 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREVENT-JACK: Context Steering for Swarms of Long Heavy Articulated Vehicles
Apr 23, 2026In this paper, we aim to extend the traditional point-mass-like robot representation in swarm robotics and instead study a swarm of long Heavy Articulated Vehicles (HAVs). HAVs are kinematically constrained, elongated, and articulated, introducing unique challenges. Local, decentralized coordination of these vehicles is motivated by many real-world applications. Our approach, Prevent-Jack, introduces the sparsely covered context steering framework in robotics. It fuses six local behaviors, providing guarantees against jackknifing and collisions at the cost of potential dead- and livelocks, tested for vehicles with up to ten trailers. We highlight the importance of the Evade Attraction behavior for deadlock prevention using a parameter study, and use 15,000 simulations to evaluate the swarm performance. Our extensive experiments and the results show that both the dead- and livelocks occur more frequently in larger swarms and denser scenarios, affecting a peak average of 27%/31% of vehicles. We observe that larger swarms exhibit increased waiting, while smaller swarms show increased evasion.
AVOID-JACK: Avoidance of Jackknifing for Swarms of Long Heavy Articulated Vehicles
Nov 11, 2025



This paper presents a novel approach to avoiding jackknifing and mutual collisions in Heavy Articulated Vehicles (HAVs) by leveraging decentralized swarm intelligence. In contrast to typical swarm robotics research, our robots are elongated and exhibit complex kinematics, introducing unique challenges. Despite its relevance to real-world applications such as logistics automation, remote mining, airport baggage transport, and agricultural operations, this problem has not been addressed in the existing literature. To tackle this new class of swarm robotics problems, we propose a purely reaction-based, decentralized swarm intelligence strategy tailored to automate elongated, articulated vehicles. The method presented in this paper prioritizes jackknifing avoidance and establishes a foundation for mutual collision avoidance. We validate our approach through extensive simulation experiments and provide a comprehensive analysis of its performance. For the experiments with a single HAV, we observe that for 99.8% jackknifing was successfully avoided and that 86.7% and 83.4% reach their first and second goals, respectively. With two HAVs interacting, we observe 98.9%, 79.4%, and 65.1%, respectively, while 99.7% of the HAVs do not experience mutual collisions.
The Road to Learning Explainable Inverse Kinematic Models: Graph Neural Networks as Inductive Bias for Symbolic Regression
Jan 23, 2025This paper shows how a Graph Neural Network (GNN) can be used to learn an Inverse Kinematics (IK) based on an automatically generated dataset. The generated Inverse Kinematics is generalized to a family of manipulators with the same Degree of Freedom (DOF), but varying link length configurations. The results indicate a position error of less than 1.0 cm for 3 DOF and 4.5 cm for 5 DOF, and orientation error of 2$^\circ$ for 3 DOF and 8.2$^\circ$ for 6 DOF, which allows the deployment to certain real world-problems. However, out-of-domain errors and lack of extrapolation can be observed in the resulting GNN. An extensive analysis of these errors indicates potential for enhancement in the future. Consequently, the generated GNNs are tailored to be used in future work as an inductive bias to generate analytical equations through symbolic regression.
Match Point AI: A Novel AI Framework for Evaluating Data-Driven Tennis Strategies
Aug 12, 2024



Many works in the domain of artificial intelligence in games focus on board or video games due to the ease of reimplementing their mechanics. Decision-making problems in real-world sports share many similarities to such domains. Nevertheless, not many frameworks on sports games exist. In this paper, we present the tennis match simulation environment \textit{Match Point AI}, in which different agents can compete against real-world data-driven bot strategies. Next to presenting the framework, we highlight its capabilities by illustrating, how MCTS can be used in Match Point AI to optimize the shot direction selection problem in tennis. While the framework will be extended in the future, first experiments already reveal that generated shot-by-shot data of simulated tennis matches show realistic characteristics when compared to real-world data. At the same time, reasonable shot placement strategies emerge, which share similarities to the ones found in real-world tennis matches.
Shape Constraints in Symbolic Regression using Penalized Least Squares
May 31, 2024We study the addition of shape constraints and their consideration during the parameter estimation step of symbolic regression (SR). Shape constraints serve as a means to introduce prior knowledge about the shape of the otherwise unknown model function into SR. Unlike previous works that have explored shape constraints in SR, we propose minimizing shape constraint violations during parameter estimation using gradient-based numerical optimization. We test three algorithm variants to evaluate their performance in identifying three symbolic expressions from a synthetically generated data set. This paper examines two benchmark scenarios: one with varying noise levels and another with reduced amounts of training data. The results indicate that incorporating shape constraints into the expression search is particularly beneficial when data is scarce. Compared to using shape constraints only in the selection process, our approach of minimizing violations during parameter estimation shows a statistically significant benefit in some of our test cases, without being significantly worse in any instance.
