 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCold Posteriors and Aleatoric Uncertainty
Jul 31, 2020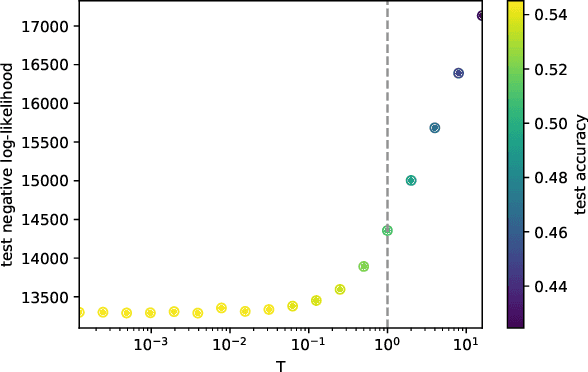
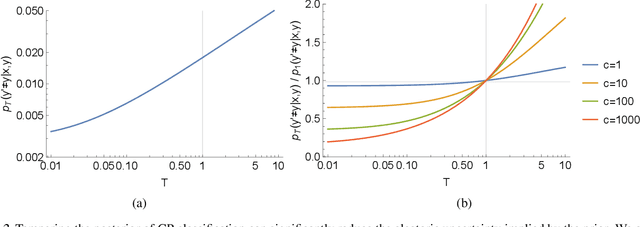
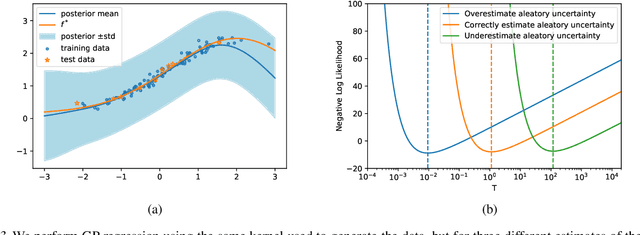
Recent work has observed that one can outperform exact inference in Bayesian neural networks by tuning the "temperature" of the posterior on a validation set (the "cold posterior" effect). To help interpret this phenomenon, we argue that commonly used priors in Bayesian neural networks can significantly overestimate the aleatoric uncertainty in the labels on many classification datasets. This problem is particularly pronounced in academic benchmarks like MNIST or CIFAR, for which the quality of the labels is high. For the special case of Gaussian process regression, any positive temperature corresponds to a valid posterior under a modified prior, and tuning this temperature is directly analogous to empirical Bayes. On classification tasks, there is no direct equivalence between modifying the prior and tuning the temperature, however reducing the temperature can lead to models which better reflect our belief that one gains little information by relabeling existing examples in the training set. Therefore although cold posteriors do not always correspond to an exact inference procedure, we believe they may often better reflect our true prior beliefs.
