 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a face mask detection pipeline for mask-wearing monitoring in the era of the COVID-19 pandemic: A modular approach
Dec 30, 2021



During the SARS-Cov-2 pandemic, mask-wearing became an effective tool to prevent spreading and contracting the virus. The ability to monitor the mask-wearing rate in the population would be useful for determining public health strategies against the virus. However, artificial intelligence technologies for detecting face masks have not been deployed at a large scale in real-life to measure the mask-wearing rate in public. In this paper, we present a two-step face mask detection approach consisting of two separate modules: 1) face detection and alignment and 2) face mask classification. This approach allowed us to experiment with different combinations of face detection and face mask classification modules. More specifically, we experimented with PyramidKey and RetinaFace as face detectors while maintaining a lightweight backbone for the face mask classification module. Moreover, we also provide a relabeled annotation of the test set of the AIZOO dataset, where we rectified the incorrect labels for some face images. The evaluation results on the AIZOO and Moxa 3K datasets showed that the proposed face mask detection pipeline surpassed the state-of-the-art methods. The proposed pipeline also yielded a higher mAP on the relabeled test set of the AIZOO dataset than the original test set. Since we trained the proposed model using in-the-wild face images, we can successfully deploy our model to monitor the mask-wearing rate using public CCTV images.
LOTR: Face Landmark Localization Using Localization Transformer
Sep 21, 2021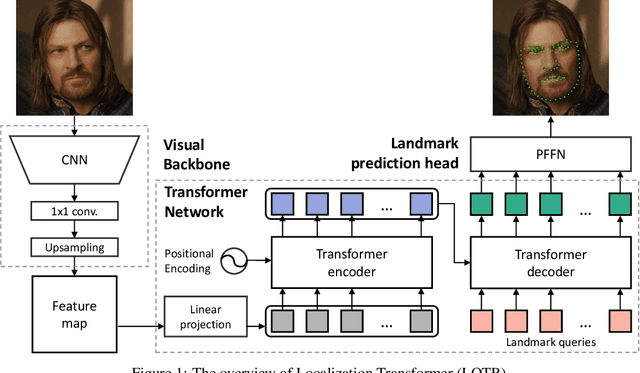
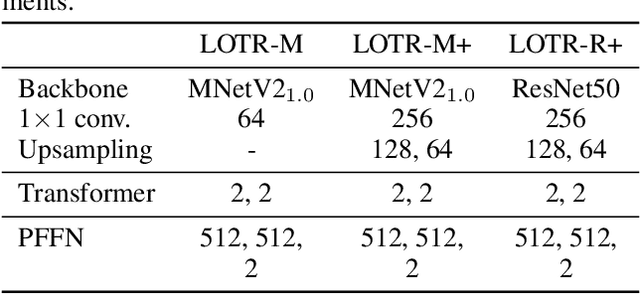
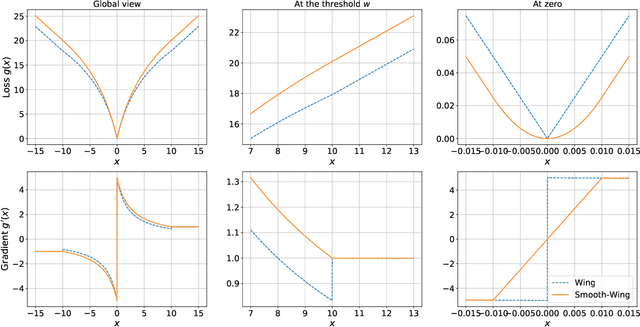
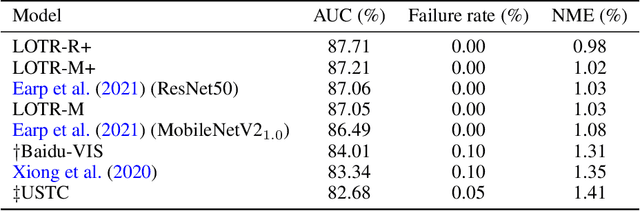
This paper presents a novel Transformer-based facial landmark localization network named Localization Transformer (LOTR). The proposed framework is a direct coordinate regression approach leveraging a Transformer network to better utilize the spatial information in the feature map. An LOTR model consists of three main modules: 1) a visual backbone that converts an input image into a feature map, 2) a Transformer module that improves the feature representation from the visual backbone, and 3) a landmark prediction head that directly predicts the landmark coordinates from the Transformer's representation. Given cropped-and-aligned face images, the proposed LOTR can be trained end-to-end without requiring any post-processing steps. This paper also introduces the smooth-Wing loss function, which addresses the gradient discontinuity of the Wing loss, leading to better convergence than standard loss functions such as L1, L2, and Wing loss. Experimental results on the JD landmark dataset provided by the First Grand Challenge of 106-Point Facial Landmark Localization indicate the superiority of LOTR over the existing methods on the leaderboard and two recent heatmap-based approaches.