Unit-Aware Genetic Programming for the Development of Empirical Equations
May 29, 2024



When developing empirical equations, domain experts require these to be accurate and adhere to physical laws. Often, constants with unknown units need to be discovered alongside the equations. Traditional unit-aware genetic programming (GP) approaches cannot be used when unknown constants with undetermined units are included. This paper presents a method for dimensional analysis that propagates unknown units as ''jokers'' and returns the magnitude of unit violations. We propose three methods, namely evolutive culling, a repair mechanism, and a multi-objective approach, to integrate the dimensional analysis in the GP algorithm. Experiments on datasets with ground truth demonstrate comparable performance of evolutive culling and the multi-objective approach to a baseline without dimensional analysis. Extensive analysis of the results on datasets without ground truth reveals that the unit-aware algorithms make only low sacrifices in accuracy, while producing unit-adherent solutions. Overall, we presented a promising novel approach for developing unit-adherent empirical equations.
Optimized Drug Design using Multi-Objective Evolutionary Algorithms with SELFIES
May 01, 2024



Computer aided drug design is a promising approach to reduce the tremendous costs, i.e. time and resources, for developing new medicinal drugs. It finds application in aiding the traversal of the vast chemical space of potentially useful compounds. In this paper, we deploy multi-objective evolutionary algorithms, namely NSGA-II, NSGA-III, and MOEA/D, for this purpose. At the same time, we used the SELFIES string representation method. In addition to the QED and SA score, we optimize compounds using the GuacaMol benchmark multi-objective task sets. Our results indicate that all three algorithms show converging behavior and successfully optimize the defined criteria whilst differing mainly in the number of potential solutions found. We observe that novel and promising candidates for synthesis are discovered among obtained compounds in the Pareto-sets.
Optimal Control Policies to Address the Pandemic Health-Economy Dilemma
Feb 24, 2021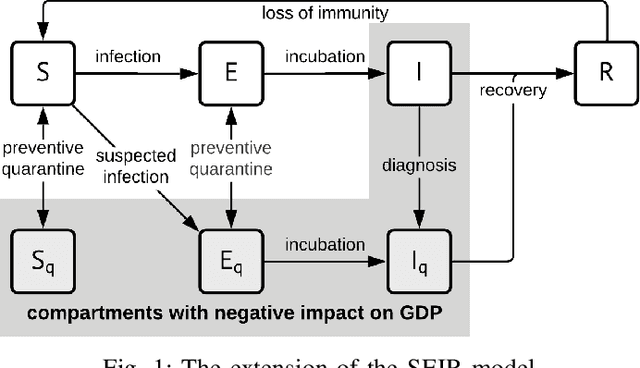
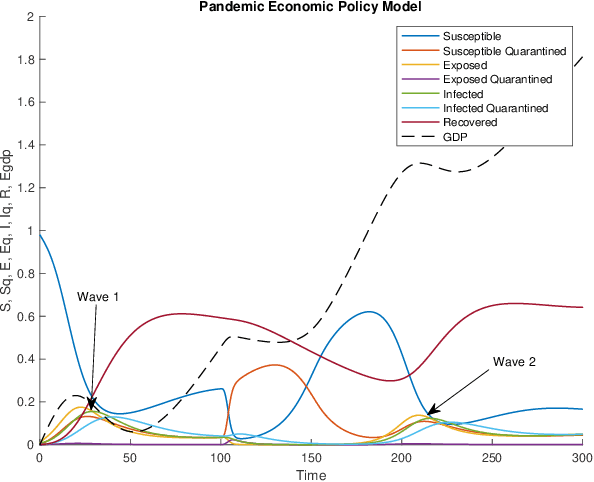
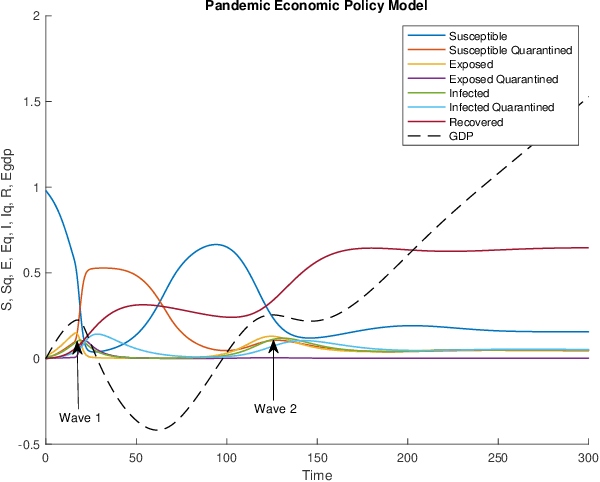
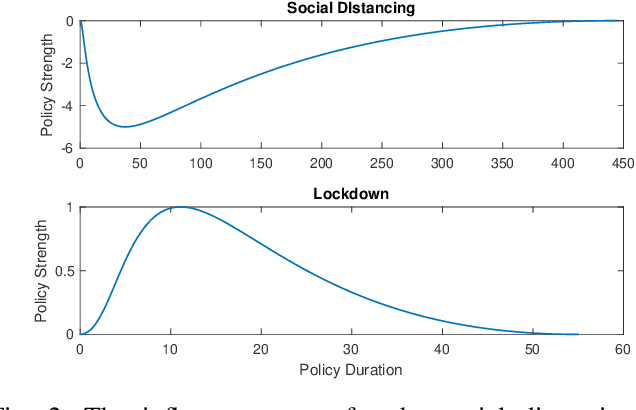
