 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandheld Mobile Photography in Very Low Light
Oct 24, 2019

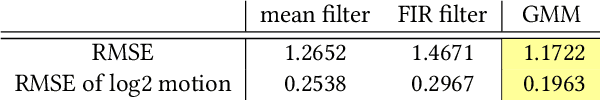

Taking photographs in low light using a mobile phone is challenging and rarely produces pleasing results. Aside from the physical limits imposed by read noise and photon shot noise, these cameras are typically handheld, have small apertures and sensors, use mass-produced analog electronics that cannot easily be cooled, and are commonly used to photograph subjects that move, like children and pets. In this paper we describe a system for capturing clean, sharp, colorful photographs in light as low as 0.3~lux, where human vision becomes monochromatic and indistinct. To permit handheld photography without flash illumination, we capture, align, and combine multiple frames. Our system employs "motion metering", which uses an estimate of motion magnitudes (whether due to handshake or moving objects) to identify the number of frames and the per-frame exposure times that together minimize both noise and motion blur in a captured burst. We combine these frames using robust alignment and merging techniques that are specialized for high-noise imagery. To ensure accurate colors in such low light, we employ a learning-based auto white balancing algorithm. To prevent the photographs from looking like they were shot in daylight, we use tone mapping techniques inspired by illusionistic painting: increasing contrast, crushing shadows to black, and surrounding the scene with darkness. All of these processes are performed using the limited computational resources of a mobile device. Our system can be used by novice photographers to produce shareable pictures in a few seconds based on a single shutter press, even in environments so dim that humans cannot see clearly.
* 22 pages, 27 figures
Deep Bilateral Learning for Real-Time Image Enhancement
Aug 22, 2017
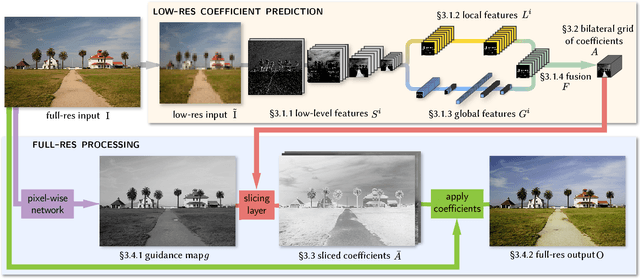
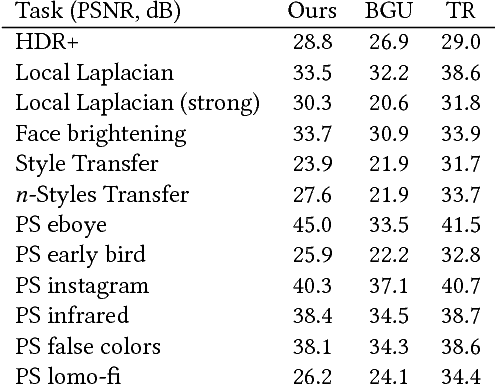

Performance is a critical challenge in mobile image processing. Given a reference imaging pipeline, or even human-adjusted pairs of images, we seek to reproduce the enhancements and enable real-time evaluation. For this, we introduce a new neural network architecture inspired by bilateral grid processing and local affine color transforms. Using pairs of input/output images, we train a convolutional neural network to predict the coefficients of a locally-affine model in bilateral space. Our architecture learns to make local, global, and content-dependent decisions to approximate the desired image transformation. At runtime, the neural network consumes a low-resolution version of the input image, produces a set of affine transformations in bilateral space, upsamples those transformations in an edge-preserving fashion using a new slicing node, and then applies those upsampled transformations to the full-resolution image. Our algorithm processes high-resolution images on a smartphone in milliseconds, provides a real-time viewfinder at 1080p resolution, and matches the quality of state-of-the-art approximation techniques on a large class of image operators. Unlike previous work, our model is trained off-line from data and therefore does not require access to the original operator at runtime. This allows our model to learn complex, scene-dependent transformations for which no reference implementation is available, such as the photographic edits of a human retoucher.
* 12 pages, 14 figures, Siggraph 2017