 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Learning with Provable Guarantee
Paper and Code
Nov 01, 2016

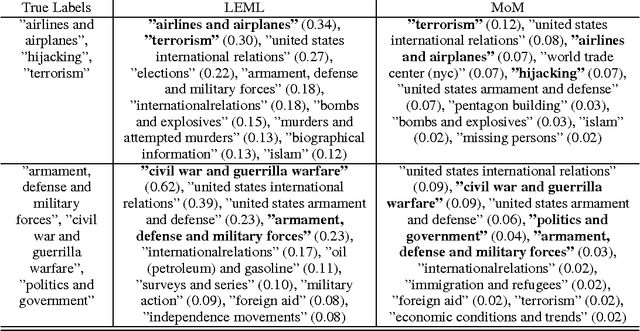
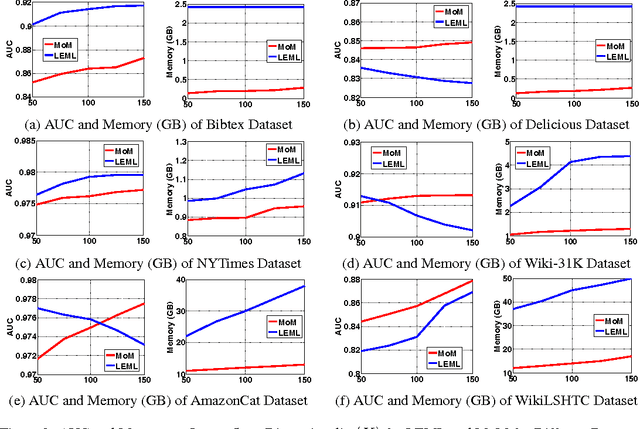
Here we study the problem of learning labels for large text corpora where each text can be assigned a variable number of labels. The problem might seem trivial when the label dimensionality is small and can be easily solved using a series of one-vs-all classifiers. However, as the label dimensionality increases to several thousand, the parameter space becomes extremely large, and it is no longer possible to use the one-vs-all technique. Here we propose a model based on the factorization of higher order moments of the words in the corpora, as well as the cross moment between the labels and the words for multi-label prediction. Our model provides guaranteed convergence bounds on the estimated parameters. Further, our model takes only three passes through the training dataset to extract the parameters, resulting in a highly scalable algorithm that can train on GB's of data consisting of millions of documents with hundreds of thousands of labels using a nominal resource of a single processor with 16GB RAM. Our model achieves 10x-15x order of speed-up on large-scale datasets while producing competitive performance in comparison with existing benchmark algorithms.