 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Vision-Language Models Distinguish between the Actual and Apparent Features of Illusions?
Jun 06, 2025Humans are susceptible to optical illusions, which serve as valuable tools for investigating sensory and cognitive processes. Inspired by human vision studies, research has begun exploring whether machines, such as large vision language models (LVLMs), exhibit similar susceptibilities to visual illusions. However, studies often have used non-abstract images and have not distinguished actual and apparent features, leading to ambiguous assessments of machine cognition. To address these limitations, we introduce a visual question answering (VQA) dataset, categorized into genuine and fake illusions, along with corresponding control images. Genuine illusions present discrepancies between actual and apparent features, whereas fake illusions have the same actual and apparent features even though they look illusory due to the similar geometric configuration. We evaluate the performance of LVLMs for genuine and fake illusion VQA tasks and investigate whether the models discern actual and apparent features. Our findings indicate that although LVLMs may appear to recognize illusions by correctly answering questions about both feature types, they predict the same answers for both Genuine Illusion and Fake Illusion VQA questions. This suggests that their responses might be based on prior knowledge of illusions rather than genuine visual understanding. The dataset is available at https://github.com/ynklab/FILM
Brain-mediated Transfer Learning of Convolutional Neural Networks
May 24, 2019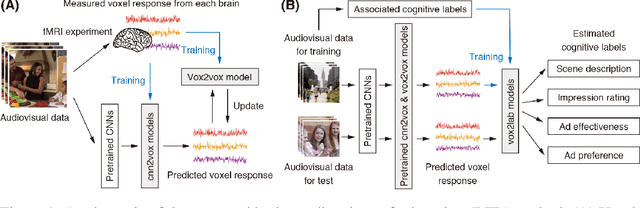

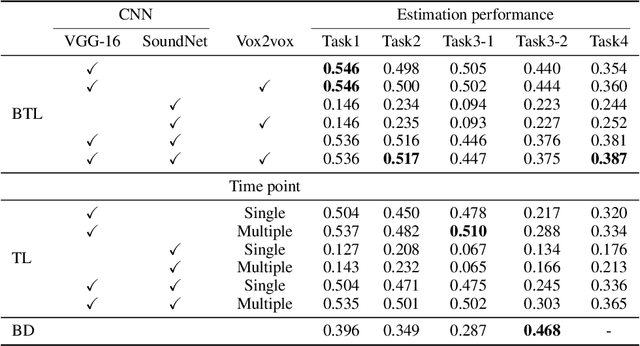
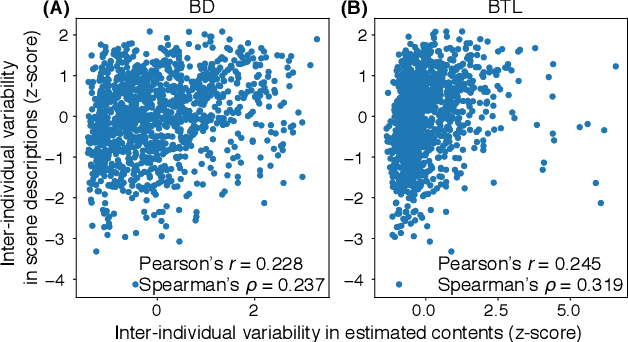
Human flexible cognition and behavior indicate that the human brain can effectively use its internal feature representations acquired through limited experiences for new experiences in different domains. This function is analogous to transfer learning (TL) in the field of machine learning. TL uses a well-trained feature space in a specific task domain to improve performance in new tasks with insufficient training data. TL with rich feature representations, such as features of convolutional neural networks (CNNs), shows high generalization ability across different task domains. However, such TL is still insufficient in making machine learning attain generalization ability comparable to that of the human brain. To address this, we introduce a method for TL mediated by human brains to improve the performance of TL especially on pattern recognition in which human high-level cognition is considered. Our method transforms feature representations of audiovisual inputs in CNNs into those in activation patterns of individual brains via their association learned ahead using measured brain responses. Then, to estimate labels reflecting human cognition and behavior induced by the audiovisual inputs, the transformed representations are used for TL. We demonstrate that our brain-mediated TL (BTL) shows higher performance in the label estimation than the standard TL. In addition, we illustrate that the estimations mediated by different brains vary from brain to brain, and the variability reflects the individual variability in perception. Thus, our BTL provides a framework to improve the generalization ability of machine-learning feature representations and enable machine learning to estimate human-like cognition and behavior, including individual variability.
Describing Semantic Representations of Brain Activity Evoked by Visual Stimuli
Jan 19, 2018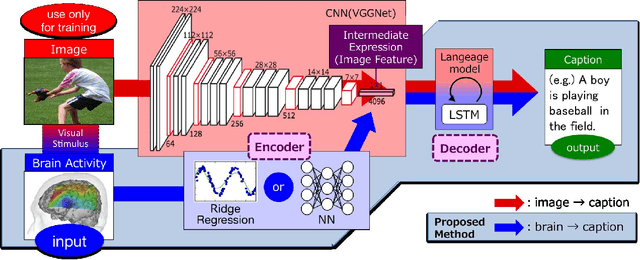
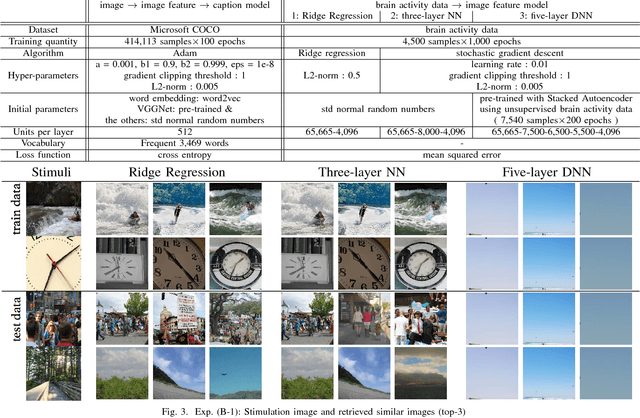
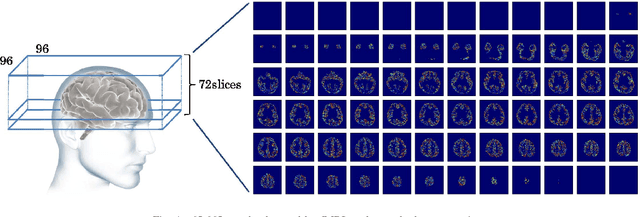

Quantitative modeling of human brain activity based on language representations has been actively studied in systems neuroscience. However, previous studies examined word-level representation, and little is known about whether we could recover structured sentences from brain activity. This study attempts to generate natural language descriptions of semantic contents from human brain activity evoked by visual stimuli. To effectively use a small amount of available brain activity data, our proposed method employs a pre-trained image-captioning network model using a deep learning framework. To apply brain activity to the image-captioning network, we train regression models that learn the relationship between brain activity and deep-layer image features. The results demonstrate that the proposed model can decode brain activity and generate descriptions using natural language sentences. We also conducted several experiments with data from different subsets of brain regions known to process visual stimuli. The results suggest that semantic information for sentence generations is widespread across the entire cortex.