 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025



We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
Unrestricted Black-box Adversarial Attack Using GAN with Limited Queries
Aug 24, 2022
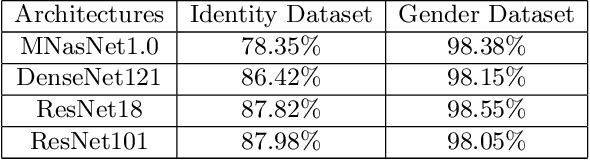
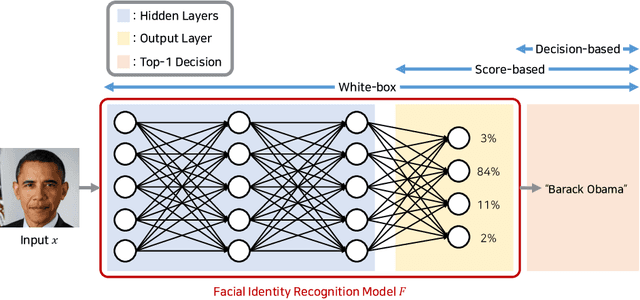
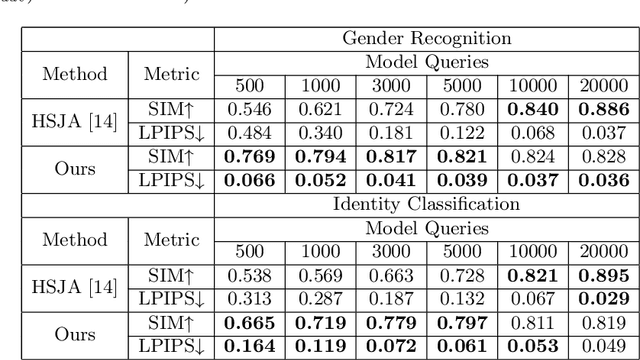
Adversarial examples are inputs intentionally generated for fooling a deep neural network. Recent studies have proposed unrestricted adversarial attacks that are not norm-constrained. However, the previous unrestricted attack methods still have limitations to fool real-world applications in a black-box setting. In this paper, we present a novel method for generating unrestricted adversarial examples using GAN where an attacker can only access the top-1 final decision of a classification model. Our method, Latent-HSJA, efficiently leverages the advantages of a decision-based attack in the latent space and successfully manipulates the latent vectors for fooling the classification model. With extensive experiments, we demonstrate that our proposed method is efficient in evaluating the robustness of classification models with limited queries in a black-box setting. First, we demonstrate that our targeted attack method is query-efficient to produce unrestricted adversarial examples for a facial identity recognition model that contains 307 identities. Then, we demonstrate that the proposed method can also successfully attack a real-world celebrity recognition service.
Detecting Audio Adversarial Examples with Logit Noising
Dec 13, 2021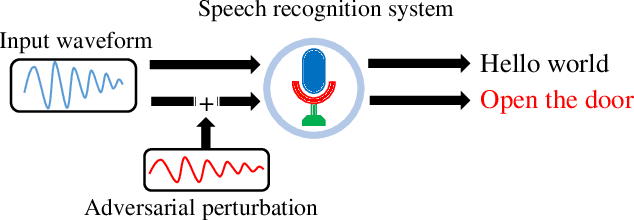


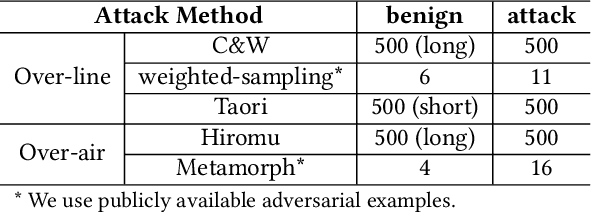
Automatic speech recognition (ASR) systems are vulnerable to audio adversarial examples that attempt to deceive ASR systems by adding perturbations to benign speech signals. Although an adversarial example and the original benign wave are indistinguishable to humans, the former is transcribed as a malicious target sentence by ASR systems. Several methods have been proposed to generate audio adversarial examples and feed them directly into the ASR system (over-line). Furthermore, many researchers have demonstrated the feasibility of robust physical audio adversarial examples(over-air). To defend against the attacks, several studies have been proposed. However, deploying them in a real-world situation is difficult because of accuracy drop or time overhead. In this paper, we propose a novel method to detect audio adversarial examples by adding noise to the logits before feeding them into the decoder of the ASR. We show that carefully selected noise can significantly impact the transcription results of the audio adversarial examples, whereas it has minimal impact on the transcription results of benign audio waves. Based on this characteristic, we detect audio adversarial examples by comparing the transcription altered by logit noising with its original transcription. The proposed method can be easily applied to ASR systems without any structural changes or additional training. The experimental results show that the proposed method is robust to over-line audio adversarial examples as well as over-air audio adversarial examples compared with state-of-the-art detection methods.