* 5 pages, 3 figures
On the Generalization Benefit of Noise in Stochastic Gradient Descent
Jun 26, 2020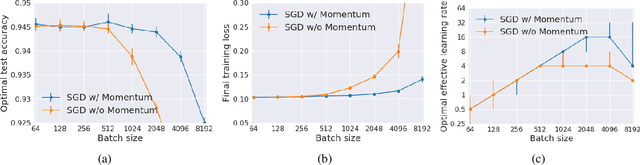
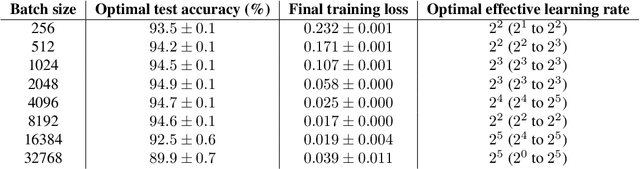
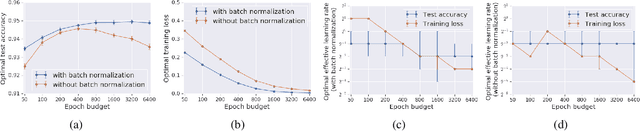
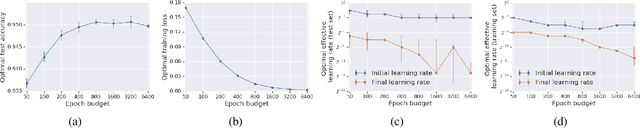
It has long been argued that minibatch stochastic gradient descent can generalize better than large batch gradient descent in deep neural networks. However recent papers have questioned this claim, arguing that this effect is simply a consequence of suboptimal hyperparameter tuning or insufficient compute budgets when the batch size is large. In this paper, we perform carefully designed experiments and rigorous hyperparameter sweeps on a range of popular models, which verify that small or moderately large batch sizes can substantially outperform very large batches on the test set. This occurs even when both models are trained for the same number of iterations and large batches achieve smaller training losses. Our results confirm that the noise in stochastic gradients can enhance generalization. We study how the optimal learning rate schedule changes as the epoch budget grows, and we provide a theoretical account of our observations based on the stochastic differential equation perspective of SGD dynamics.
Batch Normalization Biases Deep Residual Networks Towards Shallow Paths
Feb 24, 2020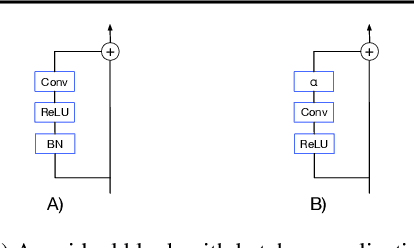
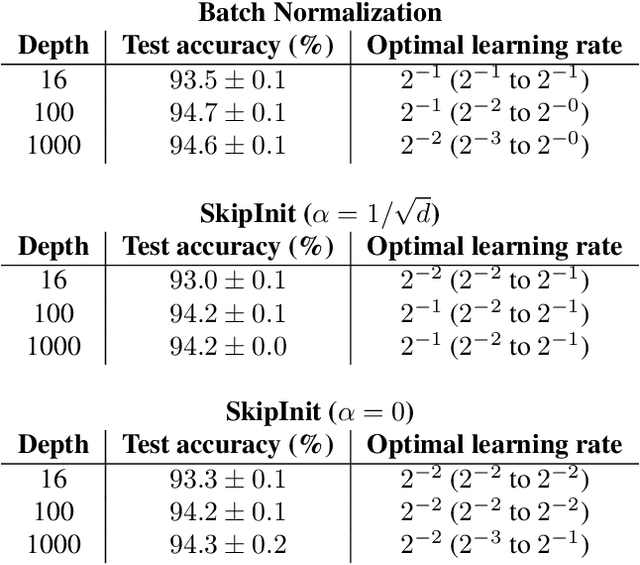
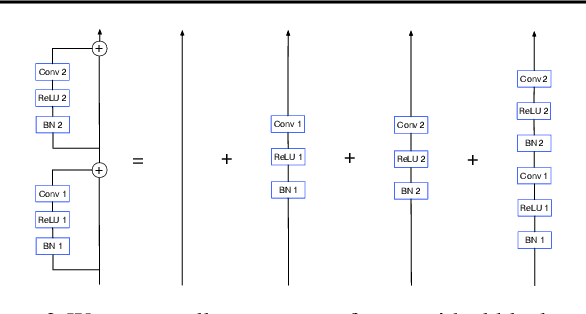
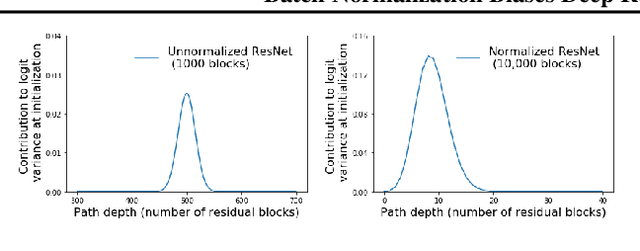
Batch normalization has multiple benefits. It improves the conditioning of the loss landscape, and is a surprisingly effective regularizer. However, the most important benefit of batch normalization arises in residual networks, where it dramatically increases the largest trainable depth. We identify the origin of this benefit: At initialization, batch normalization downscales the residual branch relative to the skip connection, by a normalizing factor proportional to the square root of the network depth. This ensures that, early in training, the function computed by deep normalized residual networks is dominated by shallow paths with well-behaved gradients. We use this insight to develop a simple initialization scheme which can train very deep residual networks without normalization. We also clarify that, although batch normalization does enable stable training with larger learning rates, this benefit is only useful when one wishes to parallelize training over large batch sizes. Our results help isolate the distinct benefits of batch normalization in different architectures.
