 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Anomaly Detection with Sequential Hypothesis Testing for Robotic Sewer Inspection
Jul 30, 2025Sewer pipe faults, such as leaks and blockages, can lead to severe consequences including groundwater contamination, property damage, and service disruption. Traditional inspection methods rely heavily on the manual review of CCTV footage collected by mobile robots, which is inefficient and susceptible to human error. To automate this process, we propose a novel system incorporating explainable deep learning anomaly detection combined with sequential probability ratio testing (SPRT). The anomaly detector processes single image frames, providing interpretable spatial localisation of anomalies, whilst the SPRT introduces temporal evidence aggregation, enhancing robustness against noise over sequences of image frames. Experimental results demonstrate improved anomaly detection performance, highlighting the benefits of the combined spatiotemporal analysis system for reliable and robust sewer inspection.
A temporal-to-spatial deep convolutional neural network for classification of hand movements from multichannel electromyography data
Aug 19, 2020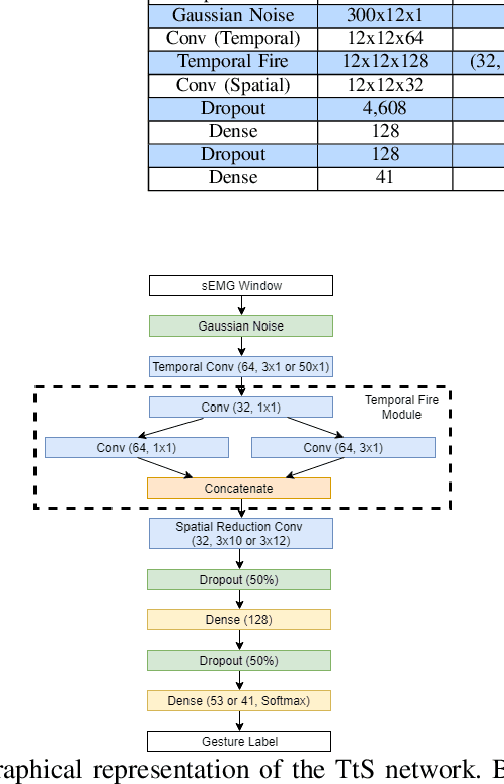
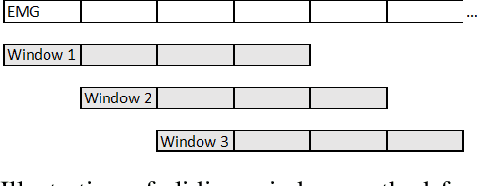
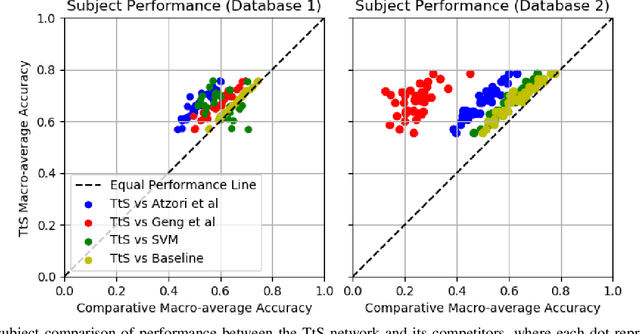
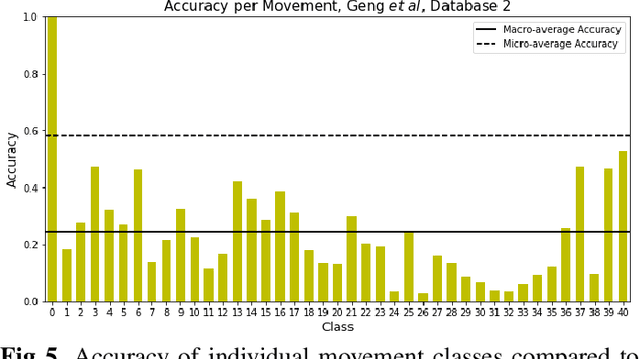
Deep convolutional neural networks (CNNs) are appealing for the purpose of classification of hand movements from surface electromyography (sEMG) data because they have the ability to perform automated person-specific feature extraction from raw data. In this paper, we make the novel contribution of proposing and evaluating a design for the early processing layers in the deep CNN for multichannel sEMG. Specifically, we propose a novel temporal-to-spatial (TtS) CNN architecture, where the first layer performs convolution separately on each sEMG channel to extract temporal features. This is motivated by the idea that sEMG signals in each channel are mediated by one or a small subset of muscles, whose temporal activation patterns are associated with the signature features of a gesture. The temporal layer captures these signature features for each channel separately, which are then spatially mixed in successive layers to recognise a specific gesture. A practical advantage is that this approach also makes the CNN simple to design for different sample rates. We use NinaPro database 1 (27 subjects and 52 movements + rest), sampled at 100 Hz, and database 2 (40 subjects and 40 movements + rest), sampled at 2 kHz, to evaluate our proposed CNN design. We benchmark against a feature-based support vector machine (SVM) classifier, two CNNs from the literature, and an additional standard design of CNN. We find that our novel TtS CNN design achieves 66.6% per-class accuracy on database 1, and 67.8% on database 2, and that the TtS CNN outperforms all other compared classifiers using a statistical hypothesis test at the 2% significance level.
