 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Convolutional Decoder for Image Caption Generation
Mar 08, 2021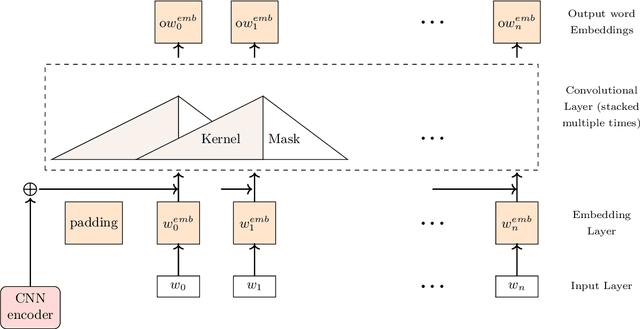

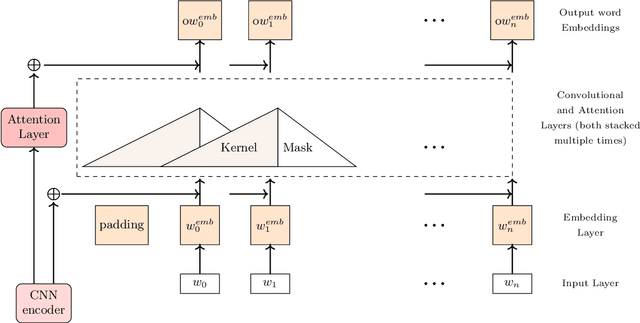
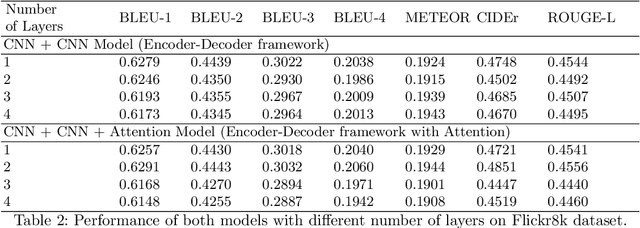
Recently Convolutional Neural Networks have been proposed for Sequence Modelling tasks such as Image Caption Generation. However, unlike Recurrent Neural Networks, the performance of Convolutional Neural Networks as Decoders for Image Caption Generation has not been extensively studied. In this work, we analyse various aspects of Convolutional Neural Network based Decoders such as Network complexity and depth, use of Data Augmentation, Attention mechanism, length of sentences used during training, etc on performance of the model. We perform experiments using Flickr8k and Flickr30k image captioning datasets and observe that unlike Recurrent Neural Network based Decoder, Convolutional Decoder for Image Captioning does not generally benefit from increase in network depth, in the form of stacked Convolutional Layers, and also the use of Data Augmentation techniques. In addition, use of Attention mechanism also provides limited performance gains with Convolutional Decoder. Furthermore, we observe that Convolutional Decoders show performance comparable with Recurrent Decoders only when trained using sentences of smaller length which contain up to 15 words but they have limitations when trained using higher sentence lengths which suggests that Convolutional Decoders may not be able to model long-term dependencies efficiently. In addition, the Convolutional Decoder usually performs poorly on CIDEr evaluation metric as compared to Recurrent Decoder.
Comparative evaluation of CNN architectures for Image Caption Generation
Feb 23, 2021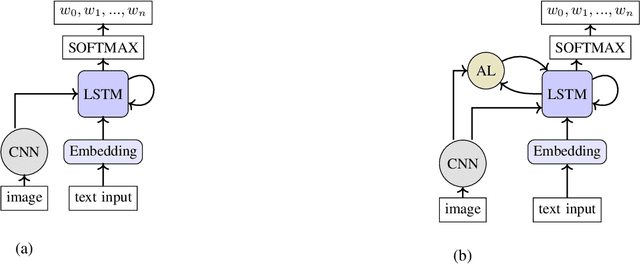
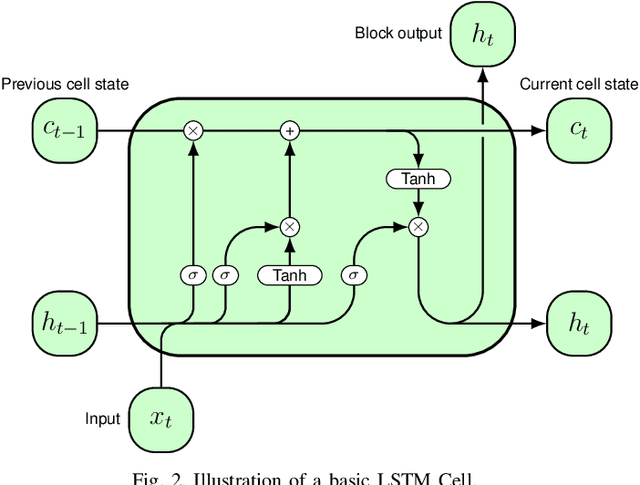
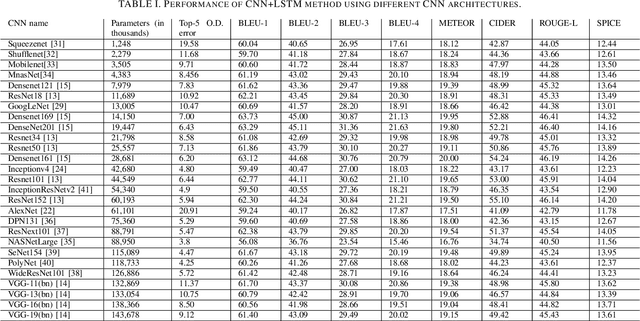
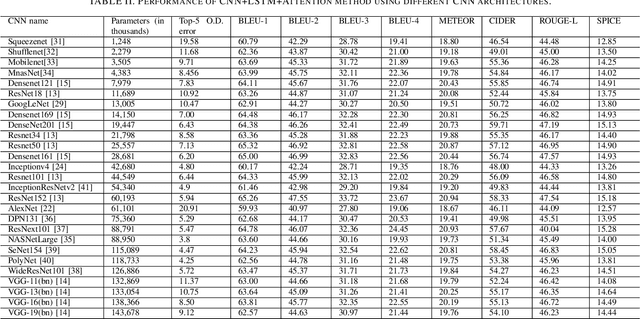