The Effect of Network Width on Stochastic Gradient Descent and Generalization: an Empirical Study
May 09, 2019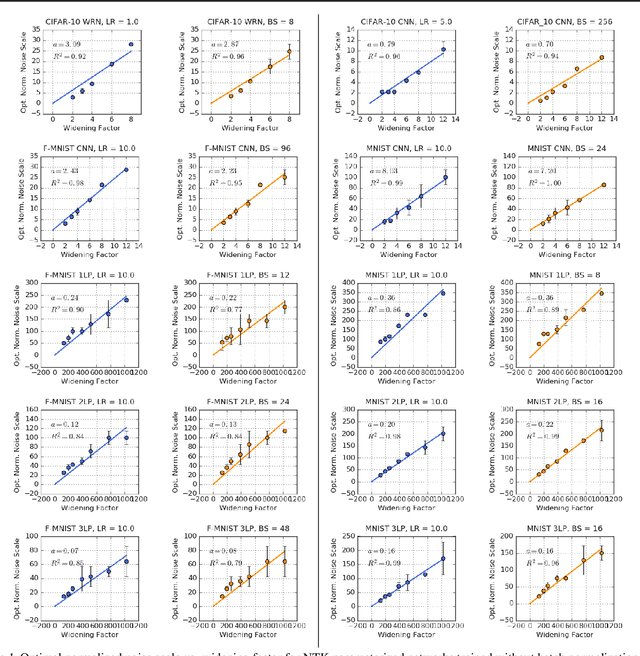
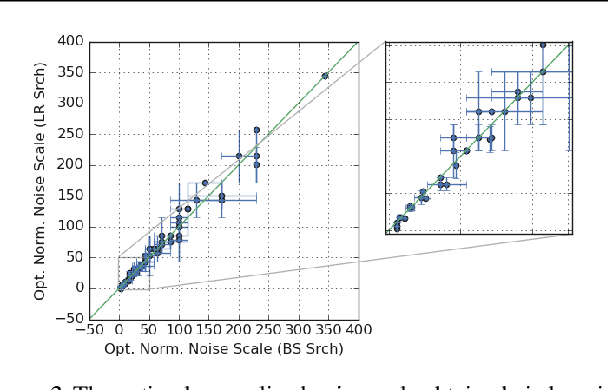
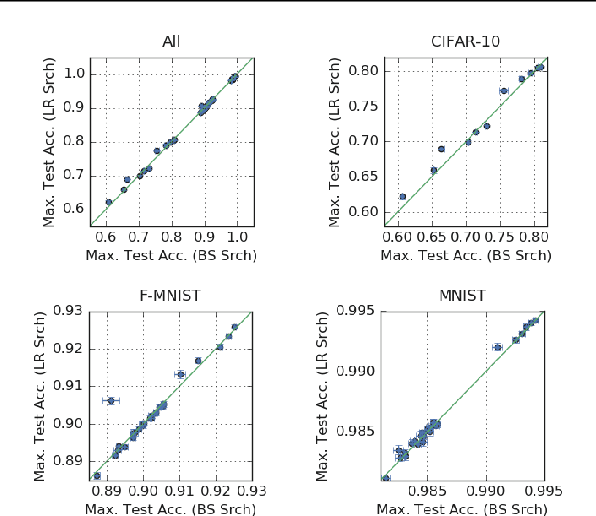

We investigate how the final parameters found by stochastic gradient descent are influenced by over-parameterization. We generate families of models by increasing the number of channels in a base network, and then perform a large hyper-parameter search to study how the test error depends on learning rate, batch size, and network width. We find that the optimal SGD hyper-parameters are determined by a "normalized noise scale," which is a function of the batch size, learning rate, and initialization conditions. In the absence of batch normalization, the optimal normalized noise scale is directly proportional to width. Wider networks, with their higher optimal noise scale, also achieve higher test accuracy. These observations hold for MLPs, ConvNets, and ResNets, and for two different parameterization schemes ("Standard" and "NTK"). We observe a similar trend with batch normalization for ResNets. Surprisingly, since the largest stable learning rate is bounded, the largest batch size consistent with the optimal normalized noise scale decreases as the width increases.
