 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextConvoNet:A Convolutional Neural Network based Architecture for Text Classification
Mar 10, 2022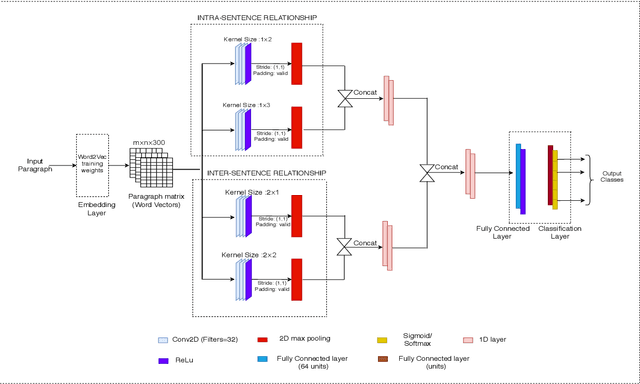
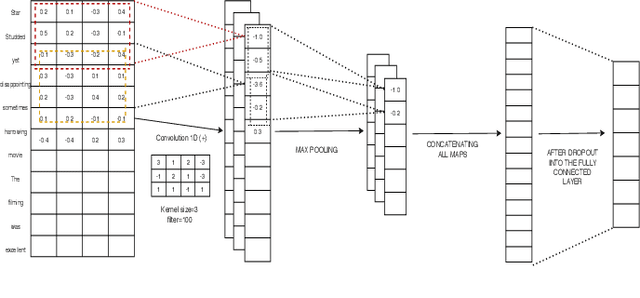
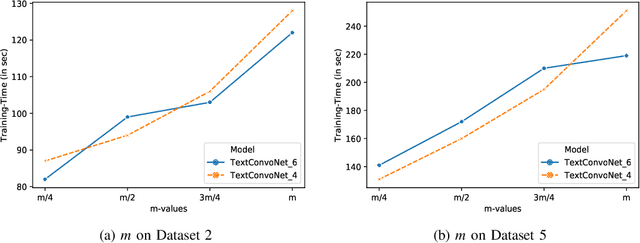
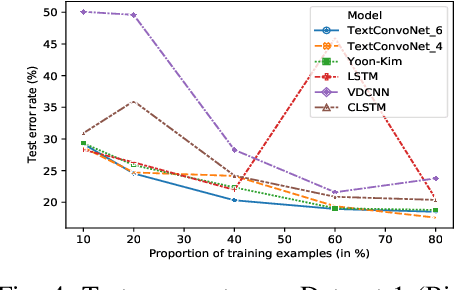
In recent years, deep learning-based models have significantly improved the Natural Language Processing (NLP) tasks. Specifically, the Convolutional Neural Network (CNN), initially used for computer vision, has shown remarkable performance for text data in various NLP problems. Most of the existing CNN-based models use 1-dimensional convolving filters n-gram detectors), where each filter specialises in extracting n-grams features of a particular input word embedding. The input word embeddings, also called sentence matrix, is treated as a matrix where each row is a word vector. Thus, it allows the model to apply one-dimensional convolution and only extract n-gram based features from a sentence matrix. These features can be termed as intra-sentence n-gram features. To the extent of our knowledge, all the existing CNN models are based on the aforementioned concept. In this paper, we present a CNN-based architecture TextConvoNet that not only extracts the intra-sentence n-gram features but also captures the inter-sentence n-gram features in input text data. It uses an alternative approach for input matrix representation and applies a two-dimensional multi-scale convolutional operation on the input. To evaluate the performance of TextConvoNet, we perform an experimental study on five text classification datasets. The results are evaluated by using various performance metrics. The experimental results show that the presented TextConvoNet outperforms state-of-the-art machine learning and deep learning models for text classification purposes.
DiPD: Disruptive event Prediction Dataset from Twitter
Nov 25, 2021
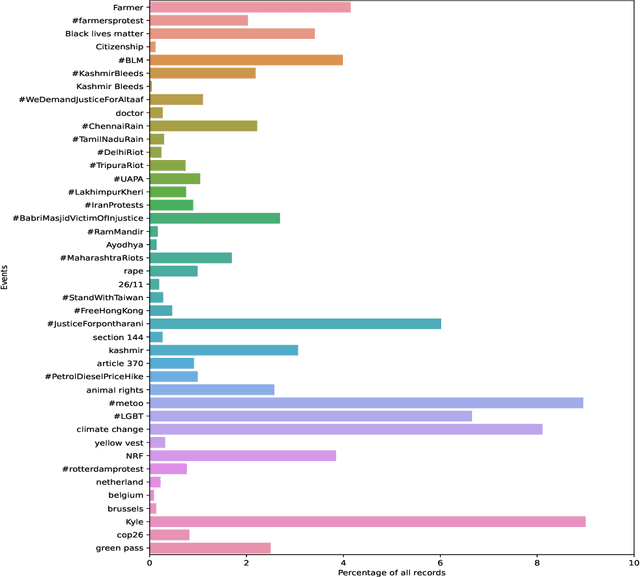

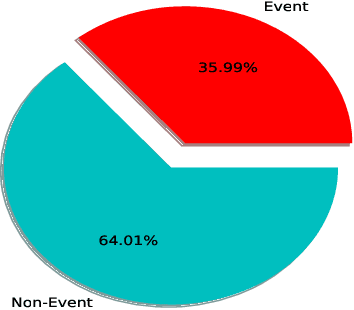
Riots and protests, if gone out of control, can cause havoc in a country. We have seen examples of this, such as the BLM movement, climate strikes, CAA Movement, and many more, which caused disruption to a large extent. Our motive behind creating this dataset was to use it to develop machine learning systems that can give its users insight into the trending events going on and alert them about the events that could lead to disruption in the nation. If any event starts going out of control, it can be handled and mitigated by monitoring it before the matter escalates. This dataset collects tweets of past or ongoing events known to have caused disruption and labels these tweets as 1. We also collect tweets that are considered non-eventful and label them as 0 so that they can also be used to train a classification system. The dataset contains 94855 records of unique events and 168706 records of unique non-events, thus giving the total dataset 263561 records. We extract multiple features from the tweets, such as the user's follower count and the user's location, to understand the impact and reach of the tweets. This dataset might be useful in various event related machine learning problems such as event classification, event recognition, and so on.