 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse design of Non-parameterized Ventilated Acoustic Resonator via Variational Autoencoder with Acoustic Response-encoded Latent Space
Aug 12, 2024Ventilated acoustic resonator(VAR), a type of acoustic metamaterial, emerge as an alternative for sound attenuation in environments that require ventilation, owing to its excellent low-frequency attenuation performance and flexible shape adaptability. However, due to the non-linear acoustic responses of VARs, the VAR designs are generally obtained within a limited parametrized design space, and the design relies on the iteration of the numerical simulation which consumes a considerable amount of computational time and resources. This paper proposes an acoustic response-encoded variational autoencoder (AR-VAE), a novel variational autoencoder-based generative design model for the efficient and accurate inverse design of VAR even with non-parametrized designs. The AR-VAE matches the high-dimensional acoustic response with the VAR cross-section image in the dimension-reduced latent space, which enables the AR-VAE to generate various non-parametrized VAR cross-section images with the target acoustic response. AR-VAE generates non-parameterized VARs from target acoustic responses, which show a 25-fold reduction in mean squared error compared to conventional deep learning-based parameter searching methods while exhibiting lower average mean squared error and peak frequency variance. By combining the inverse-designed VARs by AR-VAE, multi-cavity VAR was devised for broadband and multitarget peak frequency attenuation. The proposed design method presents a new approach for structural inverse-design with a high-dimensional non-linear physical response.
D-Score: A Synapse-Inspired Approach for Filter Pruning
Aug 08, 2023This paper introduces a new aspect for determining the rank of the unimportant filters for filter pruning on convolutional neural networks (CNNs). In the human synaptic system, there are two important channels known as excitatory and inhibitory neurotransmitters that transmit a signal from a neuron to a cell. Adopting the neuroscientific perspective, we propose a synapse-inspired filter pruning method, namely Dynamic Score (D-Score). D-Score analyzes the independent importance of positive and negative weights in the filters and ranks the independent importance by assigning scores. Filters having low overall scores, and thus low impact on the accuracy of neural networks are pruned. The experimental results on CIFAR-10 and ImageNet datasets demonstrate the effectiveness of our proposed method by reducing notable amounts of FLOPs and Params without significant Acc. Drop.
A Generalized Supervised Contrastive Learning Framework
Jun 01, 2022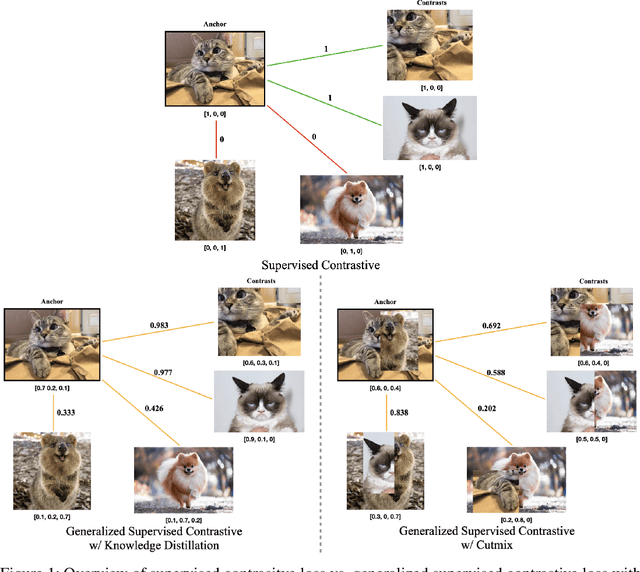

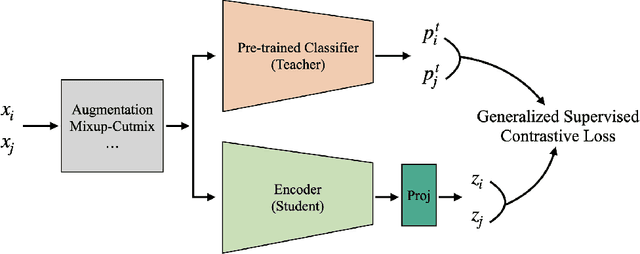

Based on recent remarkable achievements of contrastive learning in self-supervised representation learning, supervised contrastive learning (SupCon) has successfully extended the batch contrastive approaches to the supervised context and outperformed cross-entropy on various datasets on ResNet. In this work, we present GenSCL: a generalized supervised contrastive learning framework that seamlessly adapts modern image-based regularizations (such as Mixup-Cutmix) and knowledge distillation (KD) to SupCon by our generalized supervised contrastive loss. Generalized supervised contrastive loss is a further extension of supervised contrastive loss measuring cross-entropy between the similarity of labels and that of latent features. Then a model can learn to what extent contrastives should be pulled closer to an anchor in the latent space. By explicitly and fully leveraging label information, GenSCL breaks the boundary between conventional positives and negatives, and any kind of pre-trained teacher classifier can be utilized. ResNet-50 trained in GenSCL with Mixup-Cutmix and KD achieves state-of-the-art accuracies of 97.6% and 84.7% on CIFAR10 and CIFAR100 without external data, which significantly improves the results reported in the original SupCon (1.6% and 8.2%, respectively). Pytorch implementation is available at https://t.ly/yuUO.