Stochastic natural gradient descent draws posterior samples in function space
Oct 16, 2018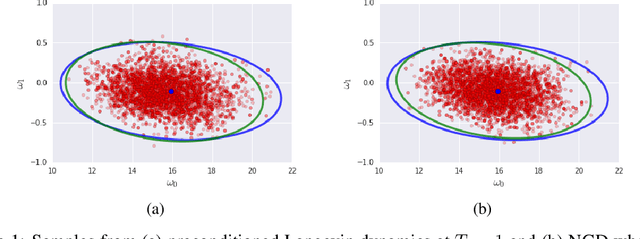
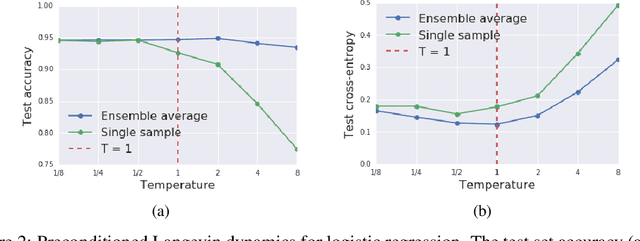
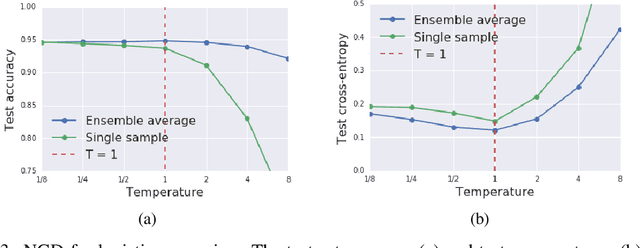
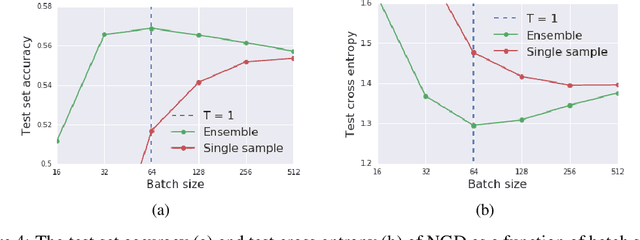
We prove that as the model predictions on the training set approach the true conditional distribution of labels given inputs, the noise inherent in minibatch gradients causes the stationary distribution of natural gradient descent to approach a Bayesian posterior near local minima as the learning rate $\epsilon \rightarrow 0$. The temperature $T \approx \epsilon N/(2B)$ of this posterior is controlled by the learning rate, training set size $N$ and batch size $B$. However minibatch NGD is not parameterisation invariant, and we therefore introduce "stochastic natural gradient descent", which preserves parameterisation invariance by introducing a multiplicative bias to the stationary distribution. We identify this bias as the well known Jeffreys prior. To support our claims, we show that the distribution of samples from NGD is close to the Laplace approximation to the posterior when $T = 1$. Furthermore, the test loss of ensembles drawn using NGD falls rapidly as we increase the batch size until $B \approx \epsilon N/2$, while above this point the test loss is constant or rises slowly.
