 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Ignore the Tail: Decoupling top-K Probabilities for Efficient Language Model Distillation
Feb 24, 2026The core learning signal used in language model distillation is the standard Kullback-Leibler (KL) divergence between the student and teacher distributions. Traditional KL divergence tends to be dominated by the next tokens with the highest probabilities, i.e., the teacher's modes, thereby diminishing the influence of less probable yet potentially informative components of the output distribution. We propose a new tail-aware divergence that decouples the contribution of the teacher model's top-K predicted probabilities from that of lower-probability predictions, while maintaining the same computational profile as the KL Divergence. Our decoupled approach reduces the impact of the teacher modes and, consequently, increases the contribution of the tail of the distribution. Experimental results demonstrate that our modified distillation method yields competitive performance in both pre-training and supervised distillation of decoder models across various datasets. Furthermore, the distillation process is efficient and can be performed with a modest academic budget for large datasets, eliminating the need for industry-scale computing.
Multi-Label Learning with Provable Guarantee
Nov 01, 2016

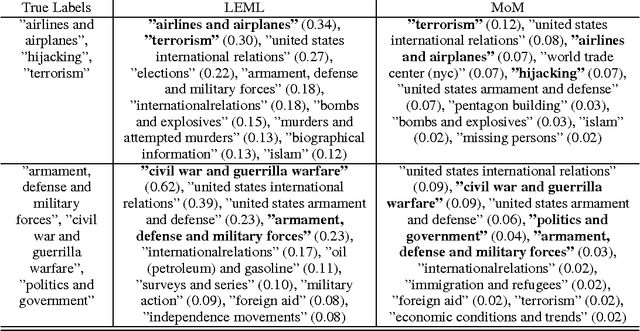
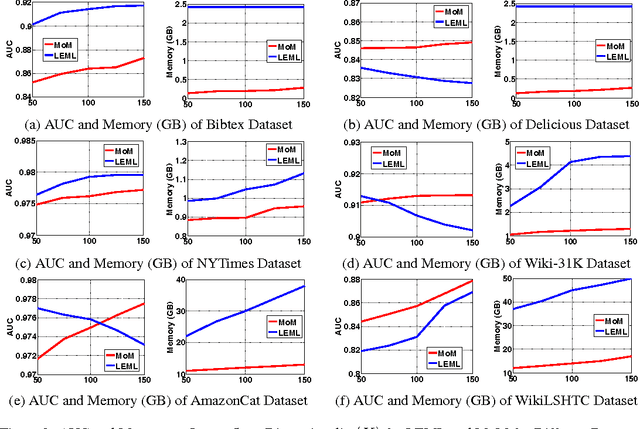
Here we study the problem of learning labels for large text corpora where each text can be assigned a variable number of labels. The problem might seem trivial when the label dimensionality is small and can be easily solved using a series of one-vs-all classifiers. However, as the label dimensionality increases to several thousand, the parameter space becomes extremely large, and it is no longer possible to use the one-vs-all technique. Here we propose a model based on the factorization of higher order moments of the words in the corpora, as well as the cross moment between the labels and the words for multi-label prediction. Our model provides guaranteed convergence bounds on the estimated parameters. Further, our model takes only three passes through the training dataset to extract the parameters, resulting in a highly scalable algorithm that can train on GB's of data consisting of millions of documents with hundreds of thousands of labels using a nominal resource of a single processor with 16GB RAM. Our model achieves 10x-15x order of speed-up on large-scale datasets while producing competitive performance in comparison with existing benchmark algorithms.
