 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaon-OpenTTS: Open Models and Data for Robust Text-to-Speech
May 20, 2026Recent advances in text-to-speech (TTS) models show impressive speech naturalness and quality, yet the role of large-scale open data in driving this progress remains underexplored. In this work, we introduce Raon-OpenTTS, an open TTS model that performs competitively with state-of-the-art closed-data TTS models, and Raon-OpenTTS-Pool, a large-scale open dataset for reproducible TTS training. Raon-OpenTTS-Pool consists of 615K hours of 240M speech segments aggregated from publicly available English speech corpora and web-sourced recordings. With a model-based filtering pipeline applied to Raon-OpenTTS-Pool, we derive Raon-OpenTTS-Core, a curated, high-quality subset of 510K hours and 194M speech segments. Using Raon-OpenTTS-Core, we train Raon-OpenTTS, a series of diffusion transformer (DiT)-based TTS models from 0.3B to 1B parameters. On multiple benchmarks, Raon-OpenTTS-1B shows comparable performance to state-of-the-art models such as Qwen3-TTS and CosyVoice 3, which are trained on several million hours of proprietary speech data. Notably, on Seed-TTS-Eval, Raon-OpenTTS-1B achieves a word error rate (WER) of 1.78% and a speaker similarity (SIM) of 0.749, ranking second on WER and first on SIM among recent open-weight TTS baselines. On CV3-Hard-EN, Raon-OpenTTS-1B achieves a WER of 6.15% and a SIM of 0.775, ranking first on both metrics. Furthermore, to support robust evaluation, we introduce Raon-OpenTTS-Eval, a structured benchmark for assessing TTS robustness across diverse acoustic conditions including clean, noisy, in-the-wild, and expressive speech. On Raon-OpenTTS-Eval, Raon-OpenTTS-1B achieves the best average WER and SIM among all evaluated models, and the second-best human preference, as measured by comparative mean opinion score (CMOS). Our data pool, filtering pipeline, training code, and checkpoints are publicly available at https://github.com/krafton-ai/RAON-OpenTTS.
VLM-SubtleBench: How Far Are VLMs from Human-Level Subtle Comparative Reasoning?
Mar 09, 2026The ability to distinguish subtle differences between visually similar images is essential for diverse domains such as industrial anomaly detection, medical imaging, and aerial surveillance. While comparative reasoning benchmarks for vision-language models (VLMs) have recently emerged, they primarily focus on images with large, salient differences and fail to capture the nuanced reasoning required for real-world applications. In this work, we introduce VLM-SubtleBench, a benchmark designed to evaluate VLMs on subtle comparative reasoning. Our benchmark covers ten difference types - Attribute, State, Emotion, Temporal, Spatial, Existence, Quantity, Quality, Viewpoint, and Action - and curate paired question-image sets reflecting these fine-grained variations. Unlike prior benchmarks restricted to natural image datasets, our benchmark spans diverse domains, including industrial, aerial, and medical imagery. Through extensive evaluation of both proprietary and open-source VLMs, we reveal systematic gaps between model and human performance across difference types and domains, and provide controlled analyses highlighting where VLMs' reasoning sharply deteriorates. Together, our benchmark and findings establish a foundation for advancing VLMs toward human-level comparative reasoning.
Masked Deep Q-Recommender for Effective Question Scheduling
Dec 19, 2021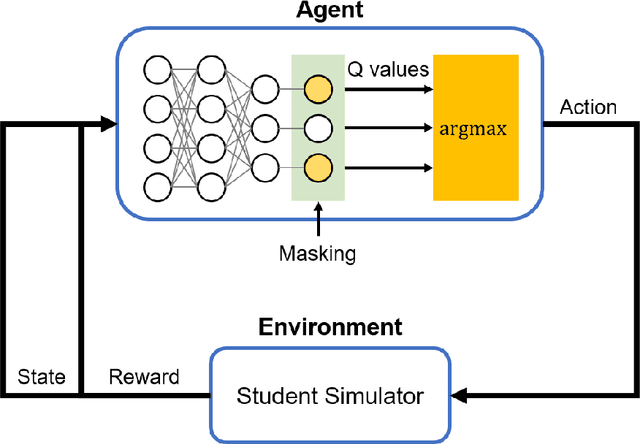
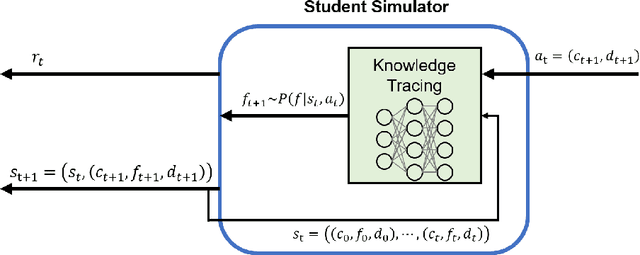
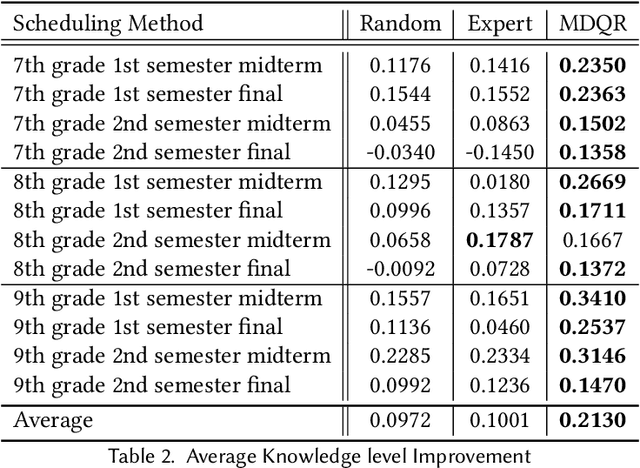
Providing appropriate questions according to a student's knowledge level is imperative in personalized learning. However, It requires a lot of manual effort for teachers to understand students' knowledge status and provide optimal questions accordingly. To address this problem, we introduce a question scheduling model that can effectively boost student knowledge level using Reinforcement Learning (RL). Our proposed method first evaluates students' concept-level knowledge using knowledge tracing (KT) model. Given predicted student knowledge, RL-based recommender predicts the benefits of each question. With curriculum range restriction and duplicate penalty, the recommender selects questions sequentially until it reaches the predefined number of questions. In an experimental setting using a student simulator, which gives 20 questions per day for two weeks, questions recommended by the proposed method increased average student knowledge level by 21.3%, superior to an expert-designed schedule baseline with a 10% increase in student knowledge levels.