Non-pharmaceutical interventions (NPIs) are effective measures to contain a pandemic. Yet, such control measures commonly have a negative effect on the economy. Here, we propose a macro-level approach to support resolving this Health-Economy Dilemma (HED). First, an extension to the well-known SEIR model is suggested which includes an economy model. Second, a bi-objective optimization problem is defined to study optimal control policies in view of the HED problem. Next, several multi-objective evolutionary algorithms are applied to perform a study on the health-economy performance trade-offs that are inherent to the obtained optimal policies. Finally, the results from the applied algorithms are compared to select a preferred algorithm for future studies. As expected, for the proposed models and strategies, a clear conflict between the health and economy performances is found. Furthermore, the results suggest that the guided usage of NPIs is preferable as compared to refraining from employing such strategies at all. This study contributes to pandemic modeling and simulation by providing a novel concept that elaborates on integrating economic aspects while exploring the optimal moment to enable NPIs.
Scalable Many-Objective Pathfinding Benchmark Suite
Oct 09, 2020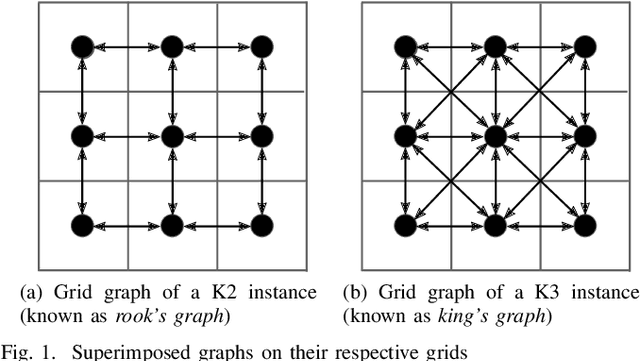
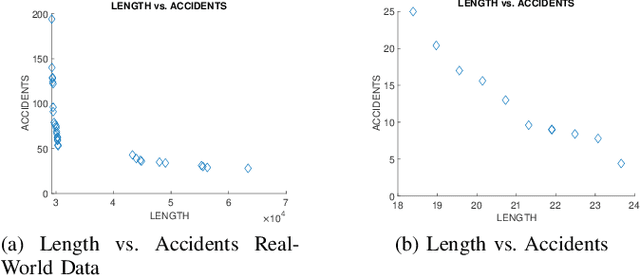
Route planning also known as pathfinding is one of the key elements in logistics, mobile robotics and other applications, where engineers face many conflicting objectives. However, most of the current route planning algorithms consider only up to three objectives. In this paper, we propose a scalable many-objective benchmark problem covering most of the important features for routing applications based on real-world data. We define five objective functions representing distance, traveling time, delays caused by accidents, and two route specific features such as curvature and elevation. We analyse several different instances for this test problem and provide their true Pareto-front to analyse the problem difficulties. We apply three well-known evolutionary multi-objective algorithms. Since this test benchmark can be easily transferred to real-world routing problems, we construct a routing problem from OpenStreetMap data. We evaluate the three optimisation algorithms and observe that we are able to provide promising results for such a real-world application. The proposed benchmark represents a scalable many-objective route planning optimisation problem enabling researchers and engineers to evaluate their many-objective approaches.