Foveated image processing for faster object detection and recognition in embedded systems using deep convolutional neural networks
Aug 15, 2019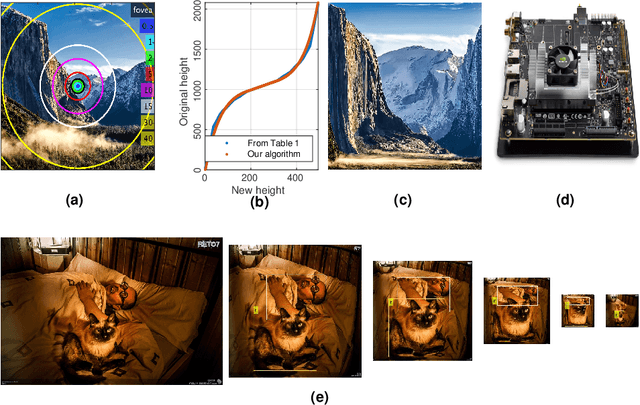

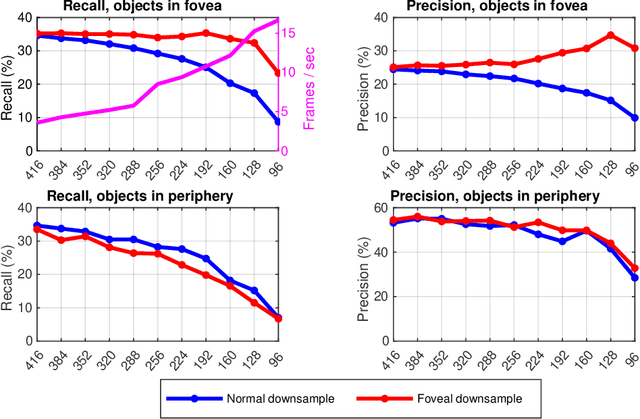
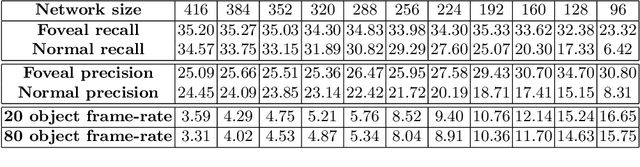
Object detection and recognition algorithms using deep convolutional neural networks (CNNs) tend to be computationally intensive to implement. This presents a particular challenge for embedded systems, such as mobile robots, where the computational resources tend to be far less than for workstations. As an alternative to standard, uniformly sampled images, we propose the use of foveated image sampling here to reduce the size of images, which are faster to process in a CNN due to the reduced number of convolution operations. We evaluate object detection and recognition on the Microsoft COCO database, using foveated image sampling at different image sizes, ranging from 416x416 to 96x96 pixels, on an embedded GPU -- an NVIDIA Jetson TX2 with 256 CUDA cores. The results show that it is possible to achieve a 4x speed-up in frame rates, from 3.59 FPS to 15.24 FPS, using 416x416 and 128x128 pixel images respectively. For foveated sampling, this image size reduction led to just a small decrease in recall performance in the foveal region, to 92.0% of the baseline performance with full-sized images, compared to a significant decrease to 50.1% of baseline recall performance in uniformly sampled images, demonstrating the advantage of foveated sampling.