 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Amateur to Master: Infusing Knowledge into LLMs via Automated Curriculum Learning
Oct 30, 2025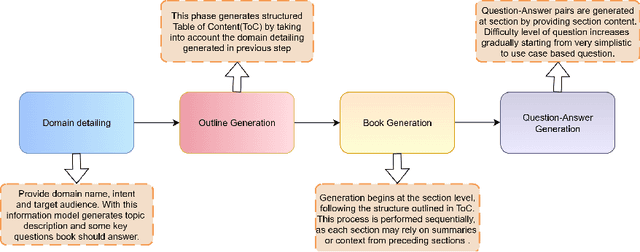
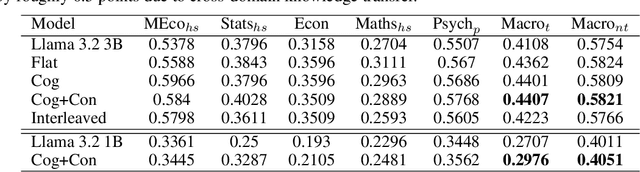
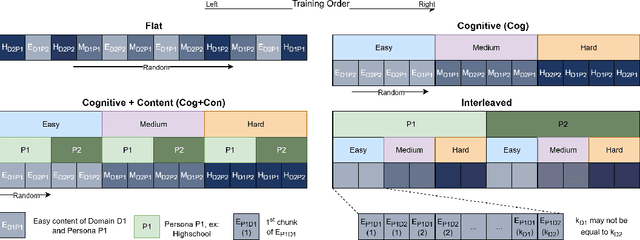
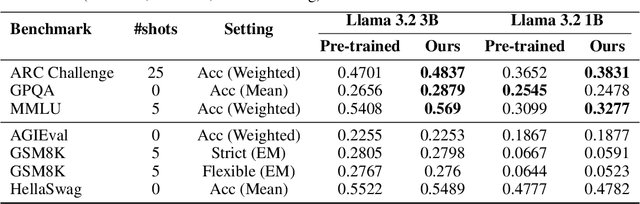
Large Language Models (LLMs) excel at general tasks but underperform in specialized domains like economics and psychology, which require deep, principled understanding. To address this, we introduce ACER (Automated Curriculum-Enhanced Regimen) that transforms generalist models into domain experts without sacrificing their broad capabilities. ACER first synthesizes a comprehensive, textbook-style curriculum by generating a table of contents for a subject and then creating question-answer (QA) pairs guided by Bloom's taxonomy. This ensures systematic topic coverage and progressively increasing difficulty. The resulting synthetic corpus is used for continual pretraining with an interleaved curriculum schedule, aligning learning across both content and cognitive dimensions. Experiments with Llama 3.2 (1B and 3B) show significant gains in specialized MMLU subsets. In challenging domains like microeconomics, where baselines struggle, ACER boosts accuracy by 5 percentage points. Across all target domains, we observe a consistent macro-average improvement of 3 percentage points. Notably, ACER not only prevents catastrophic forgetting but also facilitates positive cross-domain knowledge transfer, improving performance on non-target domains by 0.7 points. Beyond MMLU, ACER enhances performance on knowledge-intensive benchmarks like ARC and GPQA by over 2 absolute points, while maintaining stable performance on general reasoning tasks. Our results demonstrate that ACER offers a scalable and effective recipe for closing critical domain gaps in LLMs.
Hierarchical Repository-Level Code Summarization for Business Applications Using Local LLMs
Jan 14, 2025



In large-scale software development, understanding the functionality and intent behind complex codebases is critical for effective development and maintenance. While code summarization has been widely studied, existing methods primarily focus on smaller code units, such as functions, and struggle with larger code artifacts like files and packages. Additionally, current summarization models tend to emphasize low-level implementation details, often overlooking the domain and business context that are crucial for real-world applications. This paper proposes a two-step hierarchical approach for repository-level code summarization, tailored to business applications. First, smaller code units such as functions and variables are identified using syntax analysis and summarized with local LLMs. These summaries are then aggregated to generate higher-level file and package summaries. To ensure the summaries are grounded in business context, we design custom prompts that capture the intended purpose of code artifacts based on the domain and problem context of the business application. We evaluate our approach on a business support system (BSS) for the telecommunications domain, showing that syntax analysis-based hierarchical summarization improves coverage, while business-context grounding enhances the relevance of the generated summaries.
Retrofitting Light-weight Language Models for Emotions using Supervised Contrastive Learning
Oct 29, 2023



We present a novel retrofitting method to induce emotion aspects into pre-trained language models (PLMs) such as BERT and RoBERTa. Our method updates pre-trained network weights using contrastive learning so that the text fragments exhibiting similar emotions are encoded nearby in the representation space, and the fragments with different emotion content are pushed apart. While doing so, it also ensures that the linguistic knowledge already present in PLMs is not inadvertently perturbed. The language models retrofitted by our method, i.e., BERTEmo and RoBERTaEmo, produce emotion-aware text representations, as evaluated through different clustering and retrieval metrics. For the downstream tasks on sentiment analysis and sarcasm detection, they perform better than their pre-trained counterparts (about 1% improvement in F1-score) and other existing approaches. Additionally, a more significant boost in performance is observed for the retrofitted models over pre-trained ones in few-shot learning setting.