 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLP-GEMM: Integrating Layout Propagation into GEMM Operations
Apr 06, 2026In Scientific Computing and modern Machine Learning (ML) workloads, sequences of dependent General Matrix Multiplications (GEMMs) often dominate execution time. While state-of-the-art BLAS libraries aggressively optimize individual GEMM calls, they remain constrained by the BLAS API, which requires each call to independently pack input matrices and restore outputs to a canonical memory layout. In sequential GEMMs, these constraints cause redundant packing and unpacking, wasting valuable computational resources. This paper introduces LP-GEMM, a decomposition of the GEMM kernel that enables packing-layout propagation across sequential GEMM operations. This approach eliminates unnecessary data repacking while preserving full BLAS semantic correctness at the boundaries. We evaluate LP-GEMM on x86 (AVX-512) and RISC-V (RVV 1.0) architectures across MLP-like and Attention-like workloads. Our results show average speedups of 2.25x over OpenBLAS on Intel x86 for sequential GEMMs and competitive gains relative to vendor-optimized libraries such as Intel MKL. We demonstrate the practicality of the approach beyond microbenchmarks by implementing a standalone C++ version of the Llama-3.2 inference path using exclusively BLAS-level GEMM calls. These results confirm that leveraging data layout propagation between operations can significantly boost performance.
Binary Segmentation of Seismic Facies Using Encoder-Decoder Neural Networks
Nov 15, 2020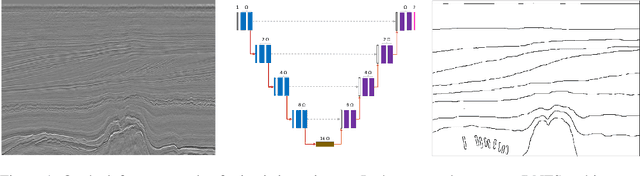
The interpretation of seismic data is vital for characterizing sediments' shape in areas of geological study. In seismic interpretation, deep learning becomes useful for reducing the dependence on handcrafted facies segmentation geometry and the time required to study geological areas. This work presents a Deep Neural Network for Facies Segmentation (DNFS) to obtain state-of-the-art results for seismic facies segmentation. DNFS is trained using a combination of cross-entropy and Jaccard loss functions. Our results show that DNFS obtains highly detailed predictions for seismic facies segmentation using fewer parameters than StNet and U-Net.