 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Browsing: Controllable Diversity for Image Generation
Jun 22, 2026Modern text-to-image models excel in visual fidelity and prompt adherence. However, this strict adherence comes at the cost of diversity: generated samples tend to collapse into a single visual interpretation. Existing methods to improve diversity produce outputs driven by incidental variations rather than meaningful design choices. This motivates a new variant of the diversity task where structure is enforced on the generated samples. We introduce a method for controlled diversity that enables Semantic Browsing, where users can navigate structured image galleries and experience creative exploration through a systematic traversal of meaningful, interpretable axes of variation. Achieving this level of semantic control requires a deep understanding of the scene. We exploit the fact that recent text-to-image models are trained on elaborated captions, effectively decoupling semantic decision-making from pixel generation. This enables a paradigm shift: instead of relying on stochastic variation within the text-to-image model, we induce diversity directly at the text level. By leveraging rich textual representations, we allow a Vision Language Model (VLM) to operate on the full scene context. To overcome the generic outputs typical of standard VLMs, we employ an agentic workflow that explicitly enforces structured variation attuned to the original prompt. We demonstrate that our method produces diverse and navigable design spaces where every variation corresponds to a specific, user-understandable semantic decision.
SAEdit: Token-level control for continuous image editing via Sparse AutoEncoder
Oct 06, 2025Large-scale text-to-image diffusion models have become the backbone of modern image editing, yet text prompts alone do not offer adequate control over the editing process. Two properties are especially desirable: disentanglement, where changing one attribute does not unintentionally alter others, and continuous control, where the strength of an edit can be smoothly adjusted. We introduce a method for disentangled and continuous editing through token-level manipulation of text embeddings. The edits are applied by manipulating the embeddings along carefully chosen directions, which control the strength of the target attribute. To identify such directions, we employ a Sparse Autoencoder (SAE), whose sparse latent space exposes semantically isolated dimensions. Our method operates directly on text embeddings without modifying the diffusion process, making it model agnostic and broadly applicable to various image synthesis backbones. Experiments show that it enables intuitive and efficient manipulations with continuous control across diverse attributes and domains.
IP-Composer: Semantic Composition of Visual Concepts
Feb 19, 2025
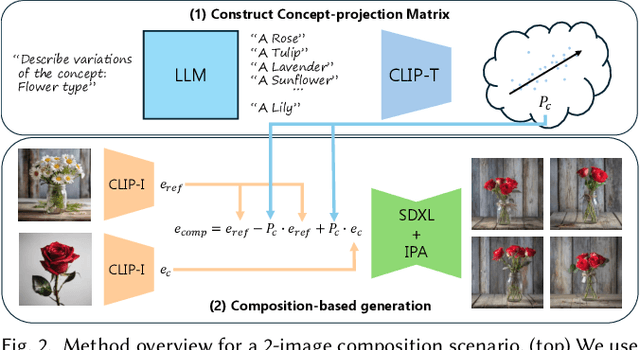


Content creators often draw inspiration from multiple visual sources, combining distinct elements to craft new compositions. Modern computational approaches now aim to emulate this fundamental creative process. Although recent diffusion models excel at text-guided compositional synthesis, text as a medium often lacks precise control over visual details. Image-based composition approaches can capture more nuanced features, but existing methods are typically limited in the range of concepts they can capture, and require expensive training procedures or specialized data. We present IP-Composer, a novel training-free approach for compositional image generation that leverages multiple image references simultaneously, while using natural language to describe the concept to be extracted from each image. Our method builds on IP-Adapter, which synthesizes novel images conditioned on an input image's CLIP embedding. We extend this approach to multiple visual inputs by crafting composite embeddings, stitched from the projections of multiple input images onto concept-specific CLIP-subspaces identified through text. Through comprehensive evaluation, we show that our approach enables more precise control over a larger range of visual concept compositions.