 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal explainability of a deep abstaining classifier
Apr 01, 2025



We present a global explainability method to characterize sources of errors in the histology prediction task of our real-world multitask convolutional neural network (MTCNN)-based deep abstaining classifier (DAC), for automated annotation of cancer pathology reports from NCI-SEER registries. Our classifier was trained and evaluated on 1.04 million hand-annotated samples and makes simultaneous predictions of cancer site, subsite, histology, laterality, and behavior for each report. The DAC framework enables the model to abstain on ambiguous reports and/or confusing classes to achieve a target accuracy on the retained (non-abstained) samples, but at the cost of decreased coverage. Requiring 97% accuracy on the histology task caused our model to retain only 22% of all samples, mostly the less ambiguous and common classes. Local explainability with the GradInp technique provided a computationally efficient way of obtaining contextual reasoning for thousands of individual predictions. Our method, involving dimensionality reduction of approximately 13000 aggregated local explanations, enabled global identification of sources of errors as hierarchical complexity among classes, label noise, insufficient information, and conflicting evidence. This suggests several strategies such as exclusion criteria, focused annotation, and reduced penalties for errors involving hierarchically related classes to iteratively improve our DAC in this complex real-world implementation.
Domain Shift Analysis in Chest Radiographs Classification in a Veterans Healthcare Administration Population
Jul 30, 2024



Objectives: This study aims to assess the impact of domain shift on chest X-ray classification accuracy and to analyze the influence of ground truth label quality and demographic factors such as age group, sex, and study year. Materials and Methods: We used a DenseNet121 model pretrained MIMIC-CXR dataset for deep learning-based multilabel classification using ground truth labels from radiology reports extracted using the CheXpert and CheXbert Labeler. We compared the performance of the 14 chest X-ray labels on the MIMIC-CXR and Veterans Healthcare Administration chest X-ray dataset (VA-CXR). The VA-CXR dataset comprises over 259k chest X-ray images spanning between the years 2010 and 2022. Results: The validation of ground truth and the assessment of multi-label classification performance across various NLP extraction tools revealed that the VA-CXR dataset exhibited lower disagreement rates than the MIMIC-CXR datasets. Additionally, there were notable differences in AUC scores between models utilizing CheXpert and CheXbert. When evaluating multi-label classification performance across different datasets, minimal domain shift was observed in unseen datasets, except for the label "Enlarged Cardiomediastinum." The study year's subgroup analyses exhibited the most significant variations in multi-label classification model performance. These findings underscore the importance of considering domain shifts in chest X-ray classification tasks, particularly concerning study years. Conclusion: Our study reveals the significant impact of domain shift and demographic factors on chest X-ray classification, emphasizing the need for improved transfer learning and equitable model development. Addressing these challenges is crucial for advancing medical imaging and enhancing patient care.
An Effective Baseline for Robustness to Distributional Shift
May 15, 2021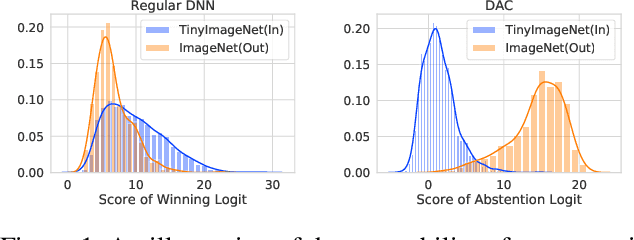
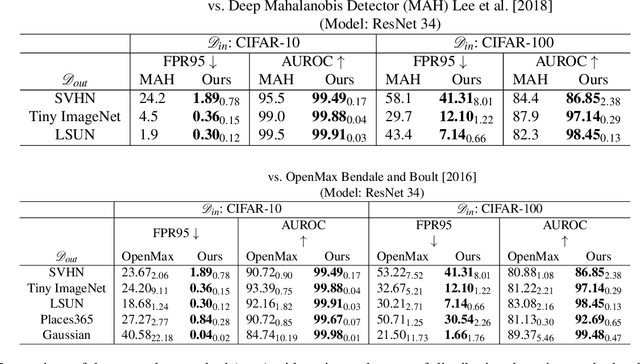
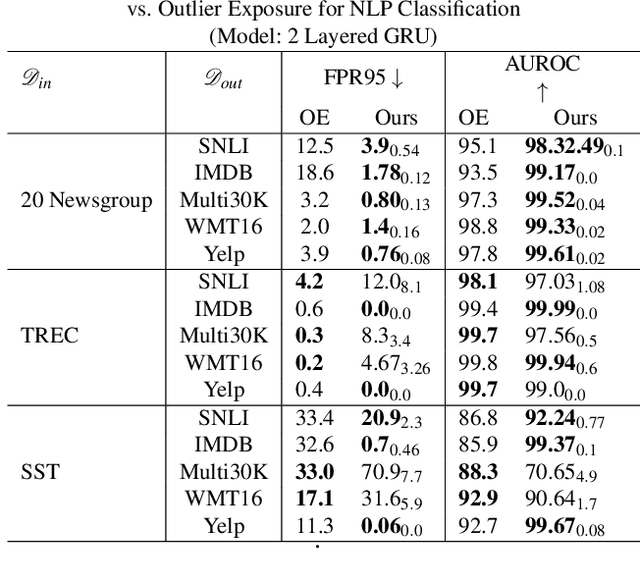
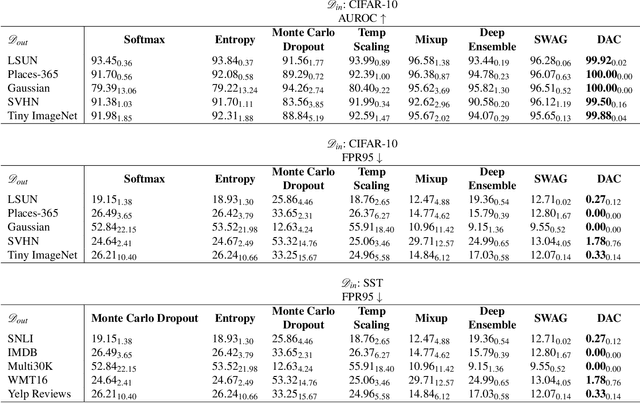
Refraining from confidently predicting when faced with categories of inputs different from those seen during training is an important requirement for the safe deployment of deep learning systems. While simple to state, this has been a particularly challenging problem in deep learning, where models often end up making overconfident predictions in such situations. In this work we present a simple, but highly effective approach to deal with out-of-distribution detection that uses the principle of abstention: when encountering a sample from an unseen class, the desired behavior is to abstain from predicting. Our approach uses a network with an extra abstention class and is trained on a dataset that is augmented with an uncurated set that consists of a large number of out-of-distribution (OoD) samples that are assigned the label of the abstention class; the model is then trained to learn an effective discriminator between in and out-of-distribution samples. We compare this relatively simple approach against a wide variety of more complex methods that have been proposed both for out-of-distribution detection as well as uncertainty modeling in deep learning, and empirically demonstrate its effectiveness on a wide variety of of benchmarks and deep architectures for image recognition and text classification, often outperforming existing approaches by significant margins. Given the simplicity and effectiveness of this method, we propose that this approach be used as a new additional baseline for future work in this domain.
Why I'm not Answering: Understanding Determinants of Classification of an Abstaining Classifier for Cancer Pathology Reports
Sep 24, 2020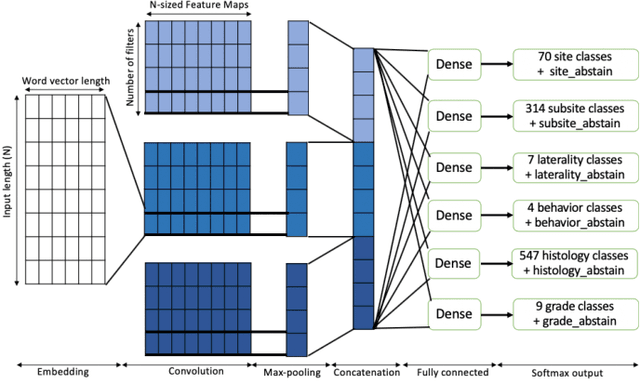