sKPNSGA-II: Knee point based MOEA with self-adaptive angle for Mission Planning Problems
Feb 20, 2020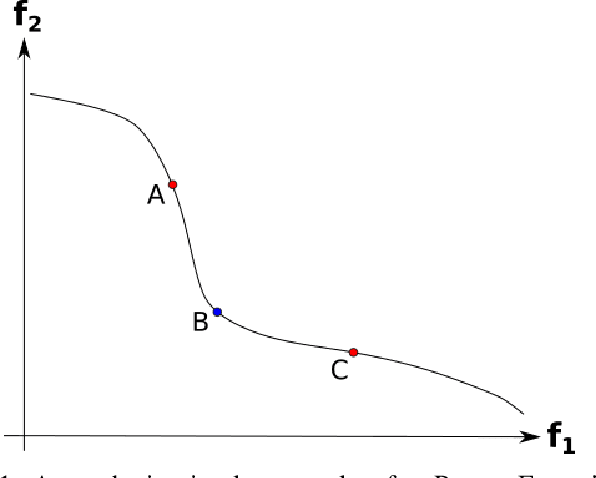
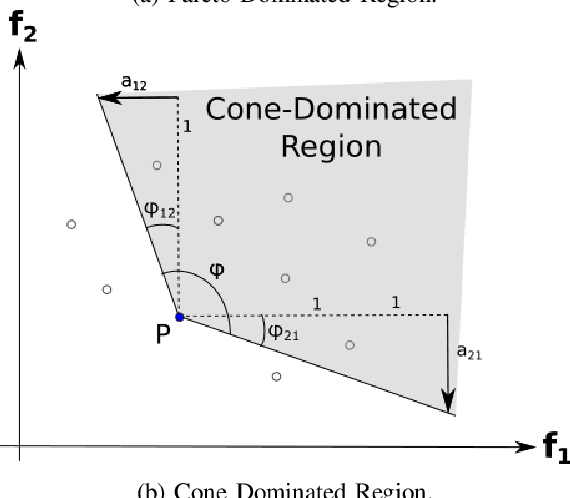
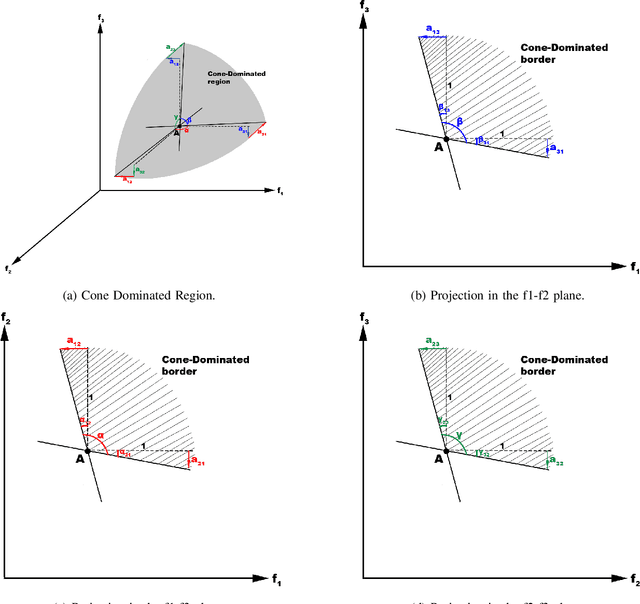
Real-world and complex problems have usually many objective functions that have to be optimized all at once. Over the last decades, Multi-Objective Evolutionary Algorithms (MOEAs) are designed to solve this kind of problems. Nevertheless, some problems have many objectives which lead to a large number of non-dominated solutions obtained by the optimization algorithms. The large set of non-dominated solutions hinders the selection of the most appropriate solution by the decision maker. This paper presents a new algorithm that has been designed to obtain the most significant solutions from the Pareto Optimal Frontier (POF). This approach is based on the cone-domination applied to MOEA, which can find the knee point solutions. In order to obtain the best cone angle, we propose a hypervolume-distribution metric, which is used to self-adapt the angle during the evolving process. This new algorithm has been applied to the real world application in Unmanned Air Vehicle (UAV) Mission Planning Problem. The experimental results show a significant improvement of the algorithm performance in terms of hypervolume, number of solutions, and also the required number of generations to converge.