 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Subspace Noise Injection Prevents Accuracy Collapse in Certified Unlearning
Jan 08, 2026Certified unlearning based on differential privacy offers strong guarantees but remains largely impractical: the noisy fine-tuning approaches proposed so far achieve these guarantees but severely reduce model accuracy. We propose sequential noise scheduling, which distributes the noise budget across orthogonal subspaces of the parameter space, rather than injecting it all at once. This simple modification mitigates the destructive effect of noise while preserving the original certification guarantees. We extend the analysis of noisy fine-tuning to the subspace setting, proving that the same $(\varepsilon,δ)$ privacy budget is retained. Empirical results on image classification benchmarks show that our approach substantially improves accuracy after unlearning while remaining robust to membership inference attacks. These results show that certified unlearning can achieve both rigorous guarantees and practical utility.
Exploiting Similarity for Computation and Communication-Efficient Decentralized Optimization
Jun 06, 2025Reducing communication complexity is critical for efficient decentralized optimization. The proximal decentralized optimization (PDO) framework is particularly appealing, as methods within this framework can exploit functional similarity among nodes to reduce communication rounds. Specifically, when local functions at different nodes are similar, these methods achieve faster convergence with fewer communication steps. However, existing PDO methods often require highly accurate solutions to subproblems associated with the proximal operator, resulting in significant computational overhead. In this work, we propose the Stabilized Proximal Decentralized Optimization (SPDO) method, which achieves state-of-the-art communication and computational complexities within the PDO framework. Additionally, we refine the analysis of existing PDO methods by relaxing subproblem accuracy requirements and leveraging average functional similarity. Experimental results demonstrate that SPDO significantly outperforms existing methods.
Accelerated Distributed Optimization with Compression and Error Feedback
Mar 11, 2025Modern machine learning tasks often involve massive datasets and models, necessitating distributed optimization algorithms with reduced communication overhead. Communication compression, where clients transmit compressed updates to a central server, has emerged as a key technique to mitigate communication bottlenecks. However, the theoretical understanding of stochastic distributed optimization with contractive compression remains limited, particularly in conjunction with Nesterov acceleration -- a cornerstone for achieving faster convergence in optimization. In this paper, we propose a novel algorithm, ADEF (Accelerated Distributed Error Feedback), which integrates Nesterov acceleration, contractive compression, error feedback, and gradient difference compression. We prove that ADEF achieves the first accelerated convergence rate for stochastic distributed optimization with contractive compression in the general convex regime. Numerical experiments validate our theoretical findings and demonstrate the practical efficacy of ADEF in reducing communication costs while maintaining fast convergence.
Scalable Decentralized Learning with Teleportation
Jan 25, 2025Decentralized SGD can run with low communication costs, but its sparse communication characteristics deteriorate the convergence rate, especially when the number of nodes is large. In decentralized learning settings, communication is assumed to occur on only a given topology, while in many practical cases, the topology merely represents a preferred communication pattern, and connecting to arbitrary nodes is still possible. Previous studies have tried to alleviate the convergence rate degradation in these cases by designing topologies with large spectral gaps. However, the degradation is still significant when the number of nodes is substantial. In this work, we propose TELEPORTATION. TELEPORTATION activates only a subset of nodes, and the active nodes fetch the parameters from previous active nodes. Then, the active nodes update their parameters by SGD and perform gossip averaging on a relatively small topology comprising only the active nodes. We show that by activating only a proper number of nodes, TELEPORTATION can completely alleviate the convergence rate degradation. Furthermore, we propose an efficient hyperparameter-tuning method to search for the appropriate number of nodes to be activated. Experimentally, we showed that TELEPORTATION can train neural networks more stably and achieve higher accuracy than Decentralized SGD.
Decoupled SGDA for Games with Intermittent Strategy Communication
Jan 24, 2025We focus on reducing communication overhead in multiplayer games, where frequently exchanging strategies between players is not feasible and players have noisy or outdated strategies of the other players. We introduce Decoupled SGDA, a novel adaptation of Stochastic Gradient Descent Ascent (SGDA). In this approach, players independently update their strategies based on outdated opponent strategies, with periodic synchronization to align strategies. For Strongly-Convex-Strongly-Concave (SCSC) games, we demonstrate that Decoupled SGDA achieves near-optimal communication complexity comparable to the best-known GDA rates. For weakly coupled games where the interaction between players is lower relative to the non-interactive part of the game, Decoupled SGDA significantly reduces communication costs compared to standard SGDA. Our findings extend to multi-player games. To provide insights into the effect of communication frequency and convergence, we extensively study the convergence of Decoupled SGDA for quadratic minimax problems. Lastly, in settings where the noise over the players is imbalanced, Decoupled SGDA significantly outperforms federated minimax methods.
Stabilized Proximal-Point Methods for Federated Optimization
Jul 09, 2024In developing efficient optimization algorithms, it is crucial to account for communication constraints -- a significant challenge in modern federated learning settings. The best-known communication complexity among non-accelerated algorithms is achieved by DANE, a distributed proximal-point algorithm that solves local subproblems in each iteration and that can exploit second-order similarity among individual functions. However, to achieve such communication efficiency, the accuracy requirement for solving the local subproblems is slightly sub-optimal. Inspired by the hybrid projection-proximal point method, in this work, we i) propose a novel distributed algorithm S-DANE. This method adopts a more stabilized prox-center in the proximal step compared with DANE, and matches its deterministic communication complexity. Moreover, the accuracy condition of the subproblem is milder, leading to enhanced local computation efficiency. Furthermore, it supports partial client participation and arbitrary stochastic local solvers, making it more attractive in practice. We further ii) accelerate S-DANE, and show that the resulting algorithm achieves the best-known communication complexity among all existing methods for distributed convex optimization, with the same improved local computation efficiency as S-DANE.