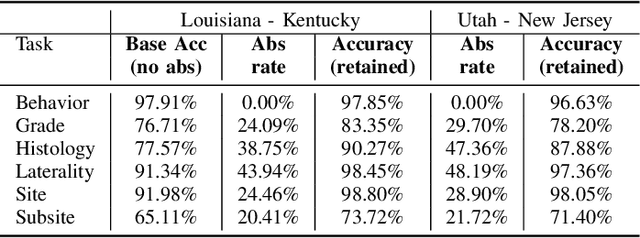
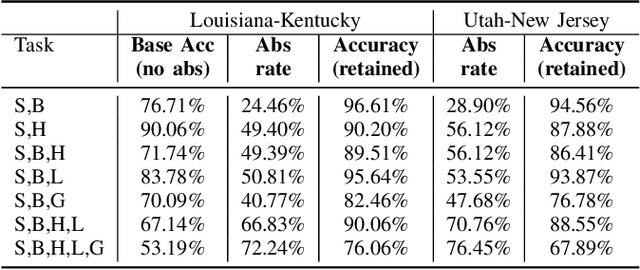
Safe deployment of deep learning systems in critical real world applications requires models to make few mistakes, and only under predictable circumstances. Development of such a model is not yet possible, in general. In this work, we address this problem with an abstaining classifier tuned to have $>$95% accuracy, and identify the determinants of abstention with LIME (the Local Interpretable Model-agnostic Explanations method). Essentially, we are training our model to learn the attributes of pathology reports that are likely to lead to incorrect classifications, albeit at the cost of reduced sensitivity. We demonstrate our method in a multitask setting to classify cancer pathology reports from the NCI SEER cancer registries on six tasks of greatest importance. For these tasks, we reduce the classification error rate by factors of 2-5 by abstaining on 25-45% of the reports. For the specific case of cancer site, we are able to identify metastasis and reports involving lymph nodes as responsible for many of the classification mistakes, and that the extent and types of mistakes vary systematically with cancer site (eg. breast, lung, and prostate). When combining across three of the tasks, our model classifies 50% of the reports with an accuracy greater than 95% for three of the six tasks and greater than 85% for all six tasks on the retained samples. By using this information, we expect to define work flows that incorporate machine learning only in the areas where it is sufficiently robust and accurate, saving human attention to areas where it is required.