 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastCLIPStyler: Towards fast text-based image style transfer using style representation
Oct 07, 2022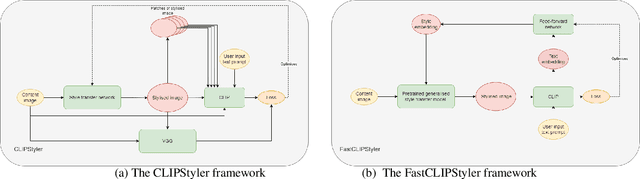

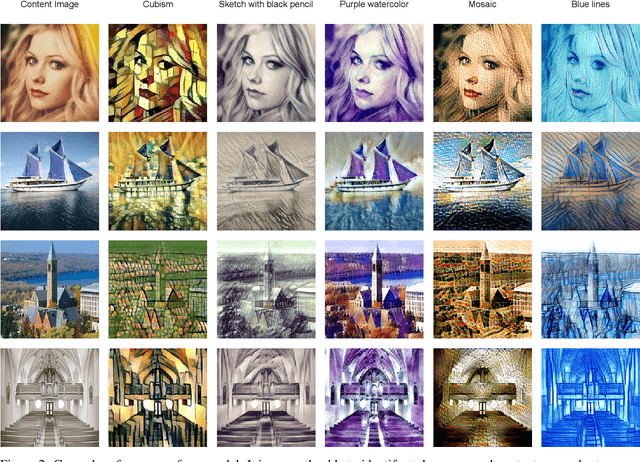

Artistic style transfer is usually performed between two images, a style image and a content image. Recently, a model named CLIPStyler demonstrated that a natural language description of style could replace the necessity of a reference style image. They achieved this by taking advantage of the CLIP model, which can compute the similarity between a text phrase and an image. In this work, we demonstrate how combining CLIPStyler with a pre-trained, purely vision-based style transfer model can significantly reduce the inference time of CLIPStyler. We call this model FastCLIPStyler. We do a qualitative exploration of the stylised images from both models and argue that our model also has merits in terms of the visual aesthetics of the generated images. Finally, we also point out how FastCLIPStyler can be used to further extend this line of research to create a generalised text-to-style model that does not require optimisation at inference time, which both CLIPStyler and FastCLIPStyler do currently.
Amortized Variational Inference: Towards the Mathematical Foundation and Review
Sep 22, 2022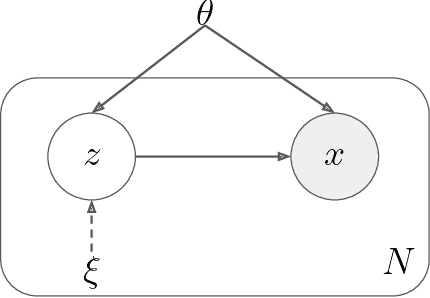
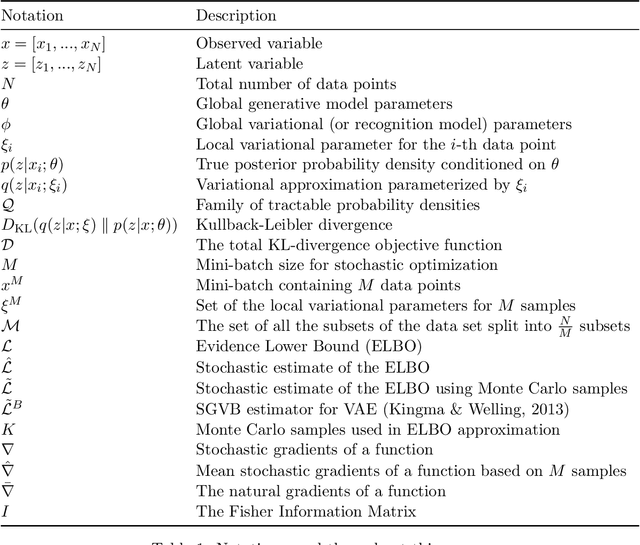
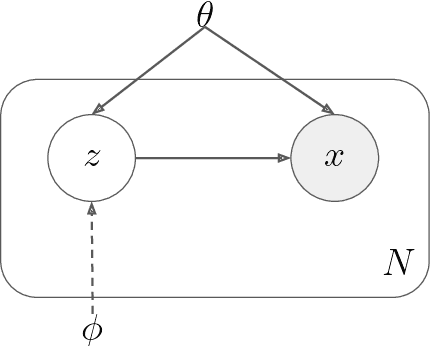
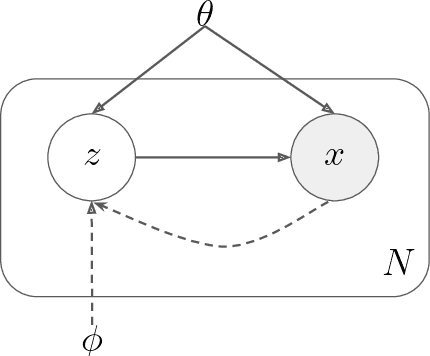
The core principle of Variational Inference (VI) is to convert the statistical inference problem of computing complex posterior probability densities into a tractable optimization problem. This property enables VI to be faster than several sampling-based techniques. However, the traditional VI algorithm is not scalable to large data sets and is unable to readily infer out-of-bounds data points without re-running the optimization process. Recent developments in the field, like stochastic-, black box- and amortized-VI, have helped address these issues. Generative modeling tasks nowadays widely make use of amortized VI for its efficiency and scalability, as it utilizes a parameterized function to learn the approximate posterior density parameters. With this paper, we review the mathematical foundations of various VI techniques to form the basis for understanding amortized VI. Additionally, we provide an overview of the recent trends that address several issues of amortized VI, such as the amortization gap, generalization issues, inconsistent representation learning, and posterior collapse. Finally, we analyze alternate divergence measures that improve VI optimization.