Decoding Decoders: Finding Optimal Representation Spaces for Unsupervised Similarity Tasks
May 09, 2018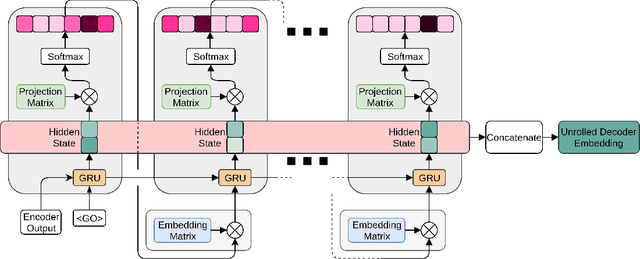
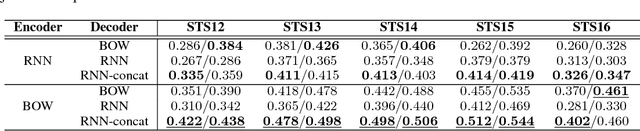
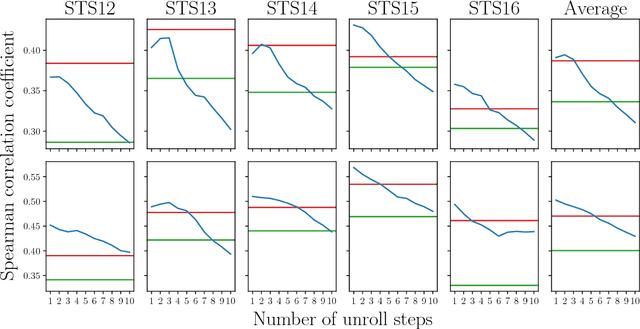

Experimental evidence indicates that simple models outperform complex deep networks on many unsupervised similarity tasks. We provide a simple yet rigorous explanation for this behaviour by introducing the concept of an optimal representation space, in which semantically close symbols are mapped to representations that are close under a similarity measure induced by the model's objective function. In addition, we present a straightforward procedure that, without any retraining or architectural modifications, allows deep recurrent models to perform equally well (and sometimes better) when compared to shallow models. To validate our analysis, we conduct a set of consistent empirical evaluations and introduce several new sentence embedding models in the process. Even though this work is presented within the context of natural language processing, the insights are readily applicable to other domains that rely on distributed representations for transfer tasks.