An Introduction to Variational Inference
Aug 30, 2021
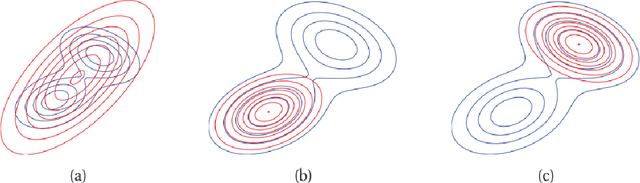
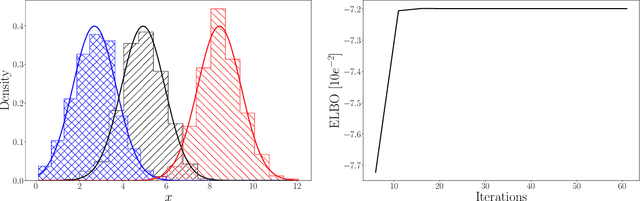
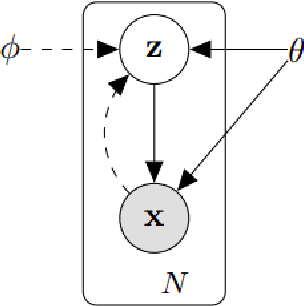
Approximating complex probability densities is a core problem in modern statistics. In this paper, we introduce the concept of Variational Inference (VI), a popular method in machine learning that uses optimization techniques to estimate complex probability densities. This property allows VI to converge faster than classical methods, such as, Markov Chain Monte Carlo sampling. Conceptually, VI works by choosing a family of probability density functions and then finding the one closest to the actual probability density -- often using the Kullback-Leibler (KL) divergence as the optimization metric. We introduce the Evidence Lower Bound to tractably compute the approximated probability density and we review the ideas behind mean-field variational inference. Finally, we discuss the applications of VI to variational auto-encoders (VAE) and VAE-Generative Adversarial Network (VAE-GAN). With this paper, we aim to explain the concept of VI and assist in future research with this approach.
Sub-pixel face landmarks using heatmaps and a bag of tricks
Mar 08, 2021
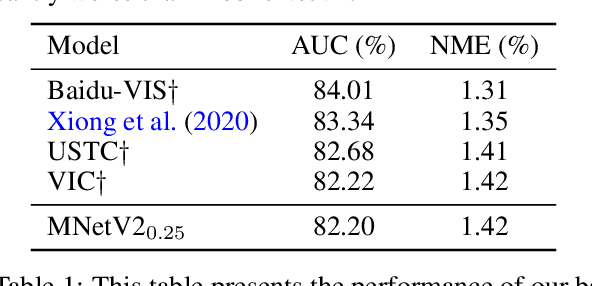
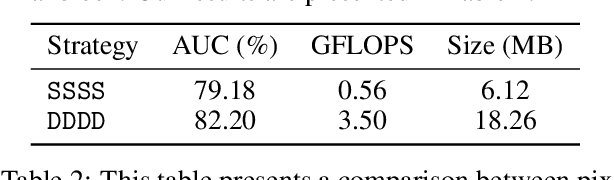
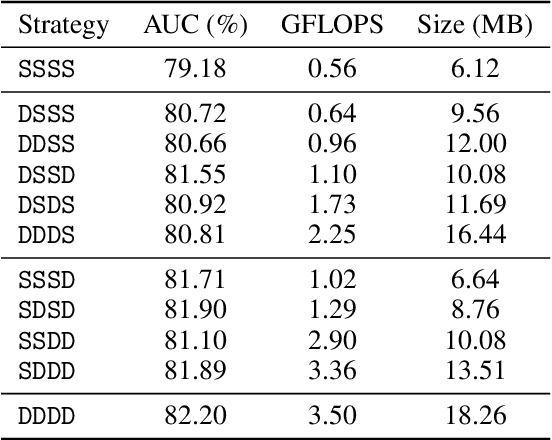
Accurate face landmark localization is an essential part of face recognition, reconstruction and morphing. To accurately localize face landmarks, we present our heatmap regression approach. Each model consists of a MobileNetV2 backbone followed by several upscaling layers, with different tricks to optimize both performance and inference cost. We use five na\"ive face landmarks from a publicly available face detector to position and align the face instead of using the bounding box like traditional methods. Moreover, we show by adding random rotation, displacement and scaling -- after alignment -- that the model is more sensitive to the face position than orientation. We also show that it is possible to reduce the upscaling complexity by using a mixture of deconvolution and pixel-shuffle layers without impeding localization performance. We present our state-of-the-art face landmark localization model (ranking second on The 2nd Grand Challenge of 106-Point Facial Landmark Localization validation set). Finally, we test the effect on face recognition using these landmarks, using a publicly available model and benchmarks.