Near Optimal Decentralized Optimization with Compression and Momentum Tracking
May 30, 2024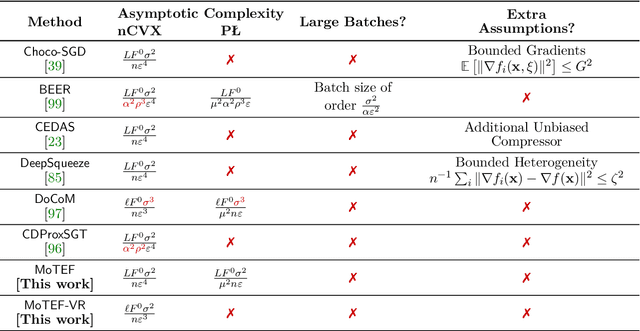
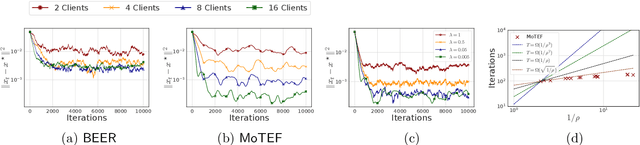
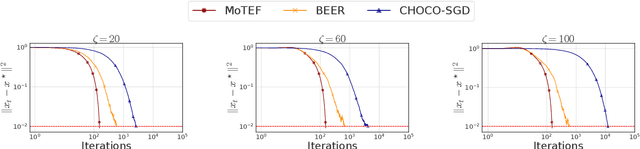
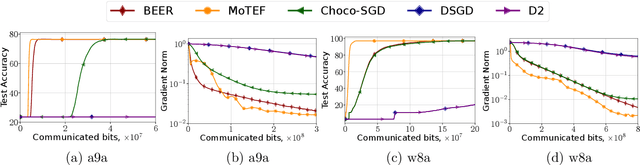
Communication efficiency has garnered significant attention as it is considered the main bottleneck for large-scale decentralized Machine Learning applications in distributed and federated settings. In this regime, clients are restricted to transmitting small amounts of quantized information to their neighbors over a communication graph. Numerous endeavors have been made to address this challenging problem by developing algorithms with compressed communication for decentralized non-convex optimization problems. Despite considerable efforts, the current results suffer from various issues such as non-scalability with the number of clients, requirements for large batches, or bounded gradient assumption. In this paper, we introduce MoTEF, a novel approach that integrates communication compression with Momentum Tracking and Error Feedback. Our analysis demonstrates that MoTEF achieves most of the desired properties, and significantly outperforms existing methods under arbitrary data heterogeneity. We provide numerical experiments to validate our theoretical findings and confirm the practical superiority of MoTEF.
The Limits and Potentials of Local SGD for Distributed Heterogeneous Learning with Intermittent Communication
May 19, 2024



Local SGD is a popular optimization method in distributed learning, often outperforming other algorithms in practice, including mini-batch SGD. Despite this success, theoretically proving the dominance of local SGD in settings with reasonable data heterogeneity has been difficult, creating a significant gap between theory and practice. In this paper, we provide new lower bounds for local SGD under existing first-order data heterogeneity assumptions, showing that these assumptions are insufficient to prove the effectiveness of local update steps. Furthermore, under these same assumptions, we demonstrate the min-max optimality of accelerated mini-batch SGD, which fully resolves our understanding of distributed optimization for several problem classes. Our results emphasize the need for better models of data heterogeneity to understand the effectiveness of local SGD in practice. Towards this end, we consider higher-order smoothness and heterogeneity assumptions, providing new upper bounds that imply the dominance of local SGD over mini-batch SGD when data heterogeneity is low.
Federated Optimization with Doubly Regularized Drift Correction
Apr 12, 2024Federated learning is a distributed optimization paradigm that allows training machine learning models across decentralized devices while keeping the data localized. The standard method, FedAvg, suffers from client drift which can hamper performance and increase communication costs over centralized methods. Previous works proposed various strategies to mitigate drift, yet none have shown uniformly improved communication-computation trade-offs over vanilla gradient descent. In this work, we revisit DANE, an established method in distributed optimization. We show that (i) DANE can achieve the desired communication reduction under Hessian similarity constraints. Furthermore, (ii) we present an extension, DANE+, which supports arbitrary inexact local solvers and has more freedom to choose how to aggregate the local updates. We propose (iii) a novel method, FedRed, which has improved local computational complexity and retains the same communication complexity compared to DANE/DANE+. This is achieved by using doubly regularized drift correction.
Non-Convex Stochastic Composite Optimization with Polyak Momentum
Mar 05, 2024The stochastic proximal gradient method is a powerful generalization of the widely used stochastic gradient descent (SGD) method and has found numerous applications in Machine Learning. However, it is notoriously known that this method fails to converge in non-convex settings where the stochastic noise is significant (i.e. when only small or bounded batch sizes are used). In this paper, we focus on the stochastic proximal gradient method with Polyak momentum. We prove this method attains an optimal convergence rate for non-convex composite optimization problems, regardless of batch size. Additionally, we rigorously analyze the variance reduction effect of the Polyak momentum in the composite optimization setting and we show the method also converges when the proximal step can only be solved inexactly. Finally, we provide numerical experiments to validate our theoretical results.