LOTR: Face Landmark Localization Using Localization Transformer
Sep 21, 2021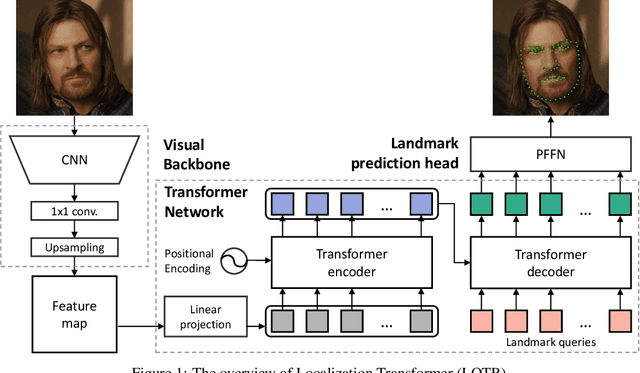
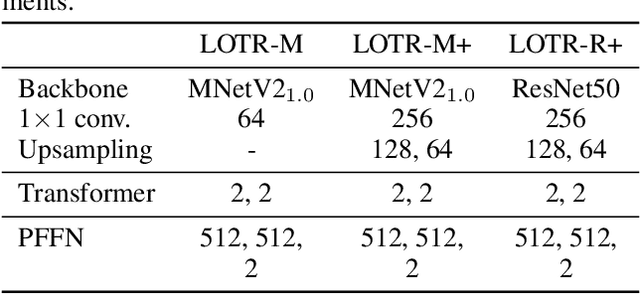
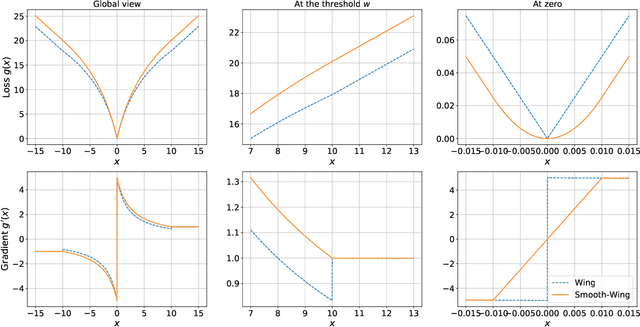
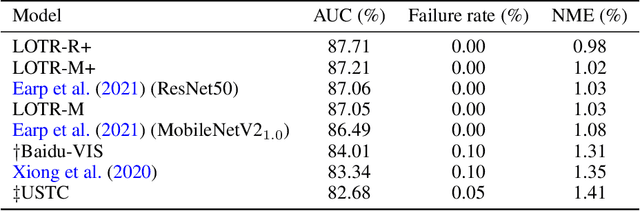
This paper presents a novel Transformer-based facial landmark localization network named Localization Transformer (LOTR). The proposed framework is a direct coordinate regression approach leveraging a Transformer network to better utilize the spatial information in the feature map. An LOTR model consists of three main modules: 1) a visual backbone that converts an input image into a feature map, 2) a Transformer module that improves the feature representation from the visual backbone, and 3) a landmark prediction head that directly predicts the landmark coordinates from the Transformer's representation. Given cropped-and-aligned face images, the proposed LOTR can be trained end-to-end without requiring any post-processing steps. This paper also introduces the smooth-Wing loss function, which addresses the gradient discontinuity of the Wing loss, leading to better convergence than standard loss functions such as L1, L2, and Wing loss. Experimental results on the JD landmark dataset provided by the First Grand Challenge of 106-Point Facial Landmark Localization indicate the superiority of LOTR over the existing methods on the leaderboard and two recent heatmap-based approaches.
Sub-pixel face landmarks using heatmaps and a bag of tricks
Mar 08, 2021
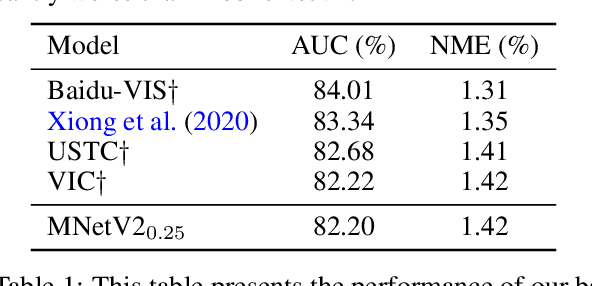
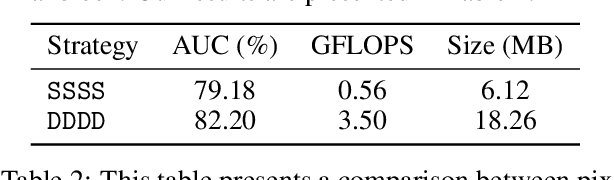
Accurate face landmark localization is an essential part of face recognition, reconstruction and morphing. To accurately localize face landmarks, we present our heatmap regression approach. Each model consists of a MobileNetV2 backbone followed by several upscaling layers, with different tricks to optimize both performance and inference cost. We use five na\"ive face landmarks from a publicly available face detector to position and align the face instead of using the bounding box like traditional methods. Moreover, we show by adding random rotation, displacement and scaling -- after alignment -- that the model is more sensitive to the face position than orientation. We also show that it is possible to reduce the upscaling complexity by using a mixture of deconvolution and pixel-shuffle layers without impeding localization performance. We present our state-of-the-art face landmark localization model (ranking second on The 2nd Grand Challenge of 106-Point Facial Landmark Localization validation set). Finally, we test the effect on face recognition using these landmarks, using a publicly available model and benchmarks.