Don't Decay the Learning Rate, Increase the Batch Size
Feb 24, 2018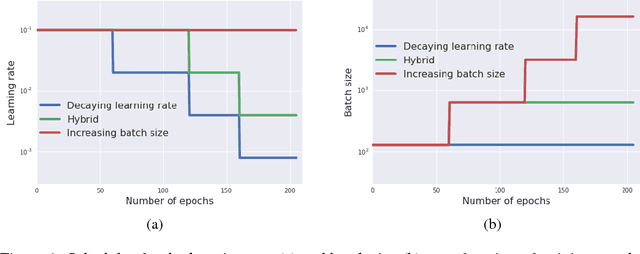
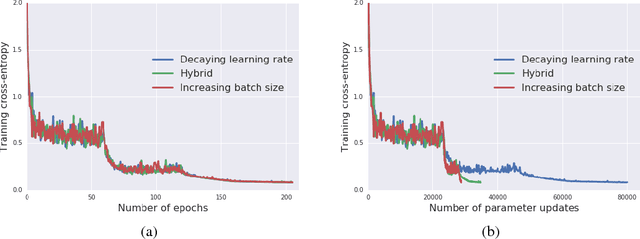
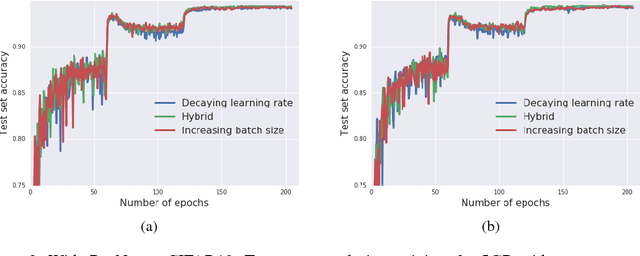
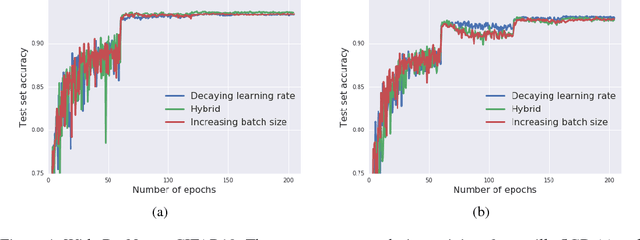
It is common practice to decay the learning rate. Here we show one can usually obtain the same learning curve on both training and test sets by instead increasing the batch size during training. This procedure is successful for stochastic gradient descent (SGD), SGD with momentum, Nesterov momentum, and Adam. It reaches equivalent test accuracies after the same number of training epochs, but with fewer parameter updates, leading to greater parallelism and shorter training times. We can further reduce the number of parameter updates by increasing the learning rate $\epsilon$ and scaling the batch size $B \propto \epsilon$. Finally, one can increase the momentum coefficient $m$ and scale $B \propto 1/(1-m)$, although this tends to slightly reduce the test accuracy. Crucially, our techniques allow us to repurpose existing training schedules for large batch training with no hyper-parameter tuning. We train ResNet-50 on ImageNet to $76.1\%$ validation accuracy in under 30 minutes.
A Bayesian Perspective on Generalization and Stochastic Gradient Descent
Feb 14, 2018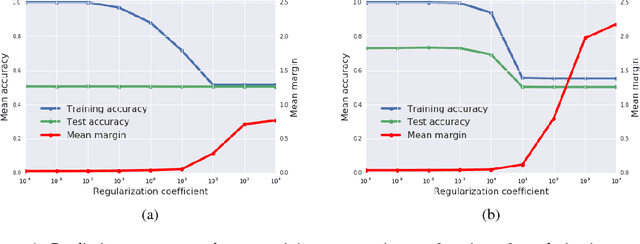
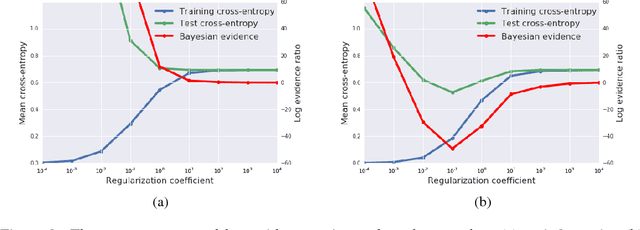
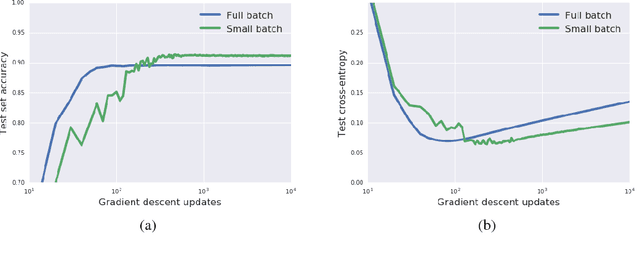
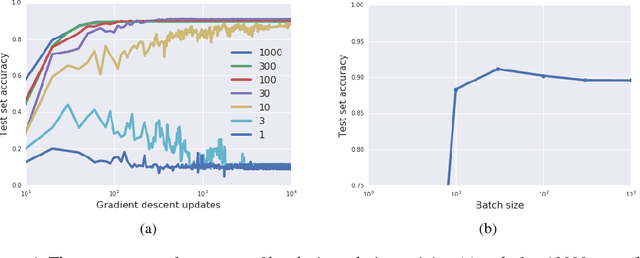
We consider two questions at the heart of machine learning; how can we predict if a minimum will generalize to the test set, and why does stochastic gradient descent find minima that generalize well? Our work responds to Zhang et al. (2016), who showed deep neural networks can easily memorize randomly labeled training data, despite generalizing well on real labels of the same inputs. We show that the same phenomenon occurs in small linear models. These observations are explained by the Bayesian evidence, which penalizes sharp minima but is invariant