Aided by recent advances in Deep Learning, Image Caption Generation has seen tremendous progress over the last few years. Most methods use transfer learning to extract visual information, in the form of image features, with the help of pre-trained Convolutional Neural Network models followed by transformation of the visual information using a Caption Generator module to generate the output sentences. Different methods have used different Convolutional Neural Network Architectures and, to the best of our knowledge, there is no systematic study which compares the relative efficacy of different Convolutional Neural Network architectures for extracting the visual information. In this work, we have evaluated 17 different Convolutional Neural Networks on two popular Image Caption Generation frameworks: the first based on Neural Image Caption (NIC) generation model and the second based on Soft-Attention framework. We observe that model complexity of Convolutional Neural Network, as measured by number of parameters, and the accuracy of the model on Object Recognition task does not necessarily co-relate with its efficacy on feature extraction for Image Caption Generation task.
* Article Published in International Journal of Advanced Computer Science and Applications(IJACSA), Volume 11 Issue 12, 2020
Image Captioning using Deep Stacked LSTMs, Contextual Word Embeddings and Data Augmentation
Feb 22, 2021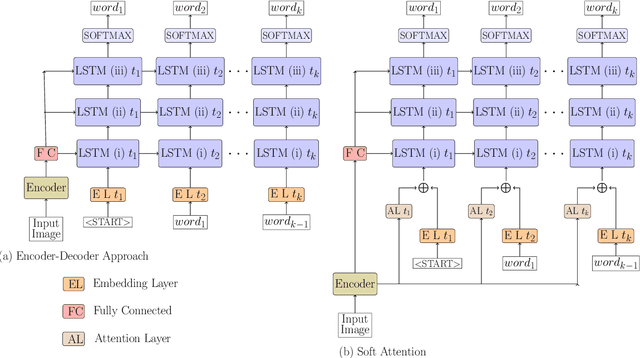
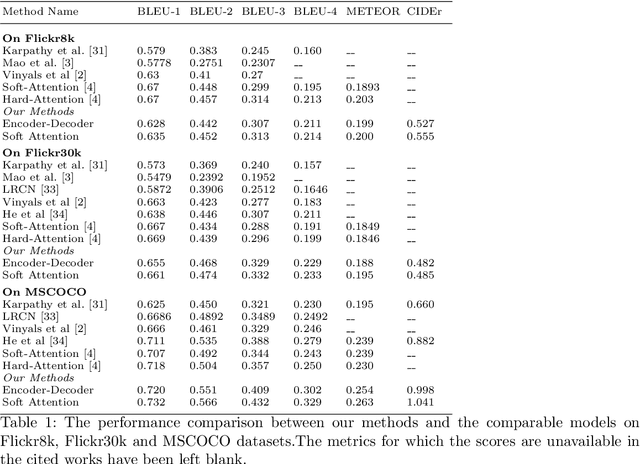
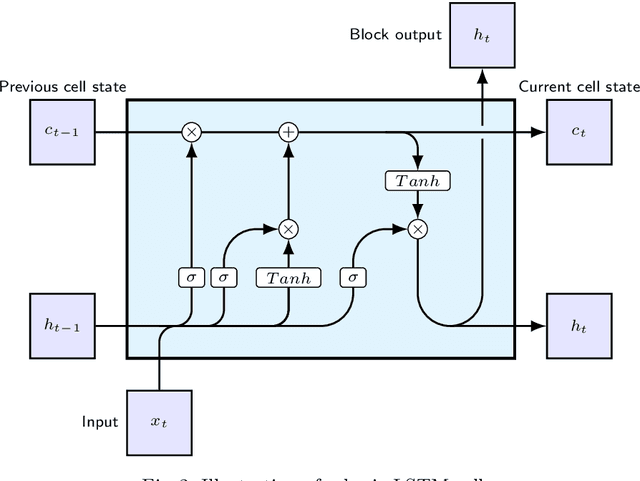

Image Captioning, or the automatic generation of descriptions for images, is one of the core problems in Computer Vision and has seen considerable progress using Deep Learning Techniques. We propose to use Inception-ResNet Convolutional Neural Network as encoder to extract features from images, Hierarchical Context based Word Embeddings for word representations and a Deep Stacked Long Short Term Memory network as decoder, in addition to using Image Data Augmentation to avoid over-fitting. For data Augmentation, we use Horizontal and Vertical Flipping in addition to Perspective Transformations on the images. We evaluate our proposed methods with two image captioning frameworks- Encoder-Decoder and Soft Attention. Evaluation on widely used metrics have shown that our approach leads to considerable improvement in model performance.