 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTucker Attention: A generalization of approximate attention mechanisms
Mar 31, 2026The pursuit of reducing the memory footprint of the self-attention mechanism in multi-headed self attention (MHA) spawned a rich portfolio of methods, e.g., group-query attention (GQA) and multi-head latent attention (MLA). The methods leverage specialized low-rank factorizations across embedding dimensions or attention heads. From the point of view of classical low-rank approximation, these methods are unconventional and raise questions of which objects they really approximate and how to interpret the low-rank behavior of the resulting representations. To answer these questions, this work proposes a generalized view on the weight objects in the self-attention layer and a factorization strategy, which allows us to construct a parameter efficient scheme, called Tucker Attention. Tucker Attention requires an order of magnitude fewer parameters for comparable validation metrics, compared to GQA and MLA, as evaluated in LLM and ViT test cases. Additionally, Tucker Attention~encompasses GQA, MLA, MHA as special cases and is fully compatible with flash-attention and rotary position embeddings (RoPE). This generalization strategy yields insights of the actual ranks achieved by MHA, GQA, and MLA, and further enables simplifications for MLA.
Mitigating Subject Dependency in EEG Decoding with Subject-Specific Low-Rank Adapters
Oct 09, 2025Subject-specific distribution shifts represent an important obstacle to the development of foundation models for EEG decoding. To address this, we propose Subject-Conditioned Layer,, an adaptive layer designed as a drop-in replacement for standard linear or convolutional layers in any neural network architecture. Our layer captures subject-specific variability by decomposing its weights into a shared, subject-invariant component and a lightweight, low-rank correction unique to each subject. This explicit separation of general knowledge from personalized adaptation allows existing models to become robust to subject shifts. Empirically, models equipped with our layer outperform both a shared-weight-only model (subject-agnostic model) and the average of individually trained subject-specific models. Consequently, the Subject-Conditioned Layer, offers a practical and scalable path towards building effective cross-subject foundation models for EEG.
An analysis of optimization problems involving ReLU neural networks
Feb 05, 2025



Solving mixed-integer optimization problems with embedded neural networks with ReLU activation functions is challenging. Big-M coefficients that arise in relaxing binary decisions related to these functions grow exponentially with the number of layers. We survey and propose different approaches to analyze and improve the run time behavior of mixed-integer programming solvers in this context. Among them are clipped variants and regularization techniques applied during training as well as optimization-based bound tightening and a novel scaling for given ReLU networks. We numerically compare these approaches for three benchmark problems from the literature. We use the number of linear regions, the percentage of stable neurons, and overall computational effort as indicators. As a major takeaway we observe and quantify a trade-off between the often desired redundancy of neural network models versus the computational costs for solving related optimization problems.
AudioPairBank: Towards A Large-Scale Tag-Pair-Based Audio Content Analysis
Jan 08, 2018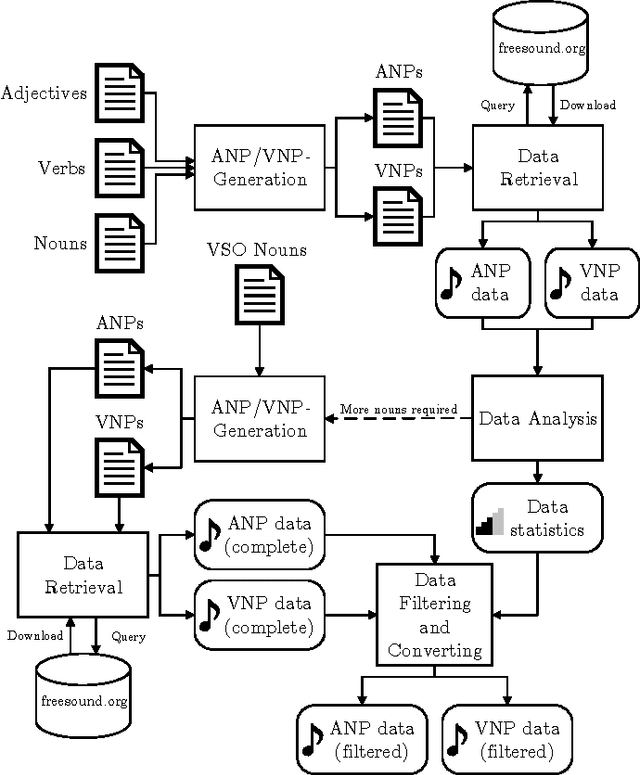
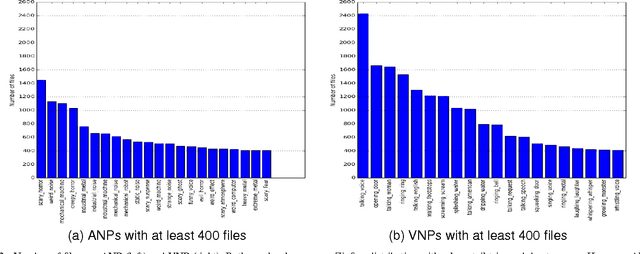
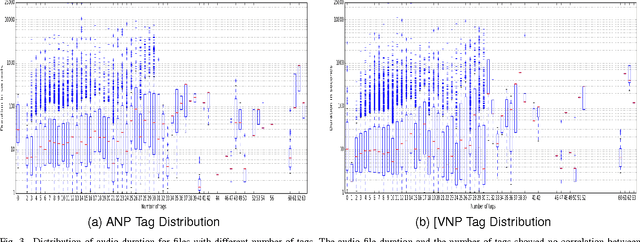
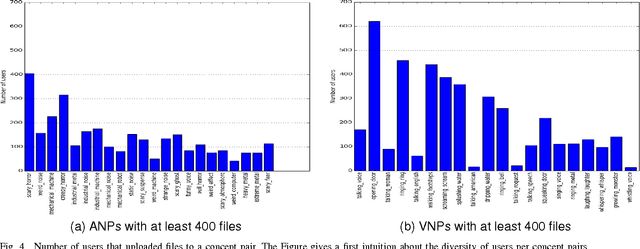
Recently, sound recognition has been used to identify sounds, such as car and river. However, sounds have nuances that may be better described by adjective-noun pairs such as slow car, and verb-noun pairs such as flying insects, which are under explored. Therefore, in this work we investigate the relation between audio content and both adjective-noun pairs and verb-noun pairs. Due to the lack of datasets with these kinds of annotations, we collected and processed the AudioPairBank corpus consisting of a combined total of 1,123 pairs and over 33,000 audio files. One contribution is the previously unavailable documentation of the challenges and implications of collecting audio recordings with these type of labels. A second contribution is to show the degree of correlation between the audio content and the labels through sound recognition experiments, which yielded results of 70% accuracy, hence also providing a performance benchmark. The results and study in this paper encourage further exploration of the nuances in audio and are meant to complement similar research performed on images and text in multimedia analysis.