Face Detection with Feature Pyramids and Landmarks
Dec 18, 2019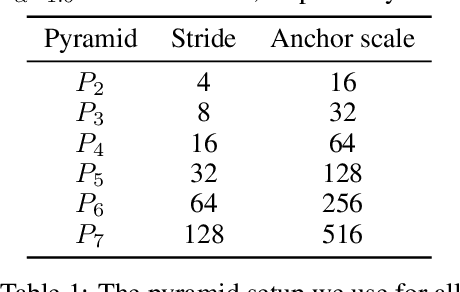
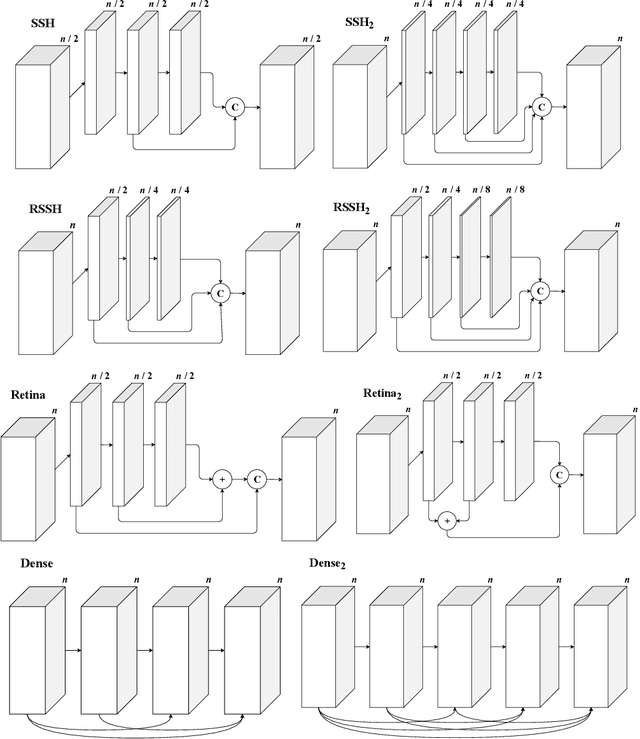

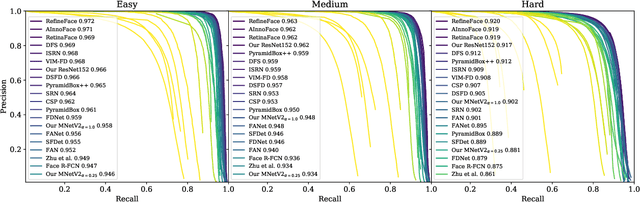
Accurate face detection and facial landmark localization are crucial to any face recognition system. We present a series of three single-stage RCNNs with different sized backbones (MobileNetV2-25, MobileNetV2-100, and ResNet101) and a six-layer feature pyramid trained exclusively on the WIDER FACE dataset. We compare the face detection and landmark accuracies using eight context module architectures, four proposed by previous research and four modified versions. We find no evidence that any of the proposed architectures significantly overperform and postulate that the random initialization of the additional layers is at least of equal importance. To show this we present a model that achieves near state-of-the-art performance on WIDER FACE and also provides high accuracy landmarks with a simple context module. We also present results using MobileNetV2 backbones, which achieve over 90% average precision on the WIDER FACE hard validation set while being able to run in real-time. By comparing to other authors, we show that our models exceed the state-of-the-art for similar-sized RCNNs and match the performance of much heavier networks.