 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNOiC: Soft Labeling and Noisy Mixup based Open Intent Classification Model
Oct 11, 2023This paper presents a Soft Labeling and Noisy Mixup-based open intent classification model (SNOiC). Most of the previous works have used threshold-based methods to identify open intents, which are prone to overfitting and may produce biased predictions. Additionally, the need for more available data for an open intent class presents another limitation for these existing models. SNOiC combines Soft Labeling and Noisy Mixup strategies to reduce the biasing and generate pseudo-data for open intent class. The experimental results on four benchmark datasets show that the SNOiC model achieves a minimum and maximum performance of 68.72\% and 94.71\%, respectively, in identifying open intents. Moreover, compared to state-of-the-art models, the SNOiC model improves the performance of identifying open intents by 0.93\% (minimum) and 12.76\% (maximum). The model's efficacy is further established by analyzing various parameters used in the proposed model. An ablation study is also conducted, which involves creating three model variants to validate the effectiveness of the SNOiC model.
DiPD: Disruptive event Prediction Dataset from Twitter
Nov 25, 2021
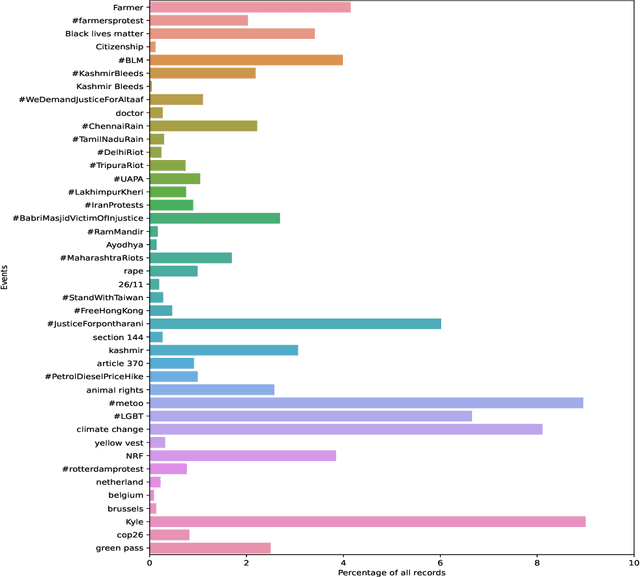

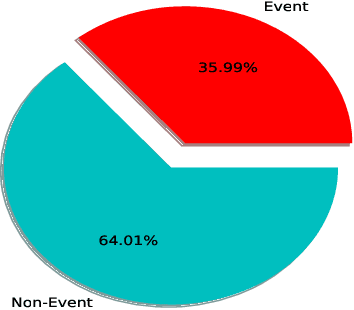
Riots and protests, if gone out of control, can cause havoc in a country. We have seen examples of this, such as the BLM movement, climate strikes, CAA Movement, and many more, which caused disruption to a large extent. Our motive behind creating this dataset was to use it to develop machine learning systems that can give its users insight into the trending events going on and alert them about the events that could lead to disruption in the nation. If any event starts going out of control, it can be handled and mitigated by monitoring it before the matter escalates. This dataset collects tweets of past or ongoing events known to have caused disruption and labels these tweets as 1. We also collect tweets that are considered non-eventful and label them as 0 so that they can also be used to train a classification system. The dataset contains 94855 records of unique events and 168706 records of unique non-events, thus giving the total dataset 263561 records. We extract multiple features from the tweets, such as the user's follower count and the user's location, to understand the impact and reach of the tweets. This dataset might be useful in various event related machine learning problems such as event classification, event recognition, and so on.