 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Synergistic Ensemble Learning: Uniting CNNs, MLP-Mixers, and Vision Transformers to Enhance Image Classification
Apr 12, 2025In recent years, Convolutional Neural Networks (CNNs), MLP-mixers, and Vision Transformers have risen to prominence as leading neural architectures in image classification. Prior research has underscored the distinct advantages of each architecture, and there is growing evidence that combining modules from different architectures can boost performance. In this study, we build upon and improve previous work exploring the complementarity between different architectures. Instead of heuristically merging modules from various architectures through trial and error, we preserve the integrity of each architecture and combine them using ensemble techniques. By maintaining the distinctiveness of each architecture, we aim to explore their inherent complementarity more deeply and with implicit isolation. This approach provides a more systematic understanding of their individual strengths. In addition to uncovering insights into architectural complementarity, we showcase the effectiveness of even basic ensemble methods that combine models from diverse architectures. These methods outperform ensembles comprised of similar architectures. Our straightforward ensemble framework serves as a foundational strategy for blending complementary architectures, offering a solid starting point for further investigations into the unique strengths and synergies among different architectures and their ensembles in image classification. A direct outcome of this work is the creation of an ensemble of classification networks that surpasses the accuracy of the previous state-of-the-art single classification network on ImageNet, setting a new benchmark, all while requiring less overall latency.
Multiple Object Tracking in Recent Times: A Literature Review
Sep 11, 2022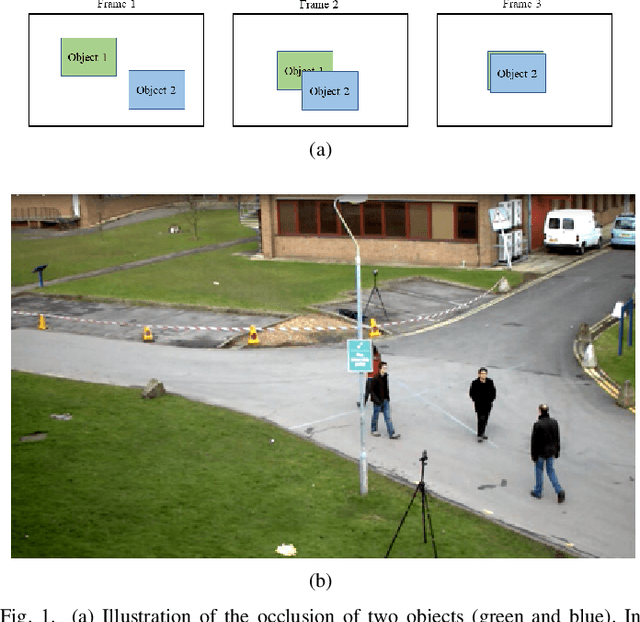
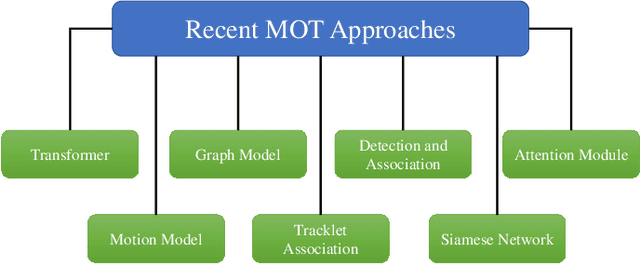
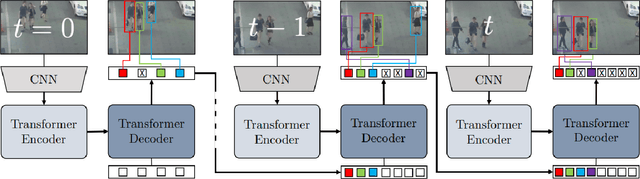
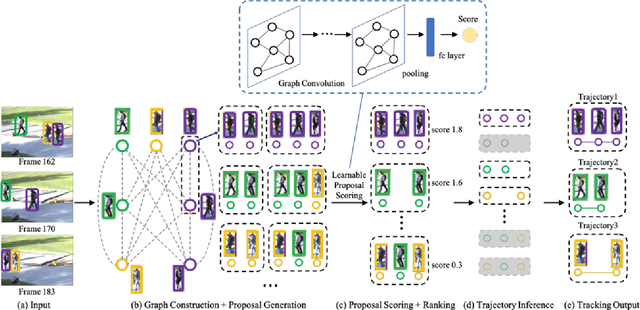
Multiple object tracking gained a lot of interest from researchers in recent years, and it has become one of the trending problems in computer vision, especially with the recent advancement of autonomous driving. MOT is one of the critical vision tasks for different issues like occlusion in crowded scenes, similar appearance, small object detection difficulty, ID switching, etc. To tackle these challenges, as researchers tried to utilize the attention mechanism of transformer, interrelation of tracklets with graph convolutional neural network, appearance similarity of objects in different frames with the siamese network, they also tried simple IOU matching based CNN network, motion prediction with LSTM. To take these scattered techniques under an umbrella, we have studied more than a hundred papers published over the last three years and have tried to extract the techniques that are more focused on by researchers in recent times to solve the problems of MOT. We have enlisted numerous applications, possibilities, and how MOT can be related to real life. Our review has tried to show the different perspectives of techniques that researchers used overtimes and give some future direction for the potential researchers. Moreover, we have included popular benchmark datasets and metrics in this review.