transformer denoising network with sinusoidal positional embeddings to capture feature relationships throughout the diffusion process. Once the synthetic data has been generated, we employ a standard decision-tree-based classifier (e.g., XGBoost) for classification, as this type of model remains better suited to tabular datasets. Experiments on a credit card fraud detection dataset demonstrate that EmDT significantly improves downstream classification performance compared to existing oversampling and generative methods, while maintaining comparable privacy protection and preserving feature correlations present in the original data.
Lesion segmentation using U-Net network
Jul 23, 2018
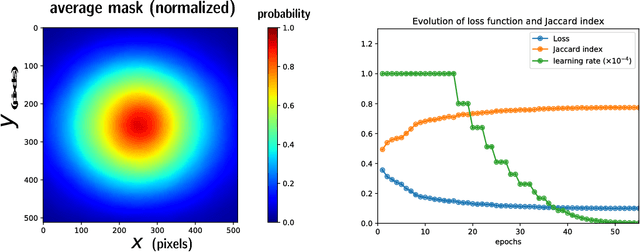
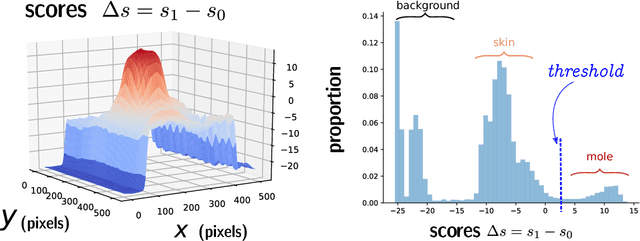
This paper explains the method used in the segmentation challenge (Task 1) in the International Skin Imaging Collaboration's (ISIC) Skin Lesion Analysis Towards Melanoma Detection challenge held in 2018. We have trained a U-Net network to perform the segmentation. The key elements for the training were first to adjust the loss function to incorporate unbalanced proportion of background and second to perform post-processing operation to adjust the contour of the prediction.