to model parameterization. We also demonstrate that, when one holds the learning rate fixed, there is an optimum batch size which maximizes the test set accuracy. We propose that the noise introduced by small mini-batches drives the parameters towards minima whose evidence is large. Interpreting stochastic gradient descent as a stochastic differential equation, we identify the "noise scale" $g = \epsilon (\frac{N}{B} - 1) \approx \epsilon N/B$, where $\epsilon$ is the learning rate, $N$ the training set size and $B$ the batch size. Consequently the optimum batch size is proportional to both the learning rate and the size of the training set, $B_{opt} \propto \epsilon N$. We verify these predictions empirically.
Offline bilingual word vectors, orthogonal transformations and the inverted softmax
Feb 13, 2017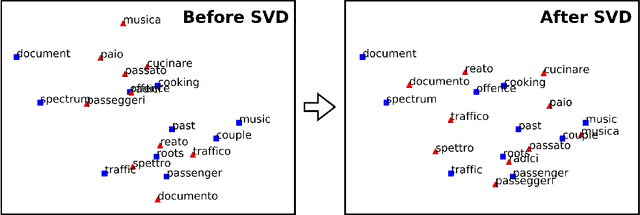
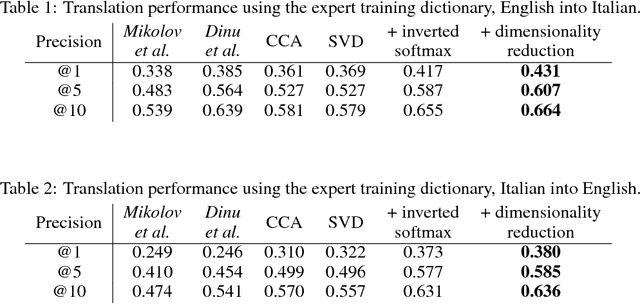
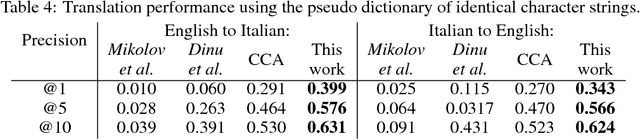
Usually bilingual word vectors are trained "online". Mikolov et al. showed they can also be found "offline", whereby two pre-trained embeddings are aligned with a linear transformation, using dictionaries compiled from expert knowledge. In this work, we prove that the linear transformation between two spaces should be orthogonal. This transformation can be obtained using the singular value decomposition. We introduce a novel "inverted softmax" for identifying translation pairs, with which we improve the precision @1 of Mikolov's original mapping from 34% to 43%, when translating a test set composed of both common and rare English words into Italian. Orthogonal transformations are more robust to noise, enabling us to learn the transformation without expert bilingual signal by constructing a "pseudo-dictionary" from the identical character strings which appear in both languages, achieving 40% precision on the same test set. Finally, we extend our method to retrieve the true translations of English sentences from a corpus of 200k Italian sentences with a precision @1 of 68%.