 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture Matters for Multi-Agent Security
Apr 25, 2026Multi-agent systems (MAS), composed of networks of two or more autonomous AI agents, have become increasingly popular in production deployments, yet introduce security risks that do not arise in single-agent settings. Even if individual agents exhibit robust security, architectural decisions governing their coordination can create attack surfaces that have not been systematically characterized. In this work, we present an empirical study of how MAS design decisions shape the tradeoff between task performance and attack resistance. Across three agentic environments (browser, desktop, and code) and 13 architectural configurations, we use stagewise evaluations that distinguish planning refusal, execution-stage interception, partial harmful execution, and successful attack completion to study three key design choices: (i) agent roles, which determine how authority and responsibility are allocated; (ii) communication topology, which shapes how and when agents interact; and (iii) memory, which determines the context and state visibility accessible to each agent. We find that multi-agent architectures are more vulnerable than standalone agents in the majority of configurations, with attack success rates varying by up to 3.8x at comparable or higher benign accuracy, and that no single design is universally safer. These results motivate the development of further evaluations that move beyond the security properties of a single agent.
From Soft Classifiers to Hard Decisions: How fair can we be?
Oct 03, 2018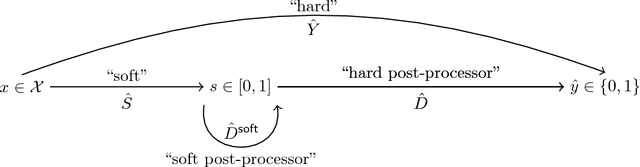
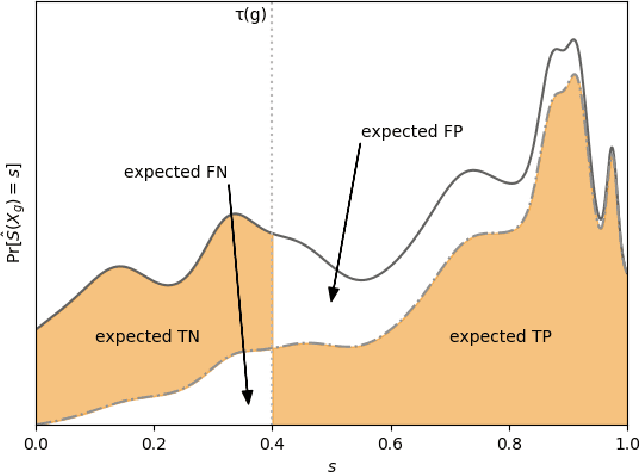
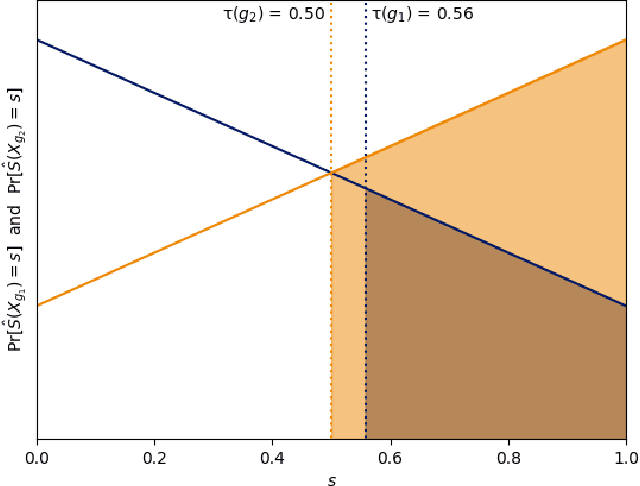
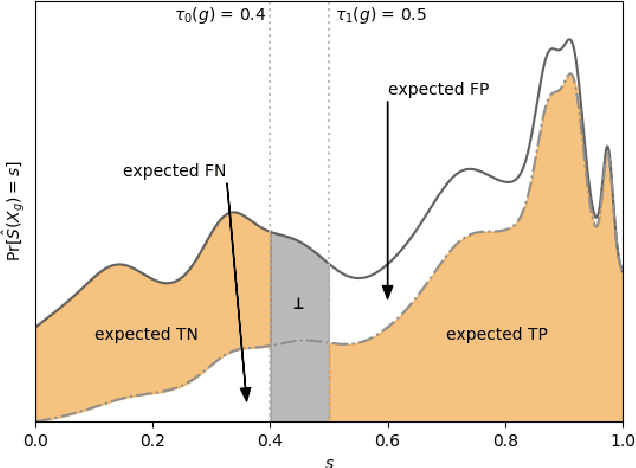
A popular methodology for building binary decision-making classifiers in the presence of imperfect information is to first construct a non-binary "scoring" classifier that is calibrated over all protected groups, and then to post-process this score to obtain a binary decision. We study the feasibility of achieving various fairness properties by post-processing calibrated scores, and then show that deferring post-processors allow for more fairness conditions to hold on the final decision. Specifically, we show: 1. There does not exist a general way to post-process a calibrated classifier to equalize protected groups' positive or negative predictive value (PPV or NPV). For certain "nice" calibrated classifiers, either PPV or NPV can be equalized when the post-processor uses different thresholds across protected groups, though there exist distributions of calibrated scores for which the two measures cannot be both equalized. When the post-processing consists of a single global threshold across all groups, natural fairness properties, such as equalizing PPV in a nontrivial way, do not hold even for "nice" classifiers. 2. When the post-processing is allowed to `defer' on some decisions (that is, to avoid making a decision by handing off some examples to a separate process), then for the non-deferred decisions, the resulting classifier can be made to equalize PPV, NPV, false positive rate (FPR) and false negative rate (FNR) across the protected groups. This suggests a way to partially evade the impossibility results of Chouldechova and Kleinberg et al., which preclude equalizing all of these measures simultaneously. We also present different deferring strategies and show how they affect the fairness properties of the overall system. We evaluate our post-processing techniques using the COMPAS data set from 2016.