Seeding K-Means using Method of Moments
Oct 31, 2016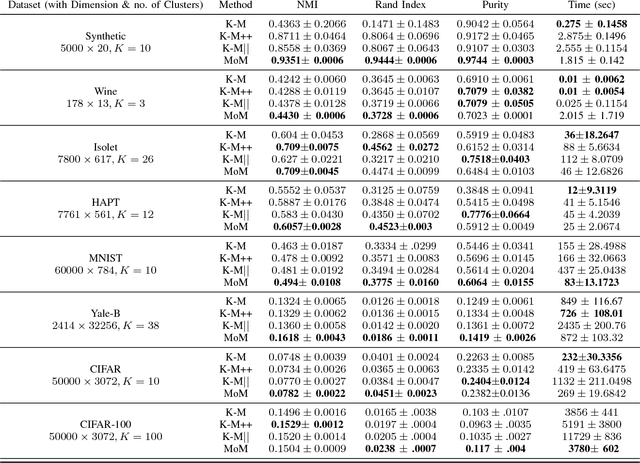
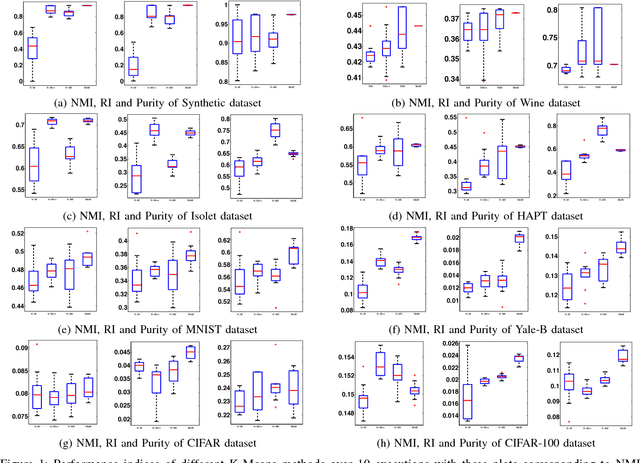


K-means is one of the most widely used algorithms for clustering in Data Mining applications, which attempts to minimize the sum of the square of the Euclidean distance of the points in the clusters from the respective means of the clusters. However, K-means suffers from local minima problem and is not guaranteed to converge to the optimal cost. K-means++ tries to address the problem by seeding the means using a distance-based sampling scheme. However, seeding the means in K-means++ needs $O\left(K\right)$ sequential passes through the entire dataset, and this can be very costly for large datasets. Here we propose a method of seeding the initial means based on factorizations of higher order moments for bounded data. Our method takes $O\left(1\right)$ passes through the entire dataset to extract the initial set of means, and its final cost can be proven to be within $O(\sqrt{K})$ of the optimal cost. We demonstrate the performance of our algorithm in comparison with the existing algorithms on various benchmark datasets.
Fast Collaborative Filtering from Implicit Feedback with Provable Guarantees
Aug 21, 2016
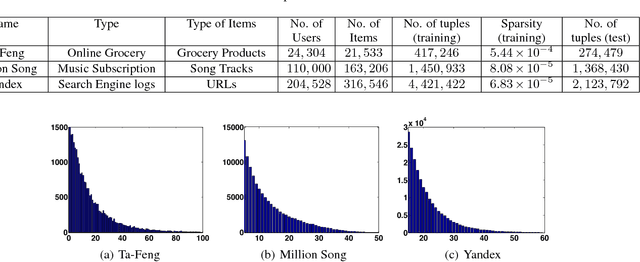
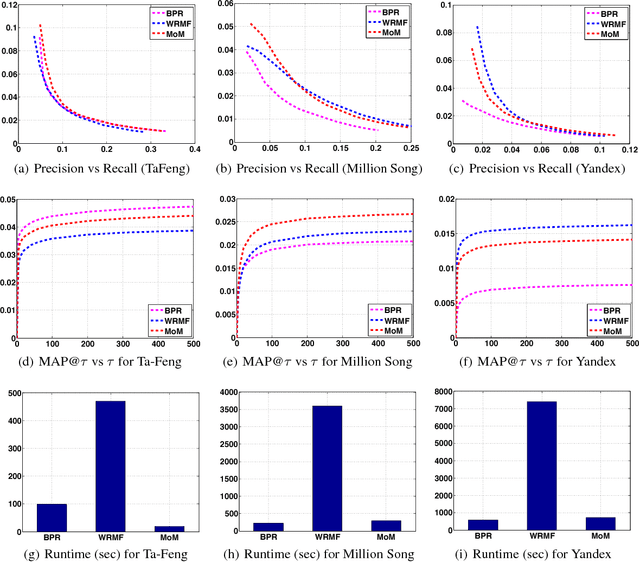
Building recommendation algorithms is one of the most challenging tasks in Machine Learning. Although most of the recommendation systems are built on explicit feedback available from the users in terms of rating or text, a majority of the applications do not receive such feedback. Here we consider the recommendation task where the only available data is the records of user-item interaction over web applications over time, in terms of subscription or purchase of items; this is known as implicit feedback recommendation. There is usually a massive amount of such user-item interaction available for any web applications. Algorithms like PLSI or Matrix Factorization runs several iterations through the dataset, and may prove very expensive for large datasets. Here we propose a recommendation algorithm based on Method of Moment, which involves factorization of second and third order moments of the dataset. Our algorithm can be proven to be globally convergent using PAC learning theory. Further, we show how to extract the parameters using only three passes through the entire dataset. This results in a highly scalable algorithm that scales up to million of users even on a machine with a single-core processor and 8 GB RAM and produces competitive performance in comparison with existing algorithms.